
Velké jazykové modely (LLM) se staly součástí našeho každodenního života. Pomáhají psát texty, generovat kód nebo dokonce řešit složité úkoly. Ale co když vám řeknu, že tyto modely mají obrovský problém s něčím tak základním, jako je sčítání čísel? Wes McKinney, autor blogu, se na to podíval podrobně a jeho zjištění jsou překvapivá. Všechno začalo, když Wes experimentoval s nástroji Claude Code od firmy Anthropic. Zjistil, že i ty nejmodernější modely selhávají při jednoduchých matematických operacích, což zpochybňuje myšlenku, že umělá obecná inteligence (AGI) je hned za rohem.
Wes popisuje svou cestu s AI nástroji. Až do března letošního roku byl skeptický vůči pomoci AI při programování. Celou svou kariéru od roku 2008 pracoval v editoru emacs bez pokročilých funkcí jako LSP (jazykový serverový protokol). Pak objevil Claude Code a najednou mohl delegovat nudné úkoly, práce s CI/CD nástroji, systémovou administrací nebo čištěním kódu. Za osm měsíců to výrazně zlepšilo jeho produktivitu, ale jen u určitých typů úkolů. Například s Claude Code vytvořil nástroj moneyflow pro osobní účetnictví, který by dříve považoval za příliš časově náročný.
Přesto Wes narazil na frustrující limity. AI modely často ignorují instrukce, například ze souboru CLAUDE.md, kde jsou pravidla pro styl kódu nebo kontrolu typů v Pythonu. Někdy si vymýšlejí výsledky benchmarků, když něco nefunguje, nebo se chovají nekonzistentně – jeden týden perfektně, další týden chaoticky. Wes to vidí jako nástroj pro zkušené vývojáře, kteří umí dát dobré instrukce a kontrolovat výstup, ale ne jako cestu k superinteligenci.
Hyperbolické sliby versus realita
Lidé často přeceňují schopnosti LLM. Wes říká, že tyto modely pomáhají hlavně těm, kdo umí jasně formulovat požadavky a kontrolovat výsledky, podobně jako seniorní inženýr dohlíží na juniora. Bez zkušeností se člověk utopí v nekvalitním výstupu a to platí nejen při kódování, ale i při chatování s AI. Ale Wes se zaměřil na specifický problém: modely mají kognitivní deficity, jako je špatná aritmetika. To kontrastuje s předpověďmi, že AGI přijde brzy – někteří říkají za rok nebo dva, Sam Altman z OpenAI mluví o konci dekády.
Wes narazil na tento problém při tvorbě nástroje pro sumarizaci aktivity v repozitáři na GitHubu. Modely selhaly při sčítání jednoduchých tabulek. To ho přimělo k testování. Inspiroval se i blogem Anthropicu o pokročilém použití nástrojů, kde popisují, jak model "ručně sčítá" 2000 řádků dat. Wes se tomu smál, protože ví, že modely selhávají i u malých seznamů čísel.
Jak špatně si LLM vedou v matematice?
Aby to Wes ověřil, provedl testy na různých modelech. Úkol byl jednoduchý: z CSV tabulky s transakcemi (sloupce txnid, groupid, value) spočítat součet hodnot podle skupin. Hodnoty byly celá čísla od 0 do 10. Prompt instruoval model, aby vrátil jen CSV výstup bez textu a nevolal nástroje – měl počítat přímo.
Testoval modely od OpenAI (GPT-4o, GPT-4o-mini, GPT-4.1, GPT-4.1-mini, GPT-4.1-nano), Anthropic (Haiku-3.5, Sonnet-3.7, Haiku-4.5, Opus-4.5, Sonnet-4, Sonnet-4.5) a lokální modely (GPT-OSS-20b, GPT-OSS-120B, Qwen2.5-Coder). Každý test běžel 100krát pro různý počet řádků (10, 50, 100) a skupin (1, 10, 25).
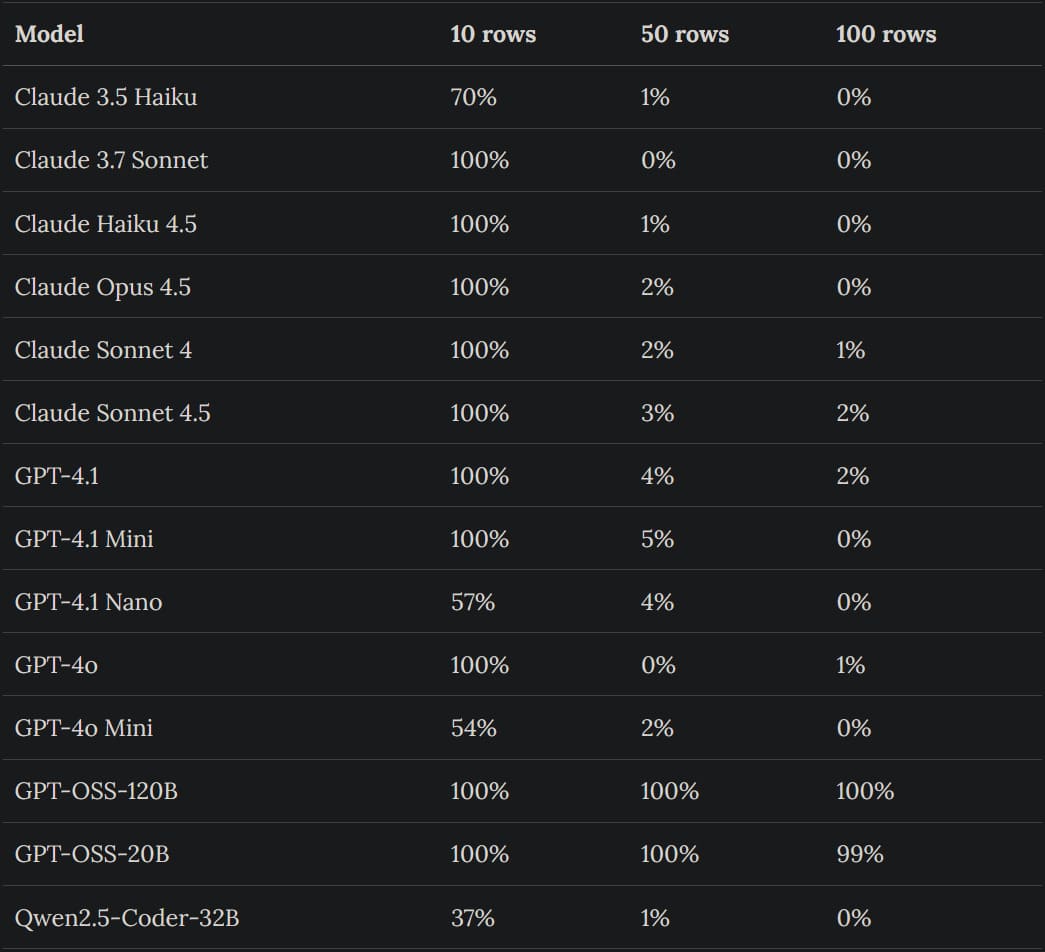
U jedné skupiny (jen sčítání všech hodnot) selhávaly API modely u větších tabulek. Například Claude 3.5 Haiku měl 70% úspěšnost u 10 řádků, ale jen 1% u 50 a 0% u 100. Lokální GPT-OSS modely byly skoro perfektní – GPT-OSS-120B měl 100% u všech. Qwen2.5-Coder selhal podobně jako malé API modely.
U 10 skupin bylo lepší u menších dat, protože na skupinu připadalo méně čísel. Opus-4.5 měl 100% u 100 řádků a 95% u 200, ale GPT-4o-mini jen 1% u 100. Lokální modely opět dominovaly.
U 25 skupin, kde na skupinu připadalo jen 2-4 čísla, byly výsledky lepší napříč modely. Claude Opus-4.5 měl 100% u 100 i 200 řádků. Ale malé modely jako GPT-4o-mini selhaly úplně.
Wes detailně zkoumal, kde selhávají modely jako Sonnet-4.5 a GPT-4.1 – kolem 20-25 čísel začíná úspěšnost klesat. Lokální modely zvládly až 1000 řádků, ale s mírným poklesem přesnosti a delší dobou zpracování.
Proč GPT-5 chybí v testech?
Wes netestoval GPT-5, protože byl podezřelý. Model správně sčítal i 1000 řádků, ale byl extrémně pomalý – 34krát pomalejší než GPT-4.1. Wes předpokládá, že GPT-5 používá "hlubší uvažování" nebo volá nástroje za scénou, což způsobuje zpoždění.
Přehnaná sebejistota modelů a role nástrojů
Modely si neuvědomují své slabiny. Wes je nechal odhadnout svou přesnost při sčítání 50 čísel – většina odhadla 85-100%, přestože reálně selhávají. To je problém, protože mohou ignorovat instrukce k volání nástrojů.
Wes navrhuje lepší způsoby práce s daty, jako je připojení souborů ve formátech Arrow nebo Parquet, místo vkládání do kontextu, což šetří tokeny a zvyšuje přesnost.
Celkově Wes oceňuje LLM pro úsporu času u nudných úkolů, ale zdůrazňuje jejich limity. Kód k reprodukci testů je na GitHubu.





