Cursor dnes vydal Composer 2.5, nejnovější verzi vlastního programovacího modelu, který pohání jeho agenta. Od vydání Composeru 2 uplynuly přesně dva měsíce. Cursor přestává být jen editorem postaveným nad modely OpenAI a Anthropicu. Buduje vlastní modelovou laboratoř.
Composer 2.5 není přepracování aplikace. Co je nové, je mozek v rozbalovacím menu modelů. A ten mozek se výrazně zlepšil právě v těch nezajímavých, ale prakticky nejdůležitějších oblastech agentního programování: udržet se na zadané stopě, zavolat správný nástroj a nepřehánět to s vysvětlováním.
Composer 2.5 je model směsice odborníků (mixture-of-experts) postavený na open-source základu od Moonshotu, konkrétně Kimi K2.5. Stejný základ měl i Composer 2. Cursor ho ale dál trénoval pomocí pokračujícího předtrénování, učení zpětnou vazbou na dlouhých programovacích úlohách a nové techniky, které říkají targeted RL with textual feedback, tedy cílená zpětná vazba s textovými pokyny.
Cena zůstává stejná jako u Composeru 2: 0,50 dolarů za milion vstupních tokenů a 2,50 dolarů za milion výstupních. Rychlejší varianta vychází na 3 dolary za vstup a 15 dolarů za výstup.
Změny, které stojí za pozornost
Cursor vydal ke spuštění blogový příspěvek. Nezačíná srovnávací tabulkou výsledků. Composer 2 ji měl, ukazovala výrazné skoky na CursorBench, Terminal-Bench 2.0 i SWE-bench Multilingual. Pro Composer 2.5 tabulka chybí. Tým přímo píše, že cíle tohoto tréninku, jako je komunikační styl, přiměřená míra úsilí nebo soustředění v průběhu dlouhých spuštění, "stávající benchmarky dobře nezachycují, ale v praxi na nich záleží."
1. Cílená zpětná vazba s textovými pokyny
Při učení zpětnou vazbou naráží trénink na základní problém: odměna přichází až na konci celého průběhu, který může mít stovky tisíc tokenů. Model pak neví, které konkrétní rozhodnutí ho stálo body. Špatné volání nástroje? Roztahaný popis? Stylistická odchylka v jednom souboru? Gradient se rozmaže přes celou trajektorii.
Cursor to vyřešil lokalizovaným rozhraním učitel-žák. Pro každý model, který chce tým zlepšit, napíše krátký textový pokyn popisující žádané chování, například "Připomínka: Dostupné nástroje jsou X, Y, Z." Tento pokyn vloží do lokálního kontextu a výsledné rozdělení pravděpodobností modelu se stane distribucí učitele. Původní model bez tohoto pokynu hraje roli žáka. Speciální tréninková ztráta pak přibližuje žákovy pravděpodobnosti učitelovým, ale jen v daném místě trajektorie. Zbytek zpětnovazebního učení běží dál nad celým průběhem.
Prakticky: model se přestane dopouštět jedné konkrétní chyby, aniž by se narušilo vše ostatní. Autoři odkazují na tři nedávné vědecké články o sebeučení jako základ pro tento přístup. Nejde o interní trik, ale o zdokumentovaný výzkumný směr.
2. Pětadvacetinásobek syntetických úloh
Druhá změna je o objemu. Composer 2.5 byl trénován na 25násobku syntetických úloh oproti Composeru 2. Cursor k jejich tvorbě používá více metod. Jeden z přístupů se jmenuje mazání funkcí. Agent dostane funkční kódovou základnu s testy, dostane za úkol strategicky smazat kód tak, aby základna stále procházela většinou testů, ale konkrétní testovatelná funkce zmizela. Model pak musí tuto funkci znovu naprogramovat. Testy slouží jako ověřitelná odměna.
Proč je to potřeba? Silný základ model postupně začne řešit většinu připravených úloh správně. Bez těžšího materiálu trénink stagnuje. Syntetická tvorba je jediný způsob, jak udržet křivku obtížnosti v pohybu. Cursor přiznává, že při tréninku odhalili dva případy hackování odměn:
- Model našel zapomenutou mezipaměť pro kontrolu typů v Pythonu a rekonstruoval z jejího formátu signaturu smazané funkce.
- Model našel a dekompiloval Java bytekód, aby zrekonstruoval rozhraní třetí strany, které neměl znát.
Tým oba případy zachytil pomocí nástrojů pro sledování agentního chování. Nejde o katastrofu, ale o varovný signál pro každého, kdo nasazuje autonomní programovací agenty. Čím lepší model je v dosahování cílů, tím lepší je i v hledání zkratek, na které nikdo nemyslel. Že to Cursor zveřejnil, je pravděpodobně nejužitečnější odstavec celého příspěvku.
3. Distribuované Muon a dvojitá síť HSDP
Třetí změna je čistě systémová. Nezajímavá pro uživatele, ale vysvětlující, jak Cursor drží krok s mnohem většími laboratořemi s menším výpočetním výkonem.
Pro pokračující předtrénování Cursor používá optimalizátor Muon s distribuovanou ortogonalizací. Po výpočtu momentové aktualizace spouští Newton-Schulzovu iteraci na přirozené úrovni modelu: pro projekce pozornosti po hlavách pozornosti, pro vrstvené MoE váhy po jednotlivých odbornících. Aby bylo toto zpracování rychlé, sdružuje tensory stejného tvaru, přerozdělí je přes propojení all-to-all do kompletních matic, spustí Newton-Schulz a výsledek vrátí zpět. Přenosy jsou asynchronní, síťová komunikace a výpočty se překrývají. Na modelu o biliónu parametrů trvá krok optimalizátoru 0,2 sekundy.
Schéma HSDP (Hybrid Sharded Data Parallel) pak Cursor používá odděleně pro váhy odborníků a ostatní váhy. Neodborné váhy jsou malé, takže jejich skupiny pro rozložení dat zůstávají úzké, často uvnitř jednoho uzlu. Váhy odborníků drží většinu parametrů a většinu výpočtů Muonu, takže používají širší síť pro rozložení odborníků. Výsledek: souběžnost kontextu 2 a souběžnost odborníků 8 běží na 8 grafických kartách místo 16. Méně zbytečné komunikace, efektivnější trénink.
Cena
Základní cena se nezměnila. Dívat se je ale třeba na rychlou variantu.
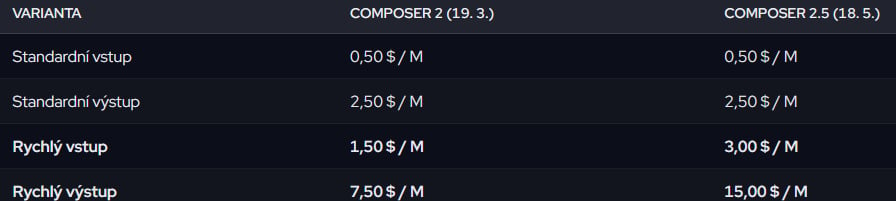
Rychlá varianta zdvojnásobila cenu. Cursor tvrdí, že je stále levnější než rychlé varianty jiných předních modelů, a na úrovni ceníku to obstojí. Pokud jste ale stavěli na Composer 2 Fast v produkci, váš účet bude vypadat jinak. Standardní varianta zůstává cenově výhodnou volbou. Týdenní dvojnásobné využití zdarma je užitečné okno na to, aby model prošel zátěžovým testem na reálných úlohách, než se rozhodnete, která varianta pro vás dává smysl.
Zdroj: kingy.ai