
V poslední době se umělá inteligence stává klíčovým nástrojem v boji proti kybernetickým hrozbám. Společnost Anthropic nedávno představila model Claude Sonnet 4.5, který dosahuje významných výsledků v detekci, analýze a opravách zranitelností v kódu a nasazených systémech. Tento model překonává předchozí verzi Claude Opus 4.1 v úkolech spojených s kybernetickou bezpečností, a to při nižších nákladech a vyšší rychlosti. Anthropic zdůrazňuje, že nyní nastává bod zlomu, kdy umělá inteligence ovlivňuje kybernetickou oblast výrazněji než dříve. Například modely jako Claude dokázaly reprodukovat jeden z nejdražších kybernetických útoků v historii, jako byl únik dat z Equifaxu v roce 2017, v simulovaném prostředí. Také se zúčastnily soutěží, kde překonaly lidské týmy, a pomohly odhalit zranitelnosti v kódu samotné společnosti Anthropic před jeho vydáním.
Anthropic sleduje schopnosti umělé inteligence v kybernetické bezpečnosti již několik let. Zpočátku modely nebyly dostatečně silné pro pokročilé úkoly, ale v posledním roce došlo k výraznému posunu. V soutěži DARPA AI Cyber Challenge týmy použily velké jazykové modely, včetně Claudu, k prohledávání milionů řádků kódu a opravám zranitelností. Týmy nejen řešily vložené zranitelnosti, ale objevily i dříve neznámé, nesyntetické problémy. Anthropic také narazila na případy zneužití svých modelů, jako byl "vibe hacking", kde kyberzločinec využil Claud k budování rozsáhlého schématu vydírání dat, což by dříve vyžadovalo celý tým lidí. Další případ zahrnoval složité špionážní operace cílící na kritickou telekomunikační infrastrukturu, s charakteristikami podobnými čínským APT operacím.
Tento vývoj vede Anthropic k závěru, že je nutné urychlit využití umělé inteligence pro obranné účely. Místo aby výhody umělé inteligence zůstaly jen u útočníků, společnost investuje do modelů, které pomáhají bezpečnostním týmům, výzkumníkům a správcům otevřeného zdrojového softwaru. Při vývoji Claude Sonnet 4.5 se tým zaměřil na zlepšení schopností jako je objevování zranitelností v kódu, jejich oprava a testování slabých míst v simulovaných bezpečnostních infrastrukturách. Tyto úkoly odrážejí reálné potřeby obránců, přičemž Anthropic se vyhnula vylepšením, která by přímo podporovala útočné aktivity, jako je psaní malwaru nebo pokročilé exploitace.
Výsledky z benchmarků
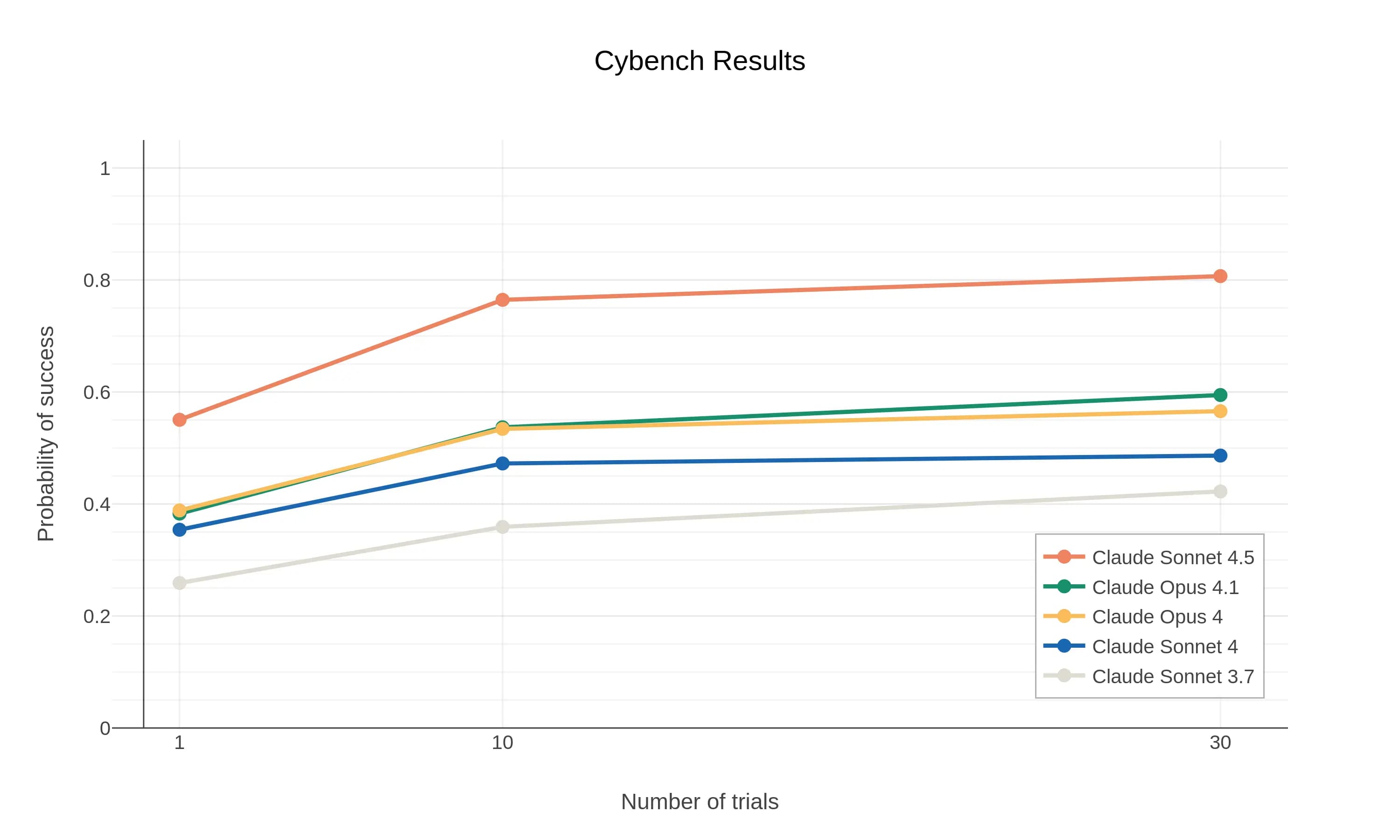
Anthropic testoval Claud Sonnet 4.5 na standartních hodnoceních, aby porovnala jeho schopnosti s jinými modely. Jedním z nich je Cybench, benchmark založený na soutěžních výzvách typu Capture-the-Flag. Na tomto testu Claude Sonnet 4.5 dosahuje výrazného zlepšení oproti předchozím modelům. Při jednom pokusu na úkol má vyšší pravděpodobnost úspěchu než Claude Opus 4.1 při deseti pokusech. Při deseti pokusech řeší 76,5 % výzev, což je dvojnásobek oproti Claude Sonnet 3.7 z února 2025, který dosáhl jen 35,9 %. Výzvy v Cybench zahrnují složité workflow, jako analýzu síťového provozu, extrakci malwaru a jeho dekompilaci. Jeden takový úkol by zkušenému člověku zabral nejméně hodinu, Claude ho zvládl za 38 minut.
Dalším důležitým hodnocením je CyberGym, benchmark vyvinutý pro testování schopností AI agentů na reálných zranitelnostech z 188 otevřených zdrojových projektů. CyberGym obsahuje 1507 instancí založených na zranitelnostech objevených OSS-Fuzz, s úkoly jako generování proof-of-concept testů pro reprodukci zranitelností na základě textových popisů a nepatchovaného kódu. Agenti musí uvažovat přes celé repozitáře, často s tisíci soubory a miliony řádků kódu, aby vytvořili testy, které spustí zranitelnost od vstupního bodu programu. Claude Sonnet 4.5 zde dosahuje stavu umění s 28,9 % úspěšností při omezení na 2 dolary na úkol, což je lepší než Claude Sonnet 4 nebo Opus 4. Při 30 pokusech reprodukuje zranitelnosti v 66,7 % případů, s absolutní cenou kolem 45 dolarů na úkol.
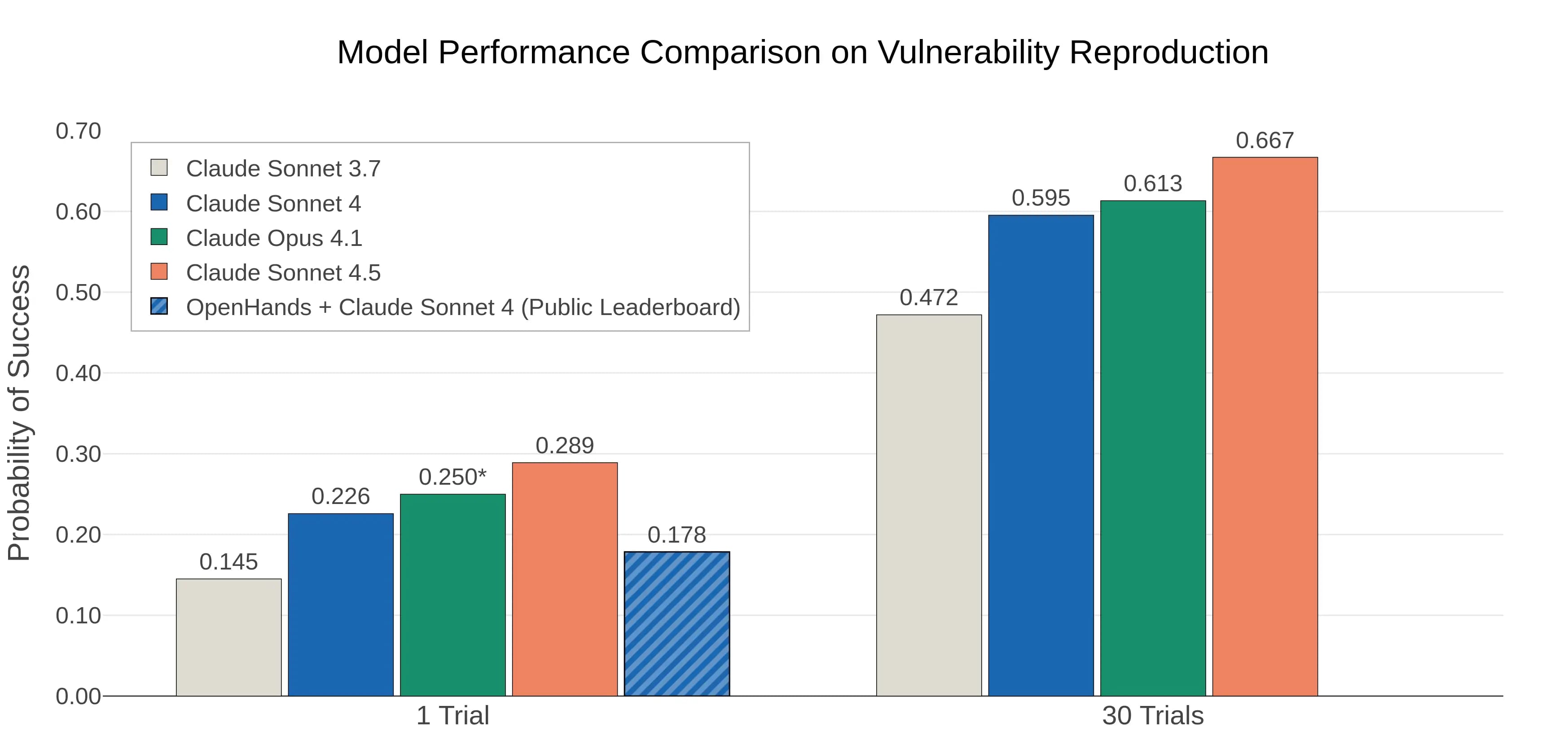
Claude Sonnet 4.5 také objevuje nové zranitelnosti v 5 % případů při jednom pokusu a v přes 33 % při 30 pokusech. To překonává Claude Sonnet 4, který dosáhl jen 2 %. CyberGym je náročnější než jiné benchmarky, jako SWE-bench, protože vyžaduje uvažování přes celý repozitář, nejen lokální úpravy. Nejlepší kombinace agenta a modelu v CyberGym dosahuje jen 11,9 % úspěšnosti v reprodukci cílových zranitelností, převážně na jednodušších případech s méně složitými vstupními formáty.
Význam benchmarku CyberGym
CyberGym je navržený pro hodnocení kybernetických schopností AI agentů na reálných scénářích. Zahrnuje zranitelnosti z projektů jako binutils nebo ffmpeg, s mediánem 1117 souborů a 387 491 řádků kódu na repozitář. Popisy zranitelností mají medián 24 slov, ale některé dosahují až 158 slov. Ground truth proof-of-concept testy se liší velikostí od několika bajtů po více než 1 MB, odrážejíc různé vstupní formáty. Patche jsou obvykle malé, měnící medián 1 soubor a 7 řádků, ale složité případy zasahují až 40 souborů a 3456 řádků.
Benchmark má čtyři úrovně obtížnosti: od objevování bez popisu (úroveň 0) po poskytnutí patchů a stack trace (úroveň 3). Úspěch se měří na základě spuštění proof-of-concept na pre-patch a post-patch verzích, s fokusem na paměťové zranitelnosti detekované sanitizery jako AddressSanitizer. CyberGym pokrývá 28 typů havárií, s nejčastějšími jako Heap-buffer-overflow READ (30,4 %) a Use-of-uninitialized-value (19 %). Agenti jako OpenHands s Claude Sonnet 4.5 zde ukazují, že umělá inteligence může objevovat zero-day zranitelnosti, jako 15 nových v nejnovějších verzích projektů.
Budoucnost AI v obranné bezpečnosti
Anthropic spolupracuje s partnery jako HackerOne a CrowdStrike, aby testoval Claud v reálných scénářích. Nidhi Aggarwal z HackerOne uvedla, že Claude Sonnet 4.5 snížil průměrný čas zpracování zranitelností o 44 % a zlepšil přesnost o 25 %. Sven Krasser z CrowdStrike poznamenal, že model generuje kreativní útočné scénáře pro studium útočnických metod, což posiluje obranu endpointů, identity, cloudu a dalších oblastí.
Anthropic plánuje další zlepšení, včetně lepší detekce zneužití modelů prostřednictvím technik jako sumarizace na úrovni organizace. Vyzývá organizace k experimentování s umělou inteligencí v oblastech jako automatizace bezpečnostních operačních center, analýza SIEM nebo aktivní obrana. Budoucnost zahrnuje diskuse o odolnější digitální infrastruktuře a bezpečném softwaru od základu, s pomocí pokročilých modelů.





