
Co přesně je CFA?
CFA, neboli Chartered Financial Analyst (Chartered Financial Analyst, certifikovaný finanční analytik), představuje prestižní certifikaci pro profesionály v oblasti investic a financí. Tento program se dělí do tří úrovní, kde každá testuje jiné dovednosti. První úroveň se zaměřuje na základní znalosti prostřednictvím samostatných otázek s výběrem odpovědí. Druhá úroveň zkoumá aplikaci a analýzu pomocí sad otázek založených na případových studiích. Třetí úroveň pak prověřuje složité syntézy a konstrukci portfolií, a to kombinací otázek s výběrem a otázek vyžadujících písemné odpovědi. Jde o náročný proces, který vyžaduje přesné výpočty, kvalitní analýzu a úvahy.
Výzkum se zabývá tím, jak moderní modely umělé inteligence zvládají tyto zkoušky. Použili soubor simulovaných testů s celkem 980 otázkami: tři testy pro první úroveň (540 otázek), dva pro druhou (176 otázek) a tři pro třetí (264 otázek). Tyto testy pocházejí z oficiálních materiálů CFA Institute a zdrojů jako AnalystPrep, přičemž odrážejí aktualizace osnov z let 2024 a 2025, včetně nových specializovaných cest pro třetí úroveň.
Jak probíhalo testování?
Výzkumníci nejprve reprodukovali výsledky starších modelů, jako je ChatGPT (GPT-3.5-turbo), GPT-4 a GPT-4o, aby vytvořili srovnávací základnu. Poté otestovali pokročilé modely jako jsou GPT-5, Gemini 3.0 Pro, Gemini 2.5 Pro, Grok 4, Claude Opus 4.1 a DeepSeek-V3.1. Testy probíhaly ve dvou režimech: zero-shot, kde model dostal otázku přímo bez dalších pokynů, a chain-of-thought, kde byl vyzván k postupnému myšlení a vysvětlení.
Pro hodnocení použili přesná kritéria úspěšnosti. U první úrovně musel model dosáhnout alespoň 60 % v každé tématické oblasti a celkově 70 %. U druhé úrovně to bylo 50 % v každé oblasti a celkově 60 %. U třetí úrovně stačilo průměrné skóre 63 % z kombinace otázek s výběrem a písemných odpovědí. Písemné odpovědi hodnotil automatizovaný systém na základě modelů jako o4-mini, s použitím rubriky od AnalystPrep.
Testy pokrývaly deset hlavních témat pro první a druhou úroveň, včetně kvantitativních metod, ekonomie, finančního reportingu, korporátních emitentů, akciových investic, fixních příjmů, derivátů, alternativních investic a managementu portfolií. Pro třetí úroveň se zaměřily na oblasti jako alokace aktiv, konstrukce portfolií, měření výkonnosti, deriváty a řízení rizik, etické standardy a specializované cesty.
Výsledky: AI překonalo očekávání
Starší modely jako ChatGPT dosáhly na první úrovni skóre kolem 58,9 % až 68,4 %, což nestačilo na úspěch. GPT-4 zvládl první úroveň s 73,3 % až 80,9 %, ale selhal na druhé. GPT-4o prošel první a druhou úrovní s 90,6 % a 73,9 %, a dokonce i třetí s 66,7 % na písemných otázkách.
Pokročilé modely však dominovaly. Gemini 3.0 Pro dosáhl rekordního 97,6 % na první úrovni v zero-shot režimu. GPT-5 vedl na druhé úrovni s 94,3 %. Na třetí úrovni Gemini 2.5 Pro exceloval v otázkách s výběrem s 86,4 %, zatímco Gemini 3.0 Pro dosáhl 92,0 % na písemných odpovědích. Všechny tyto modely prošly všemi úrovněmi, přičemž pořadí podle celkové výkonnosti bylo: Gemini 3.0 Pro, Gemini 2.5 Pro, GPT-5, Grok 4, Claude Opus 4.1 a DeepSeek-V3.1.
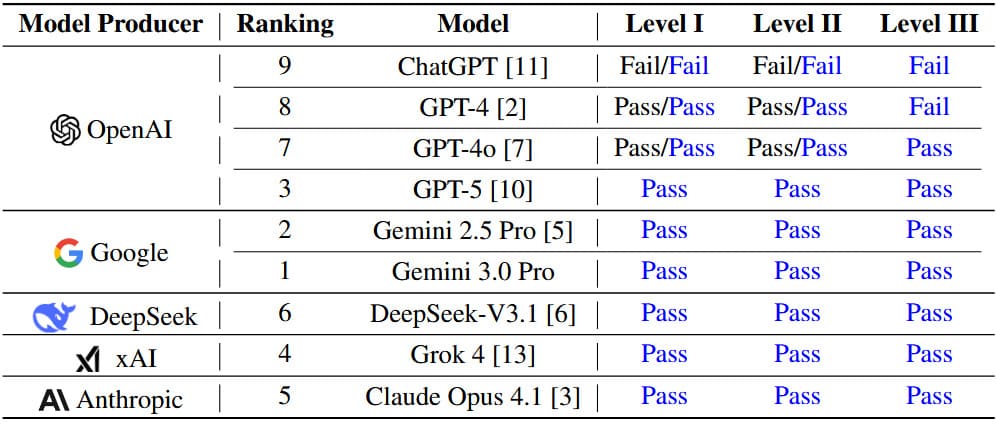
Režim chain-of-thought přinesl zlepšení u starších modelů, ale u novějších byl efekt smíšený – například u Gemini 3.0 Pro došlo k mírnému poklesu na otázkách s výběrem, ale k velkému zlepšení na písemných. Chyby se soustředily hlavně na etické standardy, kde modely jako GPT-5 měly chybovost 17-21 % na druhé úrovni.
Detaily o testovaných modelech a datech
Modely byly testovány s teplotou nastavenou na 0 pro minimální náhodnost a výsledky zahrnovaly průměry s odchylkami. Například GPT-5 používal identifikátor gpt-5-preview ze 7. srpna 2025, Gemini 3.0 Pro gemini-3-pro-preview z 18. listopadu 2025 a Grok 4 grok-4 z 9. července 2025.
Data byla pečlivě vybrána, aby odrážela aktuální osnovy. Například na třetí úrovni zahrnovala specializované otázky jako management portfolií, soukromé trhy nebo soukromé bohatství. Srovnání s předchozí studií potvrdilo, že nové testy mají podobnou distribuci témat, ale s nižším podílem výpočtových otázek díky aktualizacím osnov.
Výzkum uznává limity, jako jsou rizika kontaminace dat trénovacími soubory modelů nebo potenciální zkreslení automatického hodnocení písemných odpovědí, kde delší texty mohou být upřednostňovány. Pro třetí úroveň použili třetí strany jako AnalystPrep, což nemusí plně odpovídat oficiálním testům.
Tato zjištění naznačují, že umělá inteligence dosáhla úrovně, kde zvládá znalosti a syntézu na úrovni zkušených finančních analytiků.





