
GDPval: OpenAI testuje, jak AI zvládá skutečnou práci a lidí
OpenAI představilo GDPval jako nový nástroj pro hodnocení výkonu umělé inteligence na úkolech, které mají skutečnou ekonomickou hodnotu. Tento benchmark se zaměřuje na 44 povolání z devíti hlavních odvětví, která přispívají nejvíc k hrubému domácímu produktu Spojených států. Mezi ně patří například zdravotnictví, finance, výroba nebo vládní sektor. Celkem zahrnuje plná sada 1320 úkolů, přičemž otevřená zlatá podmnožina obsahuje 220 úkolů. Každý úkol vychází z reálné práce profesionálů s průměrně 14 lety zkušeností, jako jsou právníci, inženýři nebo zdravotní sestry.
Úkoly nejsou jen jednoduché textové otázky. Modely musí pracovat s různými soubory, včetně tabulek, prezentací, obrázků, videí nebo zvukových nahrávek. Například v jednom úkolu z výroby musí model navrhnout zařízení pro testování kabelových cívek, přičemž vytvoří prezentaci v PowerPointu a shrnutí v PDF. Průměrná doba na splnění takového úkolu expertem je 7 hodin, s odhadovanou hodnotou kolem 9000 Kč.
Jak OpenAI vybíralo povolání a úkoly?
Odvětví byla vybrána podle dat z Federální rezervní banky v St. Louis, kde každé přispívá více než 5 % k HDP USA. V každém odvětví pak OpenAI zvolilo pět povolání s nejvyšším přínosem ke mzdám, která jsou převážně digitální. K tomu použili databázi O*NET od ministerstva práce USA, kde klasifikovali úkoly jako digitální, pokud jich bylo alespoň 60 %.
Mezi povoláními najdeme software developery, právníky, účetní, zdravotní sestry, finanční analytiky nebo redaktory. Experti, kteří úkoly vytvářeli, prošli pohovory, školením a kontrolami. Každý úkol prošel průměrně pěti koly recenzí, včetně automatické kontroly modelem a hodnocení jinými profesionály. To zajistilo, že úkoly jsou reprezentativní a kvalitní, s průměrnou obtížností 3,32 na škále od 1 do 5.
Výsledky testů: AI se přibližuje lidem
OpenAI testovalo modely jako GPT-4o, o4-mini, o3, GPT-5, Claude Opus 4.1, Gemini 2.5 Pro a Grok 4. Hodnocení probíhalo slepě, kde experti porovnávali výstupy modelů s lidskými. Claude Opus 4.1 dosáhl nejlepších výsledků, když v 47,6 % případů byl jeho výstup hodnocen stejně dobře nebo lépe než lidský. GPT-5 vynikal v přesnosti, zatímco Claude v estetice, jako je formátování dokumentů.
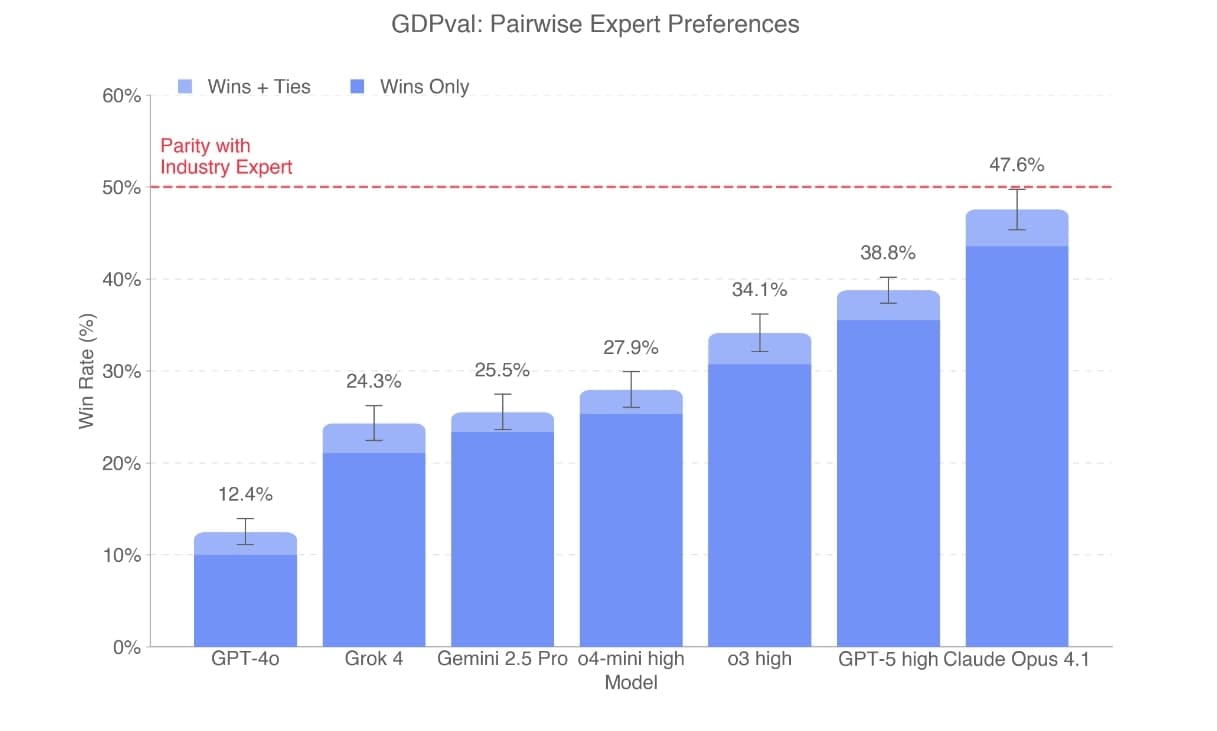
Výkon modelů roste lineárně – od GPT-4o k GPT-5 se zlepšil více než trojnásobně. Modely dokončují úkoly až 100krát rychleji a levněji než experti, s průměrnou cenou úkolu kolem 9000 Kč pro člověka. Při zapojení lidského dohledu, jako je kontrola a opravy, mohou modely ušetřit čas i peníze, například v scénáři, kde expert zkusí model několikrát a pak úkol dokončí sám.
Chyby modelů a zlepšení
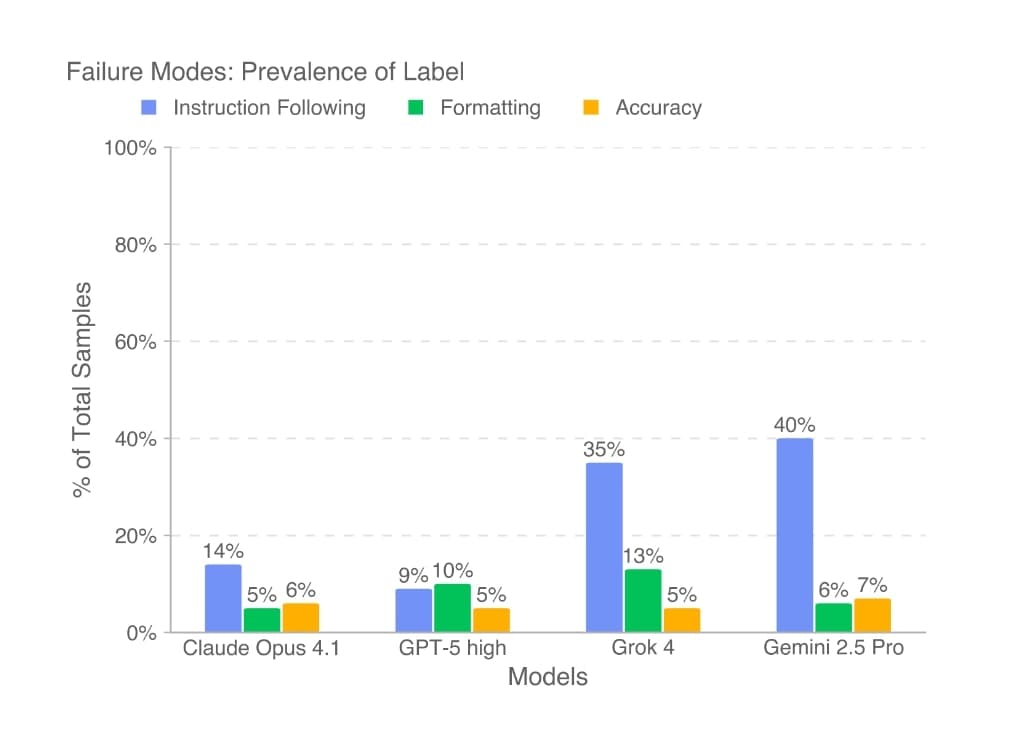
Nejčastějšími problémy modelů byly selhání v následování instrukcí, chyby ve formátování nebo halucinace dat. Například GPT-5 selhával hlavně na formátování, zatímco Gemini a Grok často ignorovaly reference nebo slibovaly výstupy, které nedodali. Zvýšení úsilí na uvažování, lepší kontext nebo scaffolding zlepšilo výsledky – například speciální prompt pro GPT-5 snížil chyby v PDF o polovinu.
OpenAI také experimentovalo s méně specifikovanými úkoly, kde modely měly méně kontextu, což vedlo k horším výsledkům, protože se snažily odhadnout potřebné informace.
Otevřené zdroje a budoucnost
OpenAI otevřelo 220 úkolů zlaté podmnožiny, včetně promptů a referenčních souborů, dostupných na evals.openai.com. Tam je i experimentální automatický hodnotitel, který dosahuje 66 % shody s lidskými experty. Tento nástroj je rychlejší, ale má limity, jako absence internetu nebo problémy s fonty.
GDPval má svá omezení – zaměřuje se na samostatné digitální úkoly, ne na interaktivní nebo fyzickou práci. Budoucí verze plánují rozšíření na více povolání, interaktivitu a složitější kontexty. OpenAI vyzývá experty a zákazníky k přispění, aby benchmark rostl společně s komunitou. Tento nástroj pomáhá sledovat pokrok AI a jeho vliv na trh práce, kde modely mohou pomáhat s rutinou a nechat lidem kreativní části.





