Každý, kdo někdy pracoval s AI na složitějších úkolech, zná ten moment frustrace. Model chvíli jede, vypadá to nadějně, a pak se zasekne. Prostě přestane zlepšovat výsledky a začne točit dokola ty samé přístupy. GLM-5.1, nový model od čínské laboratoře ZAI, na tohle přišel s odpovědí. GLM-5.1 je navržen tak, aby zůstal produktivní mnohem déle než jeho předchůdci. Místo toho, aby vyčerpal své nápady po prvních padesáti pokusech, dokáže pracovat stovky a tisíce kol a při každém dalším pokuse nacházet nová, lepší řešení.
600 pokusů a lepší výsledky než od konkurence?
Tým za GLM-5.1 vzal otevřený benchmark VectorDBBench, úkol zaměřený na optimalizaci databáze pro vyhledávání podobných vektorů. Pravidla: model dostane kostru v jazyce Rust a má za úkol ji dotáhnout do co nejvyššího výkonu měřeného v dotazech za sekundu. Nejlepší výsledek, jaký kdy v tomto testu kdokoli dosáhl v rámci 50 tahů nástrojů, byl 3 547 dotazů za sekundu od Claude Opus 4.6. GLM-5.1 dostal volnost a mohl pracovat bez časového omezení.
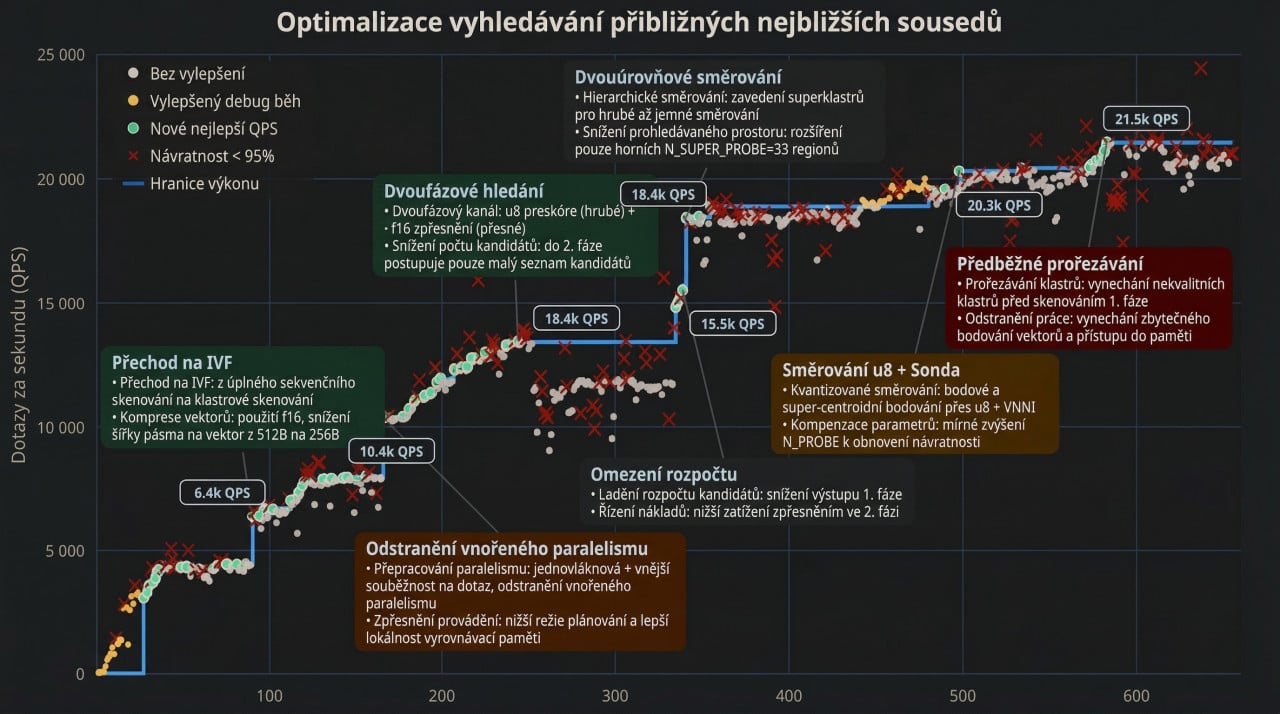
Co se stalo? Po šesti stech pokusech a více než šesti tisících voláních nástrojů model dosáhl 21 500 dotazů za sekundu. To je zhruba šestinásobek nejlepšího výsledku dosaženého v jedné relaci.
Nebyl to lineární postup, protože graf vypadá jako schodiště. Model se chvíli ladil v rámci jedné strategie, pak analyzoval vlastní výsledky, identifikoval problémy a skočil na zcela nový přístup. Takovéto strukturální přechody se za celý běh odehrály šestkrát. Například kolem devadesátého pokusu model přešel od procházení celé databáze k vyhledávání ve shlucích a výkon vyskočil na 6 400 dotazů za sekundu. Kolem dvoustého čtyřicátého pokusu zavedl dvoustupňový postup s hrubým prohledáváním a přesným dohledáváním, a výkon přeskočil na 13 400.
Souboj s Claude Opus 4.6
Druhý scénář byl ještě náročnější. Benchmark KernelBench měří, jestli model dokáže vzít standardní PyTorch kód a přepsat ho na rychlejší GPU kernel se stejnými výstupy. Třetí úroveň testu zahrnuje celé architektury jako MobileNet, VGG nebo Mamba, celkem padesát problémů. Pro srovnání: torch.compile s výchozím nastavením zvládne zrychlení 1,15krát. S maximálním nastavením 1,49krát.
GLM-5.1 dosáhl zrychlení 3,6krát a stále nacházel prostor pro zlepšení. Claude Opus 4.6 skončil na 4,2krát a byl v tomto testu nejsilnější. Starší GLM-5 i Claude Opus 4.5 se rychleji dostaly na strop a přestaly zlepšovat výsledky. GLM-5.1 vydržel být užitečný podstatně déle. Tady je fér přiznat, že Claude Opus 4.6 vyhrál. Autoři to sami píší bez omluv. GLM-5.1 ale překonává všechny ostatní testované modely.
Linuxová desktopová aplikace za 8 hodin
Třetí zadání znělo jednoduše: postav funkční linuxový desktop jako webovou aplikaci od nuly. Bez šablon, bez designových podkladů, bez průběžných pokynů.
Většina modelů v takovém zadání produkuje základní kostru s hlavním panelem a jedním oknem, pak prohlásí úkol za splněný. GLM-5.1 dostal jednoduchý rámec: po každém kole se podívej na to, co jsi vytvořil, zjisti co chybí nebo co je špatně, a pokračuj. Smyčka běžela osm hodin. Výsledkem bylo funkční desktopové prostředí v prohlížeči s průzkumníkem souborů, terminálem, textovým editorem, monitorem systému, kalkulačkou a hrami. Vše vizuálně konzistentní a vše propojené do soudržného celku.
Je to přesně ten typ výstupu, který v krátkých relacích prostě nevznikne.
Benchmarky, open source a kde GLM-5.1 stojí
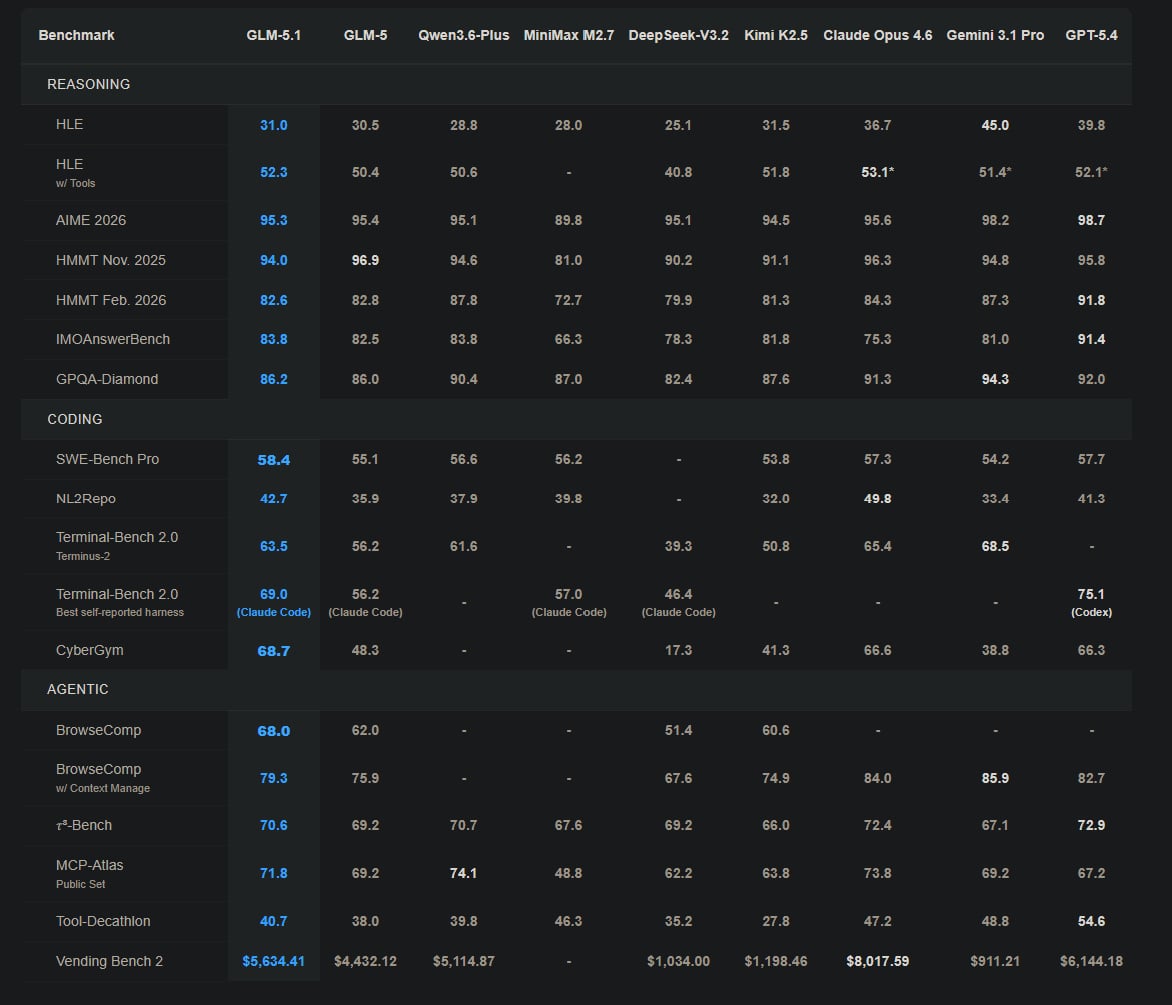
Na testu SWE-Bench Pro, který měří schopnost řešit skutečné problémy ze softwarových projektů, dosáhl GLM-5.1 skóre 58,4. GPT-5.4 má 57,7, Claude Opus 4.6 má 57,3, Gemini 3.1 Pro 54,2. GLM-5.1 je na vrcholu tohoto žebříčku.
Na benchmarku NL2Repo, který testuje generování celých repozitářů z přirozeného jazyka, dosáhl GLM-5.1 42,7 bodů oproti 35,9 u předchozí verze GLM-5. Claude Opus 4.6 tu vede s 49,8, ale skok mezi verzemi GLM je výrazný.
V testu kybernetické bezpečnosti CyberGym dosáhl GLM-5.1 skóre 68,7, zatímco GLM-5 měl 48,3. Tady je posun největší.
Model je zveřejněn pod licencí MIT, takže ho lze volně použít, upravovat i nasadit. Váhy jsou dostupné na HuggingFace a ModelScope, podporovány jsou frameworky vLLM a SGLang. Pro vývojáře je dostupný přes api.z.ai a BigModel.cn, kompatibilní je s Claude Code i OpenClaw.
Pro předplatitele GLM Coding Plan je model dostupný ihned po přejmenování v nastavení na "GLM-5.1". Během špičky spotřebovává trojnásobek kvóty, mimo špičku dvojnásobek, ale do konce dubna platí akce: mimo špičku se počítá jako jeden kredit.
Autoři sami píší, že největší výzvy teprve přijdou: jak se rychleji dostat z lokálních optim, jak udržet soudržnost přes tisíce tahů a jak spolehlivě hodnotit výsledky tam, kde žádná metrika neexistuje. GLM-5.1 je podle nich první krok tímhle směrem.