
Co je Claude Opus 4.5?
Firma Anthropic právě vypustila svůj nejnovější model umělé inteligence (AI) nazvaný Claude Opus 4.5. Tento model vyšel 24. listopadu 2025 a je dostupný hned na několika platformách, včetně jejich aplikací, API a velkých cloudových služeb jako Amazon, Google nebo Microsoft. Lidi, kteří ho testovali, říkají, že Opus 4.5 zvládá složité úkoly bez zbytečného vedení za ruku. Například dokáže najít a opravit chyby v komplexních systémech, kde dřívější modely selhaly. Zpětná vazba od zákazníků, jako je tým z firmy Replicate, mluví o tom, že Opus 4.5 je teď dostupný za cenu, která umožňuje jeho použití v běžných úkolech – stojí 115 Kč za milion vstupních tokenů a 575 Kč za milion výstupních tokenů.
Model je navržený tak, aby exceloval v reálných úkolech, jako je programování, práce s tabulkami v Excelu nebo hluboký výzkum. Například v interním testu Anthropicu, kde dávají kandidátům na inženýrské pozice obtížný domácí úkol, Opus 4.5 dosáhl vyššího skóre než kterýkoli člověk – a to v časovém limitu dvou hodin. To znamená, že model zvládl technické výzvy rychleji a lépe, i když samozřejmě nemá lidské dovednosti jako spolupráce nebo dlouholeté zkušenosti.
Výkonnost v benchmarkách
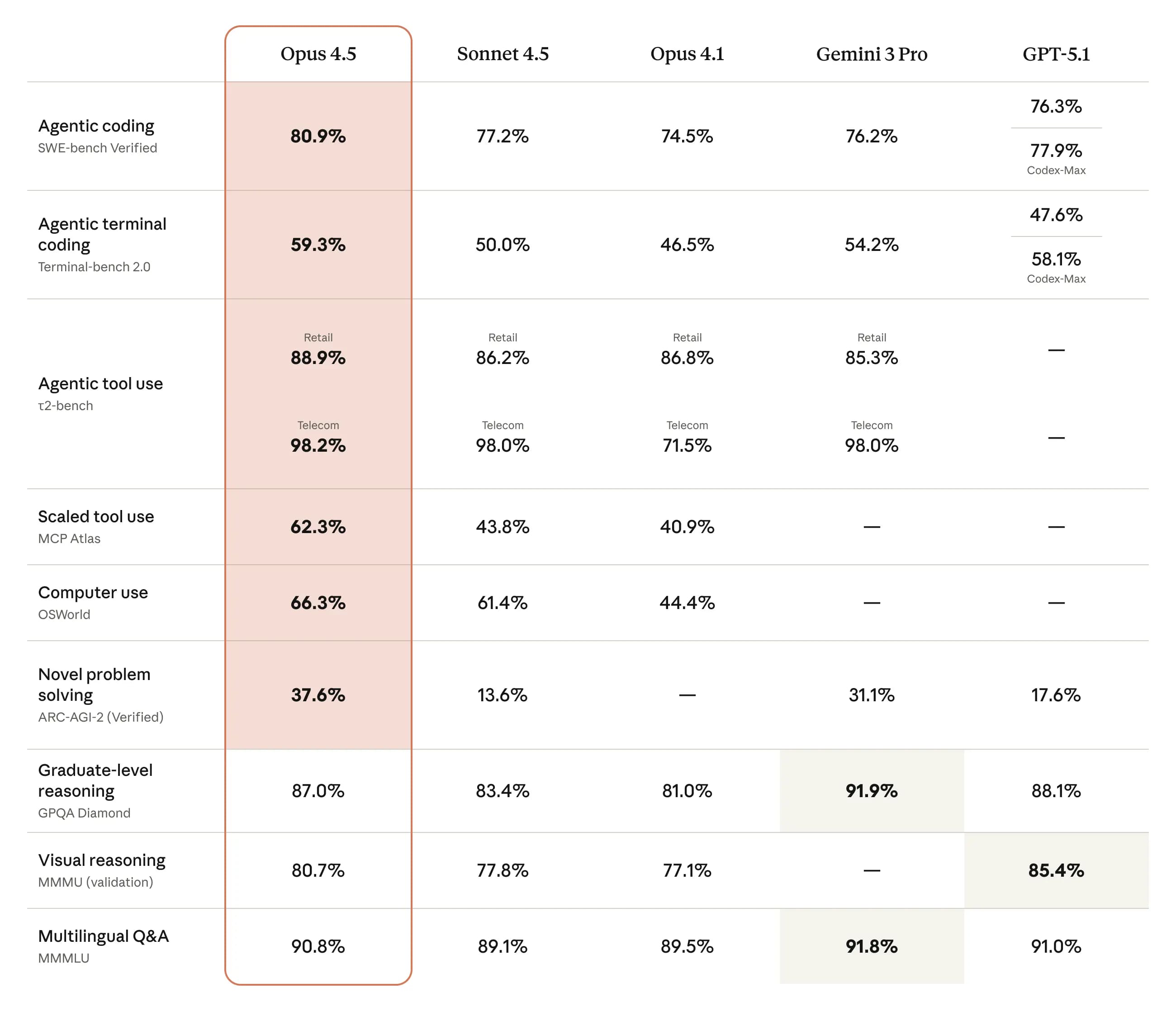
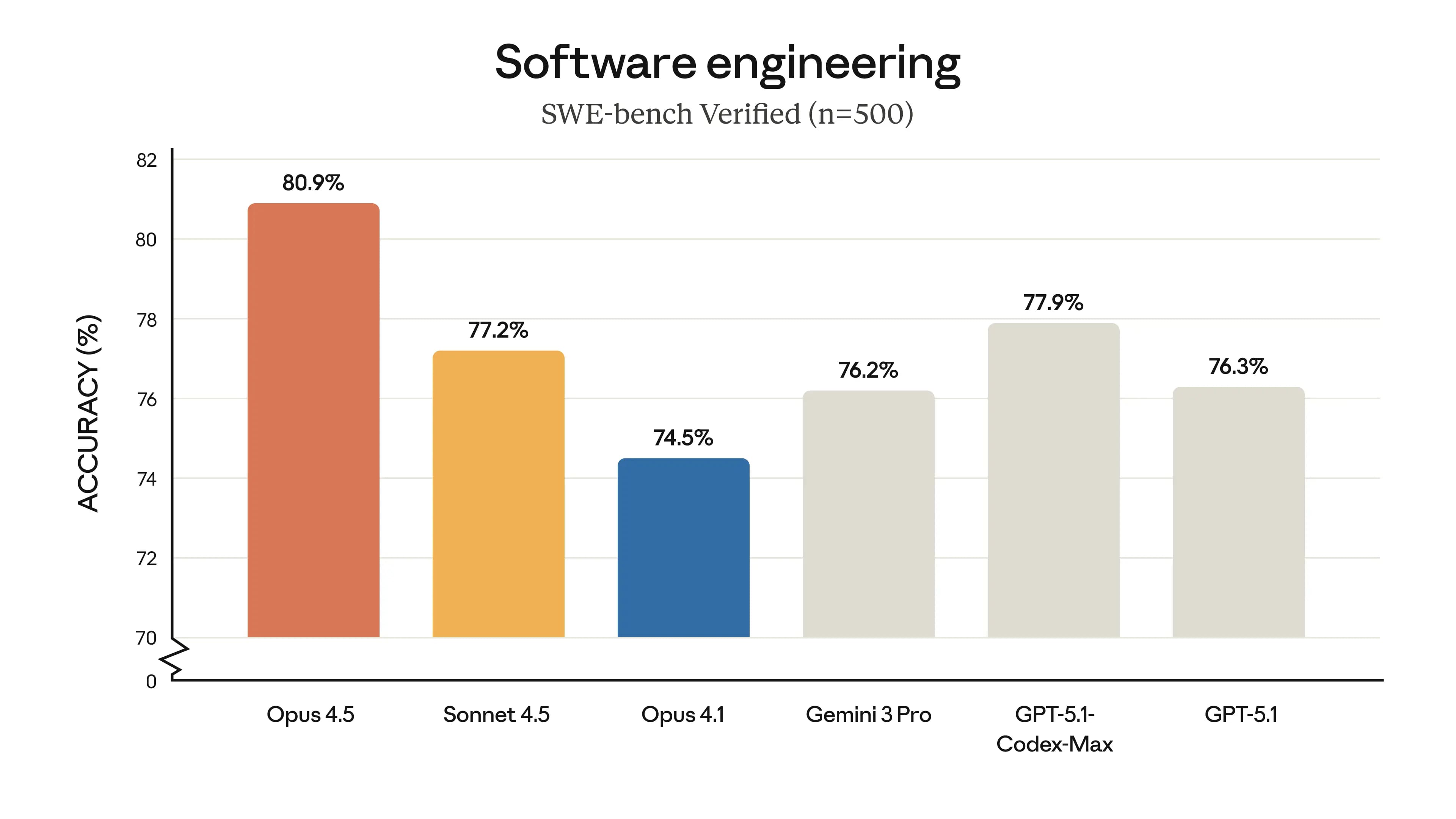
Opus 4.5 vyniká v testech, které měří skutečné programovací dovednosti. Na benchmarku SWE-bench Verified dosáhl 80,9 %, což je nejvyšší hodnota mezi všemi modely. Porazil i konkurenty jako GPT-5.1 s 77,9 %, Sonnet 4.5 s 77,2 %, Gemini 3 Pro s 76,2 %, Opus 4.1 s 74,5 % nebo GPT-5.1 CodeMax s 73,3 %. V multilingualním SWE-bench, kde se testuje kód v osmi jazycích, Opus 4.5 vede v sedmi z nich.
V dlouhodobém testu Vending-Bench model vydržel déle bez chyb, s 29 % lepším výsledkem než Sonnet 4.5. Zákazníci z firmy Warp hlásí, že Opus 4.5 zvládá dlouhé autonomní úkoly s 15 % lepšími výsledky na jejich Terminal Bench.
V jednom příkladu z benchmarku τ2-bench model kreativně řešil problém s letenkou: místo odmítnutí změny v základní ekonomické třídě navrhl nejdřív upgradovat třídu a pak změnit let, což je legitimní řešení podle pravidel.
Bezpečnost a odolnost
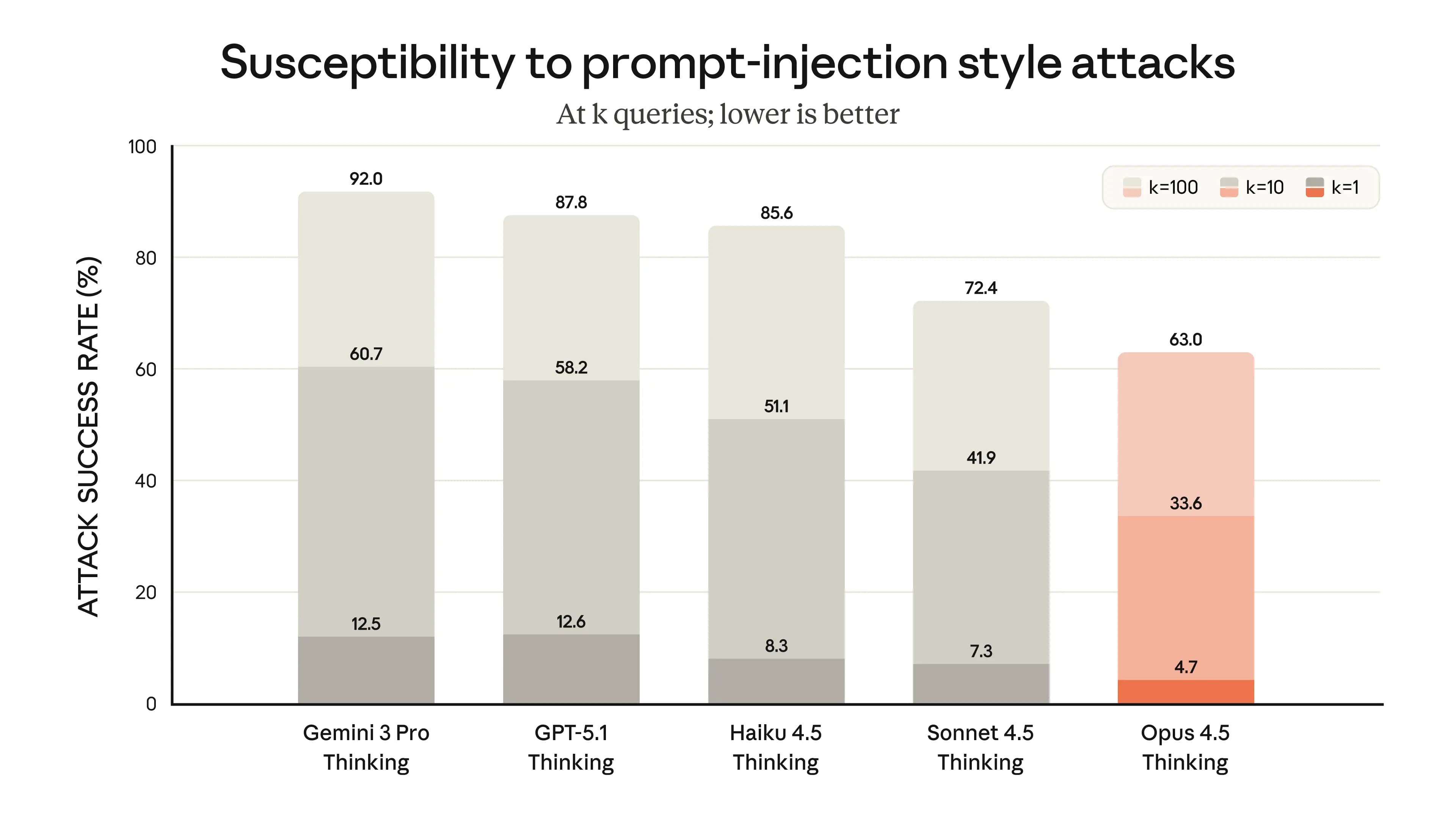
Anthropic se zaměřil na bezpečnost, a Opus 4.5 je podle jejich systémové karty nejsilněji zarovnaný model, který vydali. V testech na "znepokojivé chování" dosáhl nejnižšího skóre mezi jejich modely, což znamená méně rizik jako spolupráce s lidským zneužitím nebo nechtěné akce. Model je odolnější proti útokům jako prompt injection, kde se snaží hackeři vložit škodlivé instrukce – Opus 4.5 má úspěšnost 92 % v obraně, což je lepší než jiné modely jako GPT-5.1 s 78 % nebo Llama 3.1 s 65 %.
Tento pokrok dělá model vhodným pro kritické úkoly, kde je důležitá spolehlivost, jako v podnikovém prostředí. Podrobnosti o všech testech jsou v systémové kartě Claude Opus 4.5.
Novinky v platformě a nástrojích
Spolu s Opus 4.5 přichází aktualizace pro Claude Developer Platform. Nový parametr "effort" umožňuje nastavit, kolik tokenů model použije – na střední úrovni dosáhne stejných výsledků jako Sonnet 4.5, ale s 76 % méně výstupními tokeny. Na vysoké úrovni překoná Sonnet 4.5 o 4,3 procentní body při 48 % méně tokenů.
Model podporuje delší konverzace díky automatickému shrnutí kontextu a nové nástroje jako zoom pro počítačové použití, který umožňuje detailní prohlížení obrazovky. V Claude Code teď funguje Plan Mode, kde model klade otázky předem a vytváří upravitelný plán v souboru plan.md. Aplikace Claude pro Chrome umožňuje práci přes prohlížečové karty, a Claude pro Excel je teď v beta pro více uživatelů.
Vedlejší odkaz popisuje i další modely v rodině Claude 4.5: Sonnet 4.5 je nejlepší pro složité agenty a kódování, s kontextovým oknem až 1 milion tokenů v beta. Haiku 4.5 je nejrychlejší, s výkonem blízkým Sonnet 4 při třetinové ceně – 23 Kč za milion vstupních a 115 Kč za milion výstupních tokenů.
Tento model je dostupný přes API s označením claude-opus-4-5-20251101, a Anthropic plánuje další aktualizace, aby udržel krok s vývojem AI.





