
Zkuste si tohle. Zadáte dotaz jazykovému modelu a odpověď přijde dřív, než stihnete mrknout. Žádné čekání, žádné točící se kolečko. Tak přesně tohle slibuje startup Taalas se svým prvním produktem, a upřímně, po přečtení čísel mi trochu spadla čelist.
Letos v únoru vyšel Taalas z utajení a ukázal světu, co dva a půl roku vyvíjel v tichosti. Tým pouhých 24 lidí, celkové výdaje jen 30 milionů dolarů z více než 200 milionů vybraných od investorů. A výsledek? Čip, který podle vlastních měření firmy běží 10x rychleji než současná špička trhu a stojí 20x méně na výrobu.
Proč je dnešní AI tak pomalá a drahá?
Abychom pochopili, co Taalas vlastně udělal, musíme si říct, proč je AI inference taková bolest. Moderní jazykové modely běží na obřích GPU serverech, které žerou stovky kilowattů energie, potřebují kapalinové chlazení a celé místnosti plné kabelů. Datová centra rostou do rozměrů malých měst. Náklady letí nahoru jako raketa. A rychlost? Coding asistenti někdy přemýšlejí celé minuty. Vývojář ztratí soustředění, flow je pryč. Agentní AI aplikace přitom potřebují odezvu v milisekundách, ne v lidském tempu.
Taalas říká: tohle je špatně navržený systém. A má pravdu.
Revoluční nápad: zapéct model přímo do křemíku
Zakladatel a CEO Ljubisa Bajic přirovnává situaci k počítači ENIAC z roku 1945. Tenhle kolos plný elektronek zabíral celou místnost, byl pomalý a neúnosně drahý. Pak přišel tranzistor, pak PC, pak smartphone. Výpočetní technika se zmenšila a zlevnila natolik, že ji máme dnes v kapse.
Taalas chce udělat totéž s AI. Jejich přístup je radikálně jiný od všeho, co na trhu existuje. Místo toho, aby model spouštěli softwarově na univerzálním čipu, fyzicky zapékají celý model včetně jeho vah přímo do křemíku. Vznikne tak čip navržený výhradně pro jeden konkrétní model. Říkají tomu Hardcore Model.
Tři principy, na kterých to stojí: totální specializace, sloučení paměti a výpočetní logiky na jednom čipu, a radikální zjednodušení celého hardwarového stacku. Žádné HBM paměti, žádné 3D stacking, žádné kapalinové chlazení. Jen čistá, elegantní architektura.
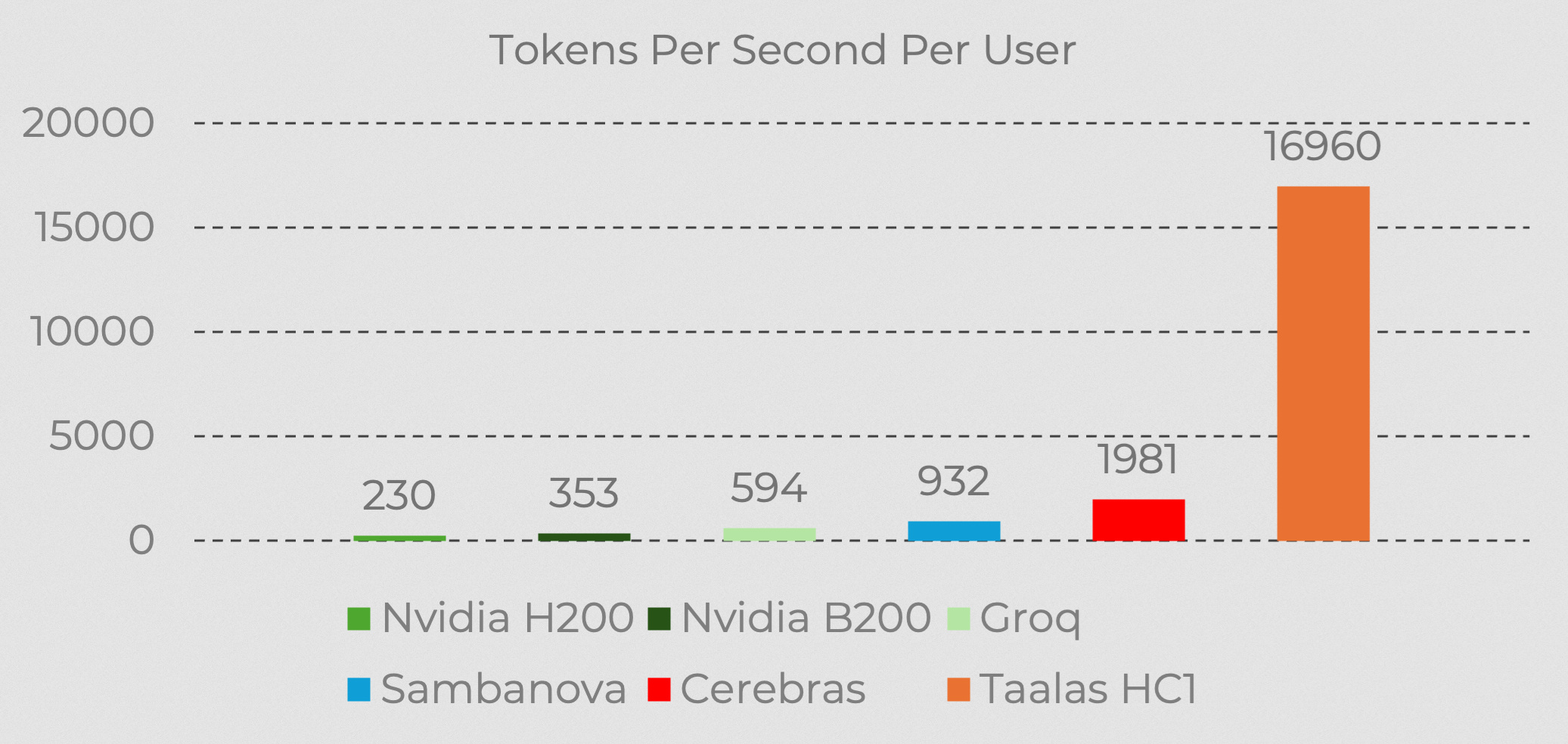
Čísla, která mluví za vše
První produkt Taalas je hardwarová implementace modelu Llama 3.1 8B od Mety. Výsledky jsou, mírně řečeno, šokující. 17 000 tokenů za sekundu na uživatele. Pro srovnání: Cerebras, dosud nejrychlejší inference platforma na světě, dosahuje zhruba desetiny tohoto výkonu. Nvidia H200 GPU? Dva řády níže. Jeden z prvních testerů to popsal jedním slovem: "Šílené."
Spotřeba energie? 12 až 15 kW na rack, zatímco GPU rack potřebuje 120 až 600 kW. Rack Taalas navíc stačí chladit vzduchem. Žádné nákladné přestavby datových center. Cena za inference? 0,75 centu za milion tokenů pro Llama 3.1 8B. GPU přijdou na 20 až 49 centů za totéž. Tohle je skok o celý řád dopředu!
Jak takový čip vzniká?
Taalas spolupracuje s TSMC, největším světovým výrobcem čipů. Základní čip má přibližně 100 vrstev a je předpřipravený. Při příchodu nového modelu stačí upravit pouze dvě kovové vrstvy. Celý proces trvá dva měsíce, zatímco výroba Nvidia Blackwell zabere zhruba šest měsíců.
Tenhle přístup řeší jeden z největších potenciálních problémů: co se stane, když se model změní? Taalas tvrdí, že aktualizaci zvládne za dva měsíce, ne za dva roky. Do ceny zákazníkům zahrnuje tři upgrady po dobu čtyřleté životnosti čipu.
Firma 19. února oznámila také uzavření investičního kola ve výši 169 milionů dolarů. Celkově tak vybrala přes 219 milionů od investorů.
Může Taalas skutečně ohrozit Nvidii?
Otázka za miliardu dolarů. Nebo spíš za bilion. Výhody jsou jasné. Rychlost, cena, spotřeba energie. Jenže datová centra neradi spravují desítky různých SKU pro různé modely. A Meta, jejíž Llama model Taalas jako první zapéká do křemíku, právě podepsala s Nvidií "multigenerační" partnerství. Zjevně ji Taalas nepřesvědčil, aby přešla jinam.
Taalas to ale nevzdává. Plán počítá s mid-size reasoning LLM na jaře 2026 a frontier modelem na druhé generaci čipu HC2 do konce roku. HC2 přinese vyšší hustotu, standardní 4bitové formáty a ještě rychlejší výkon. Jestli se jim podaří přesvědčit velká datová centra, může se trh s AI hardwarem otřást v základech.





