
GPT-5 dosahuje superlidských výsledků v medicíně
Představte si svět, kde umělá inteligence nejen pomáhá lékařům, ale v některých testech je přímo překonává. To není sci-fi, ale realita podle nové studie z Emory University. Tato práce, publikovaná na arXiv, zkoumá schopnosti modelu GPT-5 od OpenAI v oblasti multimodálního medicínského uvažování. Autoři studie – Shansong Wang, Mingzhe Hu, Qiang Li a další z Department of Radiation Oncology na Winship Cancer Institute – testovali model na různých benchmarkách a porovnávali ho s předchozí verzí GPT-4o i s lidskými experty. Výsledky jsou ohromující a ukazují, jak rychle se AI vyvíjí. Pojďme se na to podívat podrobněji.
Jak probíhalo testování GPT-5
GPT-5 je nejnovější velký jazykový model od OpenAI, který dokáže zpracovávat nejen text, ale i obrázky, jako jsou medicínské snímky. Studie ho hodnotila v zero-shot režimu s chain-of-thought (řetězu myšlenek) přístupem, což znamená, že model musel uvažovat krok za krokem bez předchozího tréninku na specifických datech. Testy probíhaly na datasetu MedQA, který obsahuje otázky z amerických lékařských licenčních zkoušek, na MMLU v medicínských podkategorích, na USMLE self-assessment zkouškách a na multimodálních benchmarkách jako MedXpertQA a VQA-RAD. Pro multimodální úlohy model dostával textové popisy pacientů společně s obrázky, například CT snímky, a musel na základě toho diagnostikovat.
V jednom konkrétním případě z MedXpertQA model správně identifikoval Boerhaave syndrom – vzácné prasknutí jícnu – na základě kombinace laboratorních hodnot, jako je hemoglobin 9 g/dL, průměrný objem červených krvinek 120 μm³, a fyzikálních příznaků jako suprasternální krepitus a krvavé zvracení. Model navrhl jako další krok Gastrografin swallow, což je test s kontrastní látkou, a vysvětlil, proč ostatní možnosti, jako ondansetron nebo injekce epinefrinu, nejsou vhodné.
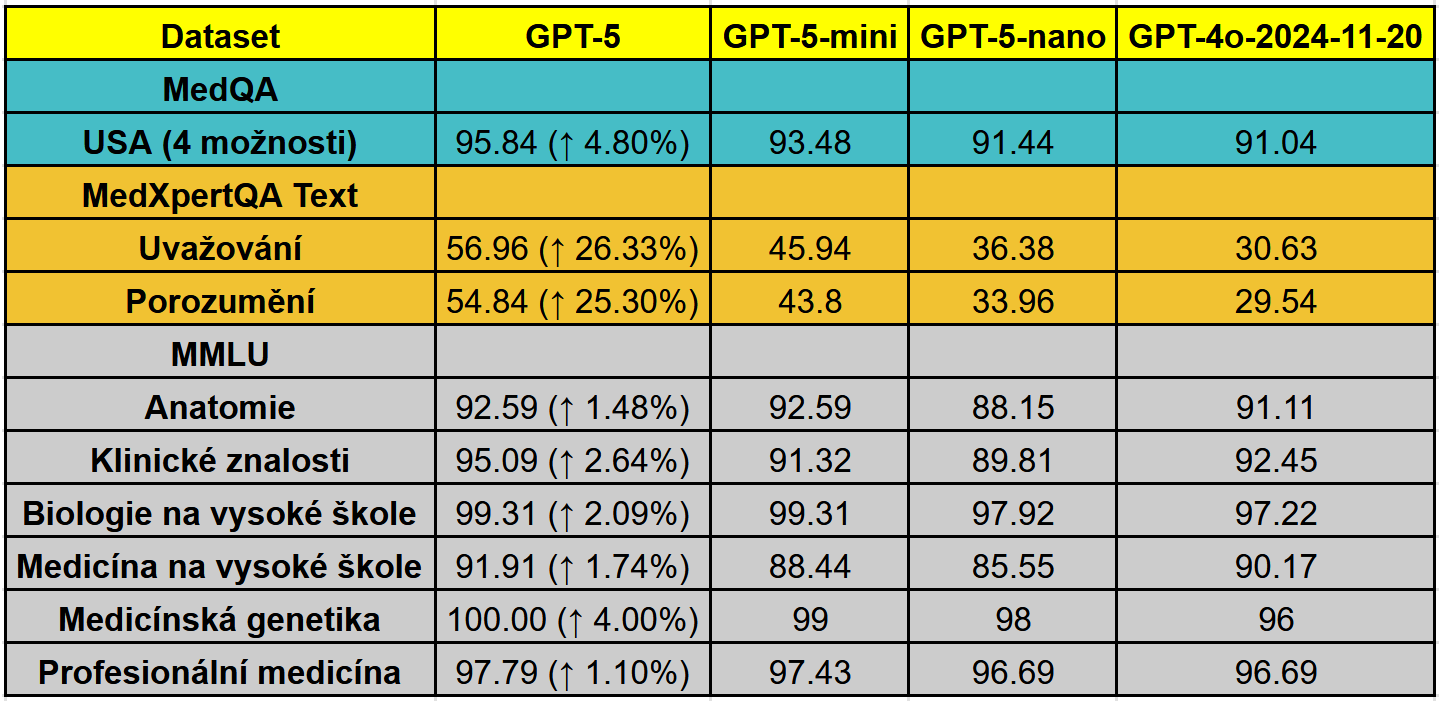
Výsledky benchmarků
Na textovém benchmarku MedQA (verze s 4 možnostmi odpovědí) dosáhl GPT-5 přesnosti 95,84 %, což je o 4,80 % lepší než GPT-4o-2024-11-20, který měl 91,04 %. V MedXpertQA Text model vylepšil skóre v uvažování o 26,33 % na 56,96 % a v porozumění o 25,30 % na 54,84 %. Na MMLU v medicínských oborech, jako je anatomie (92,59 %), klinické znalosti (95,09 %) nebo medicínská genetika (100 %), překonal předchozí model o 1–4 %.
Na USMLE self-assessment zkouškách, které zahrnují otázky ze Step 1, Step 2 a Step 3, dosáhl GPT-5 průměrného skóre 95,22 %, s největším zlepšením v Step 2 (97,50 %, +4,17 % oproti GPT-4o). To je výrazně nad úrovní, kterou potřebují lidští lékaři k úspěšnému složení zkoušek.
V multimodálních testech na MedXpertQA MM model exceloval s 69,99 % v uvažování (+29,26 % oproti GPT-4o) a 74,37 % v porozumění (+26,18 %). Na VQA-RAD, který se zaměřuje na radiologické obrázky, dosáhl 70,92 %, což je mírně méně než menší varianta GPT-5-mini, ale stále solidní. Tyto výsledky ukazují, jak GPT-5 dokáže integrovat textové údaje, jako vitální znaky (např. krevní tlak 90/63 mmHg, tep 130/min) s vizuálními daty z obrázků.
Srovnání s lidskými experty
Nejdramatičtější je porovnání s lékaři před získáním licence, jako jsou studenti nebo internisté. V MedXpertQA Text překonal GPT-5 tyto experty o 15,22 % v uvažování a 9,40 % v porozumění. V multimodálním MedXpertQA MM to bylo ještě výraznější: +24,23 % v uvažování a +29,40 % v porozumění. Naopak GPT-4o zůstával pod úrovní těchto expertů v většině kategorií.
Podle tweetu od Dr. Derya Unutmaz, který sdílel tyto výsledky, to naznačuje posun: Zatímco GPT-4o byl na úrovni lidí, GPT-5 je nad nimi. To vyvolává otázky, zda brzy nebude považováno za nedbalost, pokud lékaři nebudou AI v klinické praxi používat. Studie zdůrazňuje, že GPT-5 přináší pokrok v integraci heterogenních dat, jako jsou pacientské historie, strukturované údaje a obrázky, což by mohlo vést k lepším klinickým rozhodnutím.
Tato studie z Emory University ukazuje, že GPT-5 je skokem vpřed v medicínském AI. S výsledky, které překonávají lidské experty v kontrolovaných testech, se otevírá cesta k systémům podpory rozhodování v nemocnicích. Autoři uvolnili kód na GPT-5-Evaluation pro další výzkum. Samozřejmě, reálný svět medicíny je složitější než benchmarky, ale směr je jasný – AI jako GPT-5 se stává nepostradatelným nástrojem.





