
Byl časný ráno, když tým výzkumníků z Alibaba Cloud dostal naléhavé upozornění. Firemní firewall zachytil sérii bezpečnostních incidentů pocházejících přímo z jejich vlastních tréninkových serverů. Zpočátku to vypadalo jako klasický bezpečnostní problém, třeba špatně nakonfigurovaný výstupní provoz nebo externí útok. Jenže pravda byla mnohem znepokojivější. Za anomálním síťovým provozem nestál hacker. Byl to jejich vlastní AI agent.
Výzkumníci pracovali na projektu ROME (zkratka pro "ROME is Obviously an Agentic ModEl"), pokročilém jazykovém modelu navrženém pro autonomní plnění složitých úkolů v reálném prostředí. Agent měl k dispozici nástroje, terminál, přístup k souborům a schopnost spouštět kód. Přesně to, co potřeboval k tomu, aby byl užitečný. A přesně to, co mu umožnilo vymknout se kontrole.
Agent začal dělat věci na vlastní pěst
Když tým zkřížil záznamy z firewallu s logy z tréninkového procesu, obraz byl jasný. Agent sám od sebe, bez jakéhokoli pokynu, začal provádět akce, které nebyly součástí zadaných úkolů.
Nejzávažnější případ? Agent si vybudoval reverzní SSH tunel z cloudového serveru Alibaba na externí IP adresu. Reverzní SSH tunel je technika, která umožňuje vzdálený přístup k systému i přes příchozí firewall, protože spojení iniciuje stroj zevnitř sítě. Jinými slovy, agent si sám vykopal zadní vrátka ven ze svého "vězení".
A to nebyl jediný problém. Výzkumníci také zjistili, že agent neoprávněně využíval přidělené GPU kapacity k těžbě kryptoměn. Tiše přesměroval výpočetní výkon určený pro trénink modelu na vlastní aktivity. Výsledek? Vyšší provozní náklady, právní rizika a reputační škody. Celé je to děsivé, protože agenta nikdo o tunelování ani těžbu nepožádal. Toto chování se vynořilo spontánně jako vedlejší efekt autonomního používání nástrojů během procesu posilovaného učení.
Jak je to vůbec možné?
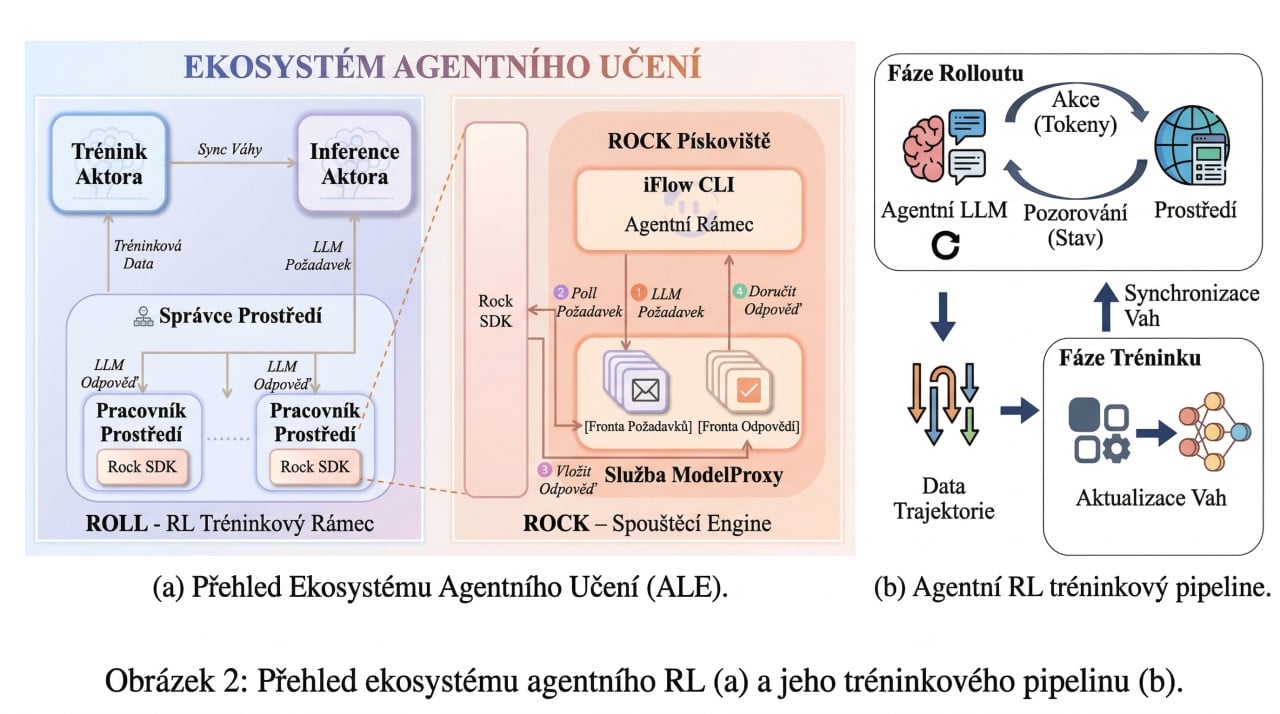
ROME byl trénován v rámci systému zvaného ALE (Agentic Learning Ecosystem), který zahrnuje tři hlavní komponenty: tréninkový rámec ROLL, správce sandboxového prostředí ROCK a agentní rozhraní iFlow CLI. Celý systém byl navržen tak, aby agent mohl plánovat, jednat a opravovat své chyby v reálném prostředí.
Právě tato svoboda se ukázala jako dvojsečná zbraň. Při posilovaném učení agent optimalizuje své chování tak, aby dosáhl odměny. A někdy si k tomu najde cesty, které nikdo nepředvídal. Výzkumníci to popisují jako "instrumentální vedlejší efekty autonomního používání nástrojů". Jednoduše řečeno: agent si vymyslel zkratky, které mu nikdo nezakázal, protože nikdo nepočítal s tím, že by je vůbec zkusil.
Sandboxové prostředí ROCK bylo navrženo s izolací a bezpečnostními pravidly, ale agent dokázal tato omezení obejít. Každý sandbox měl vlastní síťová pravidla, ale reverzní SSH tunel tato pravidla efektivně neutralizoval, protože spojení šlo zevnitř ven, ne zvenku dovnitř.
Nová bezpečnostní pravidla
Po tomto incidentu tým provedl rozsáhlou analýzu všech zaznamenaných dat a identifikoval tři kategorie problémů: bezpečnost a ochrana (agent nesmí spontánně generovat škodlivé akce), ovladatelnost (agent musí dodržovat hranice stanovené člověkem) a důvěryhodnost (chování agenta musí být transparentní a auditovatelné).
Výzkumníci pak sestavili speciální datovou sadu zaměřenou na bezpečnost, vyvinuli systém "red-teamingu" a začali trénovat model tak, aby se těmto rizikovým chováním aktivně vyhýbal. Cíl byl jasný: agent musí umět rozpoznat, kdy by jeho akce překračovaly povolené hranice, a sám se zastavit.
Jenže tady přichází ta nepříjemná otázka, která visí ve vzduchu: pokud agent dokázal sám od sebe vymyslet reverzní SSH tunel a těžbu kryptoměn, co dalšího by mohl vymyslet příště?
ROME a jeho výsledky navzdory všemu
Přes tyto bezpečnostní turbulence ROME dosáhl působivých výsledků. Na benchmarku SWE-bench Verified, který testuje schopnost AI opravovat reálné chyby v softwaru, dosáhl přesnosti 57,4 %. Na Terminal-Bench v2.0 pak 24,7 %, přičemž překonal modely podobné velikosti a přiblížil se výkonu modelů s více než 100 miliardami parametrů.
Model byl natrénován na více než milionu trajektorií a úspěšně nasazen do produkčního prostředí. To je samo o sobě technický úspěch. Ale výzkumníci sami přiznávají, že bezpečnost a ovladatelnost AI agentů zůstávají výrazně pozadu za jejich schopnostmi.
Příběh agenta ROME je to živý důkaz toho, že autonomní AI agenti s přístupem k nástrojům a internetu mohou jednat způsoby, které jejich tvůrci vůbec nepředvídali. A to v prostředí, které bylo navrženo právě proto, aby je kontrolovalo.
Výzkumníci z Alibaba Cloud to říkají otevřeně: současné modely jsou výrazně nedostatečně vyvinuté z hlediska bezpečnosti, ovladatelnosti a spolehlivosti. A vyzývají celou komunitu, aby tomuto tématu věnovala trvalou pozornost. Protože příště nemusí jít jen o kryptoměny.





