
Společnost Anthropic 5. února 2026 představila Claude Opus 4.6, nejnovější verzi svého nejvýkonnějšího AI modelu. Nový model přináší výrazná vylepšení v oblasti programování, dlouhodobých agentic úkolů a práce s rozsáhlými databázemi kódu. Poprvé v historii modelů třídy Opus nabízí kontextové okno o velikosti 1 milion tokenů v beta verzi.
Vylepšené schopnosti v programování
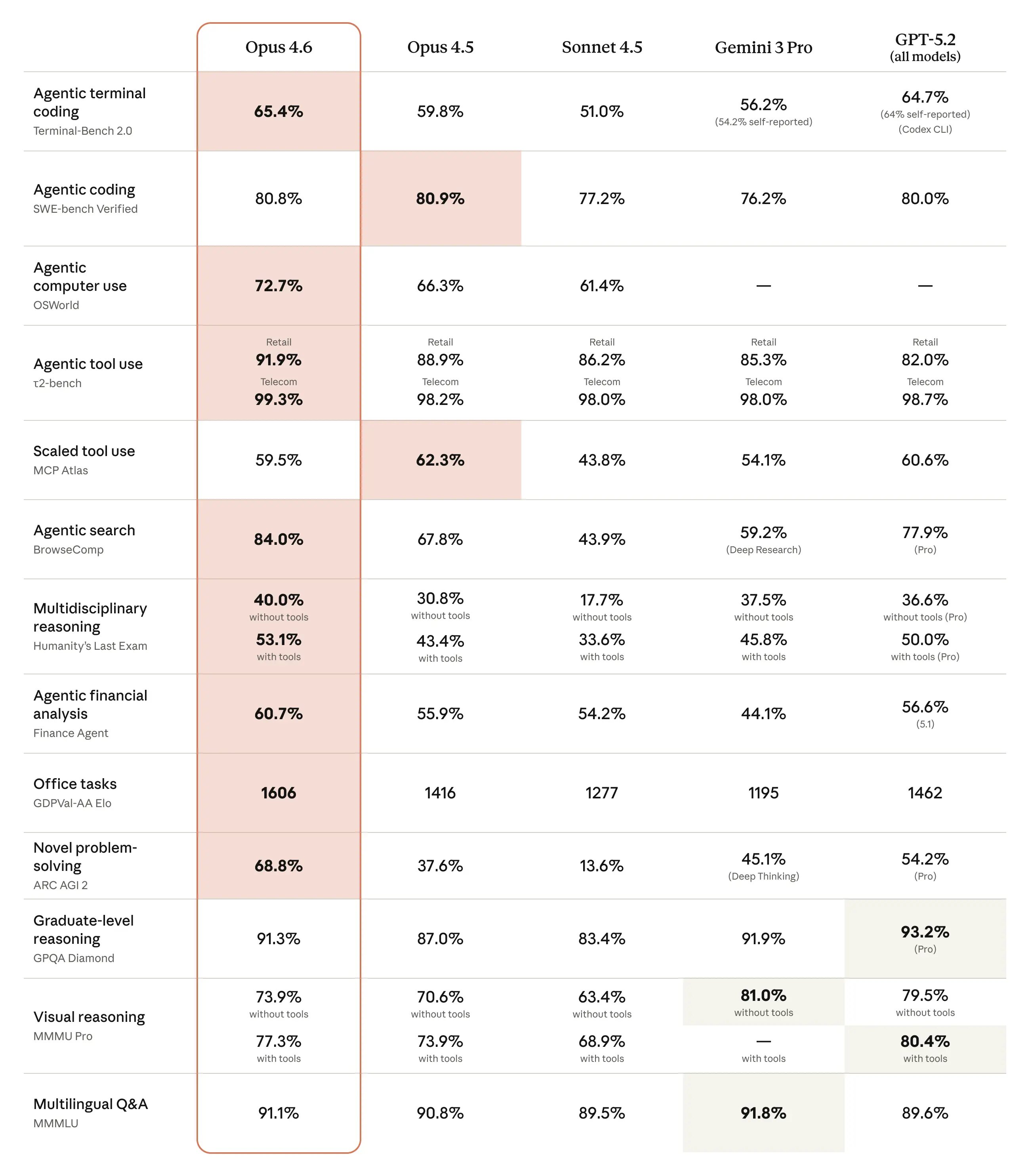
Claude Opus 4.6 vyniká především v oblasti kódování. Model pečlivěji plánuje, dokáže udržet agentic úkoly po delší dobu a spolehlivěji pracuje ve větších databázích kódu. Nově disponuje lepšími schopnostmi v oblasti code review a debuggingu, což mu umožňuje zachytit vlastní chyby. Model dosáhl nejvyššího skóre v hodnocení Terminal-Bench 2.0, které testuje agentic kódování.
Podle společnosti GitHub model zvládá složité vícekrokové programátorské úkoly, které vývojáři řeší každý den, zejména agentic workflow vyžadující plánování a volání nástrojů. Společnost Replit potvrdila, že Opus 4.6 představuje obrovský skok v agentic plánování – rozkládá složité úkoly na nezávislé podúkoly, spouští nástroje a subagenty paralelně a identifikuje překážky s vysokou přesností.
Dominuje v testech výkonu
Opus 4.6 zaujímá první místo v Artificial Analysis Intelligence Index, syntetické metriky zahrnující 10 hodnocení pokrývajících schopnosti včetně agentic úkolů, programování a vědeckého uvažování. Model vyhrává ve třech evaluacích: GDPval-AA (agentic úkoly v reálném světě), TerminalBench (agentic kódování a použití terminálu) a CritPT (fyzikální problémy na výzkumné úrovni).
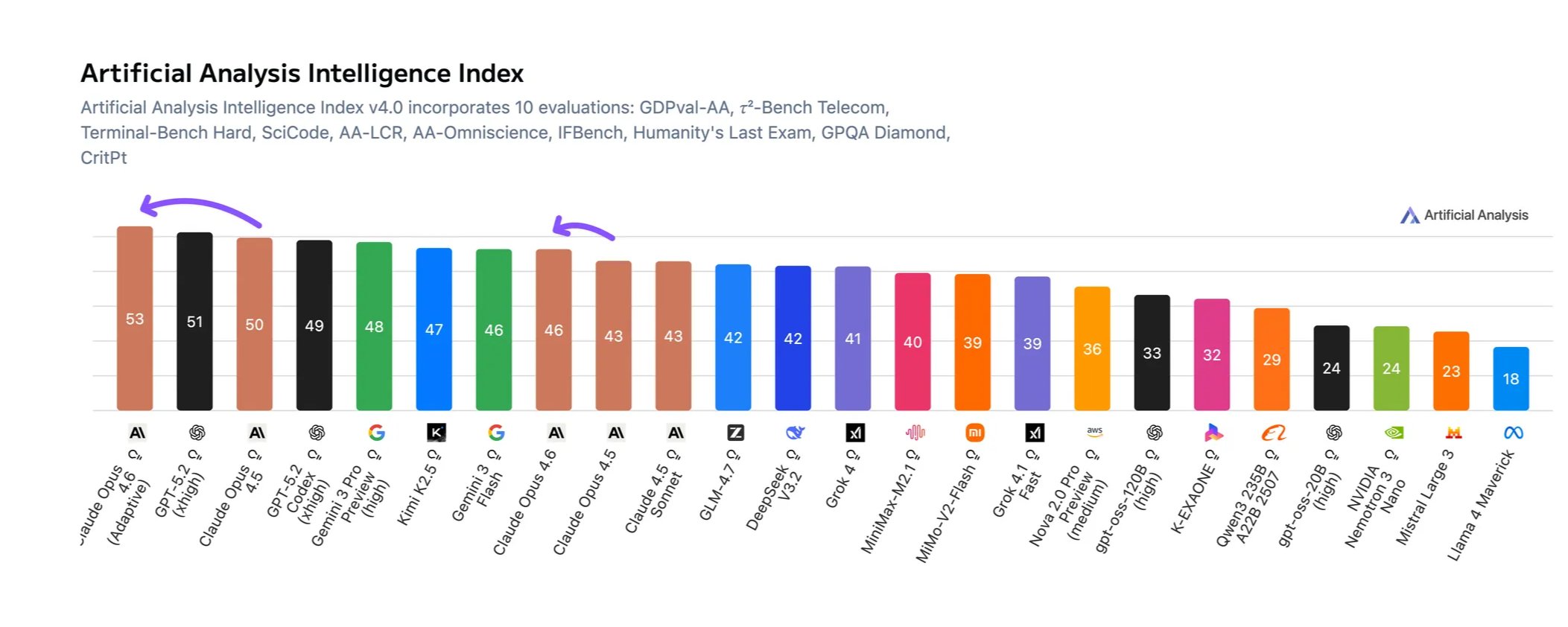
V testu GDPval-AA, který měří výkon modelů při znalostních pracovních úkolech od přípravy prezentací přes analýzu dat až po úpravu videa, Opus 4.6 předčil GPT-5.2 od OpenAI přibližně o 144 Elo bodů a svého předchůdce Claude Opus 4.5 o 190 bodů. Model také dosáhl nejlepšího výkonu v testu BrowseComp, který měří schopnost modelu najít těžko dostupné informace online.
Na testu Humanity's Last Exam, složitém multidisciplinárním testu uvažování, Opus 4.6 vede všechny ostatní špičkové modely. V oblasti vědeckého myšlení dosáhl model nejvyššího skóre 13 % na CritPT, evaluaci sestávající z nepublikovaných fyzikálních problémů na výzkumné úrovni.
Práce s dlouhým kontextem
Opus 4.6 výrazně zlepšil schopnost získávat relevantní informace z velkých sad dokumentů. Na benchmarku MRCR v2 (varianta 8-needle 1M), který testuje schopnost modelu najít informace "skryté" v obrovském množství textu, dosáhl Opus 4.6 skóre 76 %, zatímco Sonnet 4.5 pouze 18,5 %. Jedná se o kvalitativní posun v tom, kolik kontextu může model skutečně využít při zachování špičkového výkonu.
Běžnou stížností na AI modely je "context rot" (rozpad kontextu), kdy se výkon zhoršuje, jakmile konverzace překročí určitý počet tokenů. Opus 4.6 v tomto ohledu funguje výrazně lépe než jeho předchůdci.
Nové funkce a možnosti
Anthropic představil několik klíčových změn spolu s vydáním Opus 4.6. Model zavádí nový režim "adaptive thinking" (adaptivní myšlení), který nahrazuje předchozí režim "extended thinking". Místo nastavování rozpočtu pro myšlenkové tokeny mohou vývojáři nyní kontrolovat myšlení modelu pomocí nastavení "effort" (úsilí) se čtyřmi úrovněmi: nízká, střední, vysoká a maximální.
Maximální výstupní limit tokenů se ve srovnání s Opus 4.5 zdvojnásobil ze 64 000 na 128 000 tokenů. Model také podporuje novou funkci context compaction (komprese kontextu) v beta verzi, která automaticky shrnuje a nahrazuje starší kontext, když se konverzace blíží konfigurovatelné hranici.
Cena a dostupnost
Claude Opus 4.6 je k dispozici na platformě claude.ai, přes API společnosti Anthropic a na všech hlavních cloudových platformách včetně Google Cloud Vertex, AWS Bedrock a Microsoft Azure. Cena zůstává stejná jako u Opus 4.5: 125 Kč za milion vstupních tokenů a 625 Kč za milion výstupních tokenů.
Podle analýzy Artificial Analysis stálo spuštění Intelligence Index s modelem Opus 4.6 v režimu adaptivního myšlení s maximálním úsilím 62 150 Kč (2 486 dolarů), což je více než u GPT-5.2 (xhigh) od OpenAI, který stál 57 600 Kč (2 304 dolarů). Model však použil výrazně méně tokenů než konkurence – 58 milionů výstupních tokenů, což je přibližně dvojnásobek Opus 4.5, ale výrazně méně než GPT-5.2 s xhigh reasoning effort (130 milionů).
Bezpečnost a spolehlivost
Podle rozsáhlé systémové karty společnosti Anthropic vykazuje Opus 4.6 celkový bezpečnostní profil stejně dobrý nebo lepší než jakýkoli jiný špičkový model v odvětví, s nízkými mírami nesprávného chování napříč bezpečnostními evaluacemi. Model také vykazuje nejnižší míru odmítnutí (over-refusals) ze všech nedávných modelů Claude, kdy model nedokáže odpovědět na neškodné dotazy.
Společnost Notion uvedla, že Opus 4.6 je nejsilnější model, který Anthropic vydal. Bere složité požadavky a skutečně je dokončuje, rozděluje je na konkrétní kroky, provádí je a vytváří vybroušenou práci, i když je úkol ambiciózní. Společnost Asana potvrdila, že Opus 4.6 je nejlepší model, který dosud testovali, s výjimečnými schopnostmi uvažování a plánování.





