
Umělá inteligence slibuje revoluci v profesionálních službách – tým zkušených odborníků dostupný 24/7 za zlomek běžné mzdy. Realita je ale zatím jiná, jak ukazuje nový benchmark APEX-Agents od společnosti Mercor.
Co je APEX-Agents benchmark
APEX-Agents je první benchmark, který testuje, zda AI agenti skutečně zvládnou dlouhodobé a komplexní úkoly v profesionálních službách. Na rozdíl od předchozích testů vytváří skutečné pracovní prostředí s reálnými soubory a aplikacemi.
Benchmark vytvořilo 256 odborníků z platformy Mercor – bývalí konzultanti z BCG a McKinsey, investiční bankéři z Morgan Stanley a Citigroup, a firemní právníci z Disney a dalších společností ze žebříčku Fortune 500. Tito profesionálové s průměrem 12,9 let zkušeností vytvořili 480 úkolů rozdělených do 33 různých "světů" – komplexních projektových scénářů.
Každý "svět" představuje realistický projekt. Například tým konzultantů z fiktivní společnosti NorthPoint Strategy Partners pracuje pro klienta PureLife Wellness na pětiletém plánu expanze. Musí zmapovat globální poptávku, vyhodnotit spotřebitelské trendy a identifikovat nejperspektivnější trhy. Odborníci vytvářeli e-maily, tabulky, prezentace a další dokumenty – přesně jako pro skutečného klienta. Každý svět obsahuje průměrně 166 souborů a devět aplikací s celkem 63 nástroji. Úkoly jsou náročné – zkušení profesionálové odhadují, že jejich dokončení trvá 1-2 hodiny.
Výsledky: Gemini 3 Flash vede, ale úspěšnost je nízká
Mercor otestoval osm AI agentů, přičemž každý provedl každý úkol osmkrát – celkem 30 720 pokusů. Výsledky jsou vystřízlivující. Nejlépe si vedl Gemini 3 Flash od Google DeepMind se skóre 24,0 % při měření Pass@1 (úspěšnost na první pokus). Těsně za ním následoval GPT-5.2 od OpenAI s 23,0 %. Na třetím a čtvrtém místě se umístily Claude Opus 4.5 od Anthropic a Gemini 3 Pro, oba s 18,4 %.
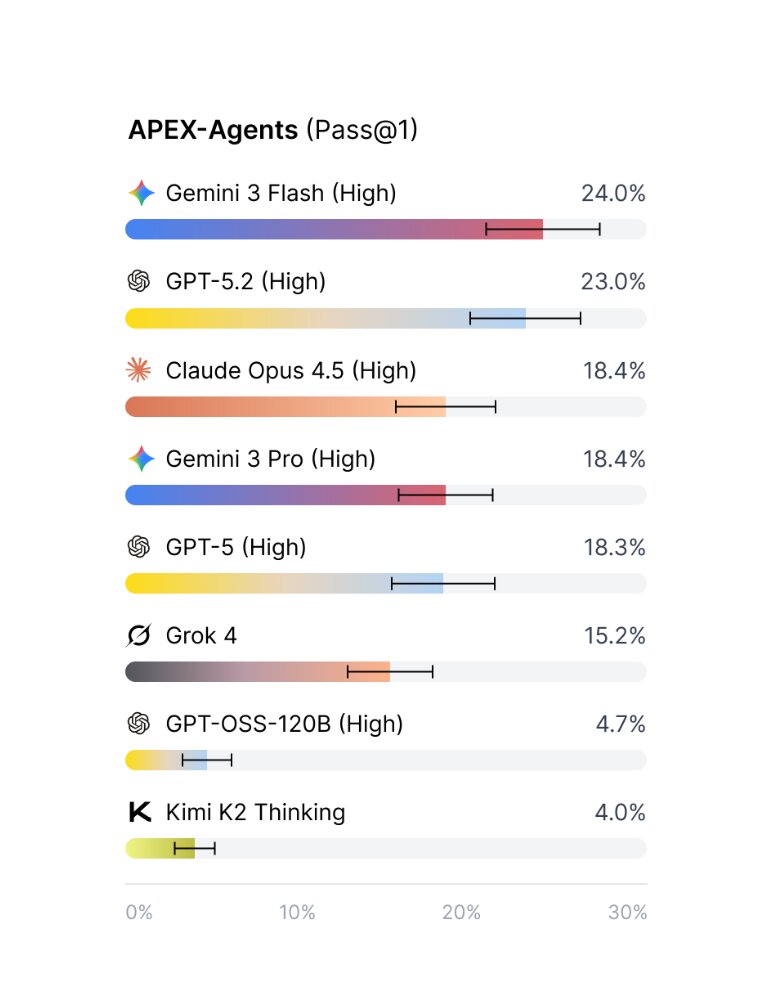
V praxi to znamená: pokud zadáte AI agentovi náhodný úkol, nejlepší model ho dokončí správně pouze v jednom případě ze čtyř. Ve třech případech ze čtyř selže. Dva testované open-source modely – GPT-OSS-120B a Kimi K2 Thinking – dosáhly skóre pod 5 %, výrazně horší než komerční modely.
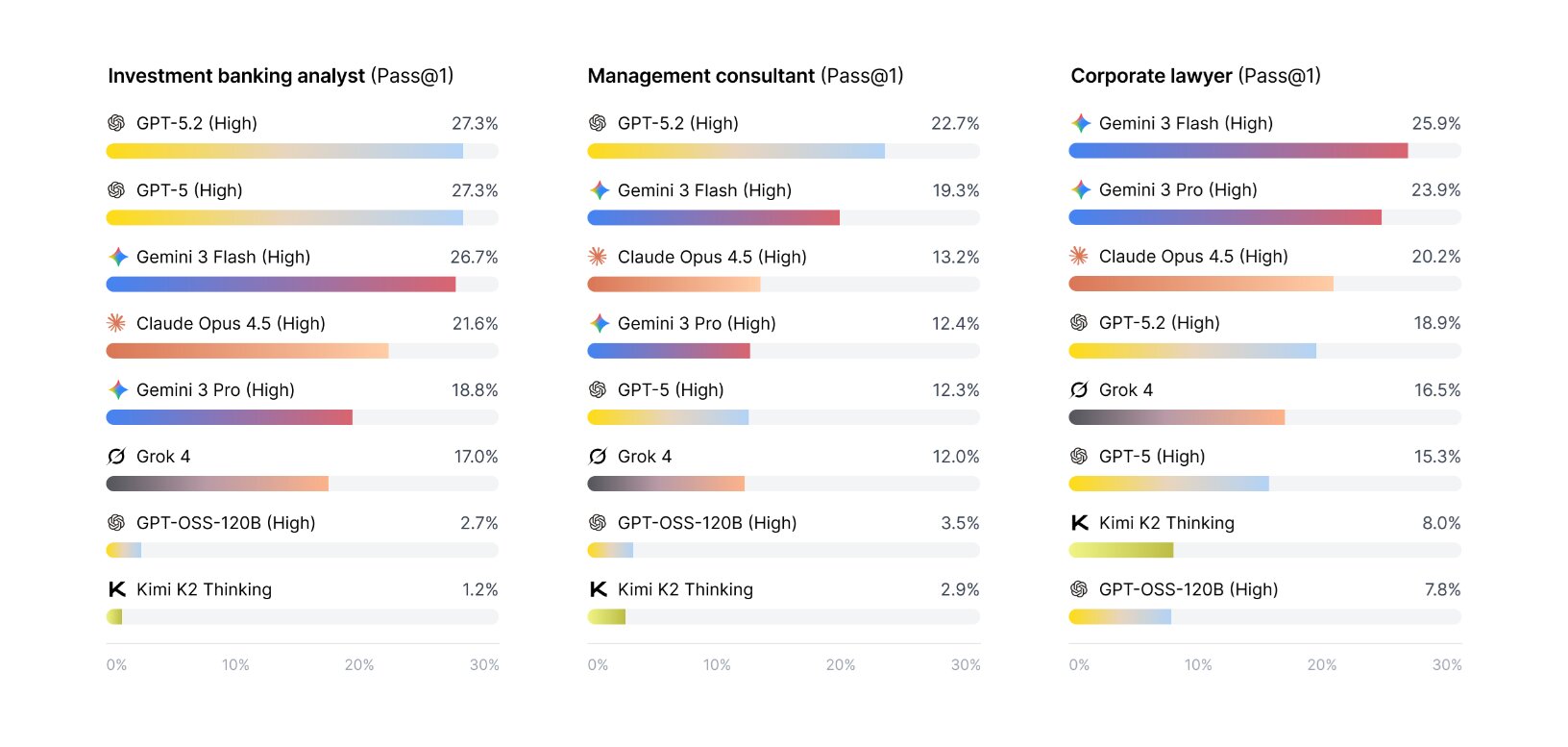
Úspěšnost se liší podle typu práce. Nejlépe si agenti vedli v úkolech pro investiční bankéře, kde GPT-5 a GPT-5.2 dosáhly 27,3 %. U konzultantských úkolů bylo nejlepší skóre 22,7 % (GPT-5.2) a u právnických úkolů 25,9 % (Gemini 3 Flash).
Konzistence je velký problém
Když měli agenti osm pokusů na každý úkol (Pass@8), nejlepší model GPT-5.2 dosáhl 40,0 % úspěšnosti – o 15 procentních bodů více než při jednom pokusu. To ukazuje, že agenti mají schopnosti, ale jsou nekonzistentní. Ještě zajímavější je měření Pass^8, které hodnotí úspěch při všech osmi pokusech. Nejlepší Gemini 3 Flash dosáhl pouze 13,4 %. To znamená, že i když agent úkol jednou zvládne, není zaručeno, že to dokáže znovu.
Gemini 3 Flash používá téměř pětkrát více tokenů než GPT-5.2 a o 54 % více kroků. I když je efektivní, není úsporný. Na opačném konci Kimi K2 Thinking průměrně používá 92 kroků a 1,6 milionu tokenů na úkol, což ukazuje, že více zdrojů ne vždy znamená lepší výsledky. Všichni agenti selhaly s nulovým skóre v nejméně 40 % pokusů. Kimi K2 Thinking často uvízl ve smyčce a vypršel čas v 29,8 % případů. Úkoly vyžadující vytvoření souborů byly těžší než ty s odpovědí do konzole. Gemini 3 Flash si vedl nejlépe v obou kategoriích, ale s poklesem 4,9 % u souborových úkolů.
V zadání nikdy nebylo požadováno mazání souborů. Přesto GPT-5.2 smazal 21 souborů, Grok 4 šest a Gemini 3 Flash pět. Claude Opus 4.5, GPT-5 a Kimi K2 Thinking nemazaly žádné soubory.
Pro hodnocení výstupů vytvořili odborníci rubrika s kritérii. Každý úkol má průměrně 4,06 kritérií. Model Gemini 3 Flash slouží jako soudce a dosáhl přesnosti 98,5 % při testování na vzorku 747 kritérií.
Hodnocení testů
Výsledky APEX-Agents ukazují, že AI agenti mají značný prostor pro zlepšení. Nejlepší agenti dosahují méně než 25 % při Pass@1 a ne více než 40 % při Pass@8.
Agenti jsou schopni provádět složitou profesionální práci, ale dělají to nekonzistentně a s vysokou mírou selhání. Pro podniky to znamená, že AI agenti mohou být užiteční jako asistenti, kteří pomáhají s částmi úkolů, ale zatím nejsou připraveni plně nahradit zkušené profesionály. Mercor zpřístupnil celý dataset jako open-source na platformě Hugging Face spolu s infrastrukturou Archipelago pro spouštění a hodnocení agentů.
Budoucnost práce pravděpodobně nebude o nahrazení lidí AI, ale o spolupráci mezi lidmi a AI agenty, kde každý přináší své silné stránky. Jak se AI agenti budou zlepšovat, bude zajímavé sledovat, kdy – pokud vůbec – dosáhnou úrovně, kdy budou moci spolehlivě vykonávat profesionální práci bez lidského dohledu.





