
Umělá inteligence se učí propojovat zvuk a obraz bez lidského zásahu
Vědci z MIT a jejich kolegové vyvinuli nový systém strojového učení, který dokáže samostatně objevit, jak spolu souvisí zvukové a vizuální informace, což představuje pokrok v oblasti umělé inteligence a multimodálního učení. Výzkumný tým představil systém nazvaný CAV-MAE Sync, který přináší několik zásadních vylepšení oproti předchozím přístupům a dosahuje lepších výsledků než mnohem složitější architektury.
Lidé vnímají svět multimodálně, přičemž sluchové a vizuální vnímání jsou spolu velmi úzce propojeny. Právě tato přirozená schopnost inspirovala vědce z Massachusettského technologického institutu (MIT), IBM Research, Univerzity Goethe ve Frankfurtu a dalších institucí k vytvoření systému, který dokáže efektivněji propojovat zvuk a obraz v digitálním prostředí. Jejich výzkum, publikovaný v květnu 2025, představuje pokrok v oblasti učení bez dohledu, kdy se AI systémy učí bez nutnosti označených dat nebo lidských instrukcí. Dosavadní přístupy k audio-vizuálnímu učení obvykle využívaly globální zvukové reprezentace, což v praxi znamenalo, že například 10 sekund zvuku bylo přiřazeno k jednomu snímku videa. Tento přístup však nedokázal zachytit jemnější časové souvislosti mezi zvukem a obrazem. Navíc se tyto metody potýkaly s konfliktními optimalizačními cíli, když se snažily současně učit rekonstrukci a mezimodální zarovnání.
Nový přístup k učení
Nový systém CAV-MAE Sync tyto problémy řeší originálním způsobem, kdy zpracovává zvuk jako časovou sekvenci zarovnanou s jednotlivými snímky videa, místo použití globálních reprezentací. "V našem novém přístupu řešíme tři klíčové výzvy," vysvětluje výzkumný tým ve své publikaci. "Zaprvé řešíme nesoulad granularity mezi modalitami tím, že se zvukem zacházíme jako s časovou sekvencí zarovnanou s video snímky. Zadruhé řešíme konfliktní optimalizační cíle oddělením kontrastivních a rekonstrukčních úkolů prostřednictvím vyhrazených globálních tokenů. A zatřetí zlepšujeme prostorovou lokalizaci zavedením naučitelných registračních tokenů, které snižují sémantickou zátěž tokenů reprezentujících části obrazu."
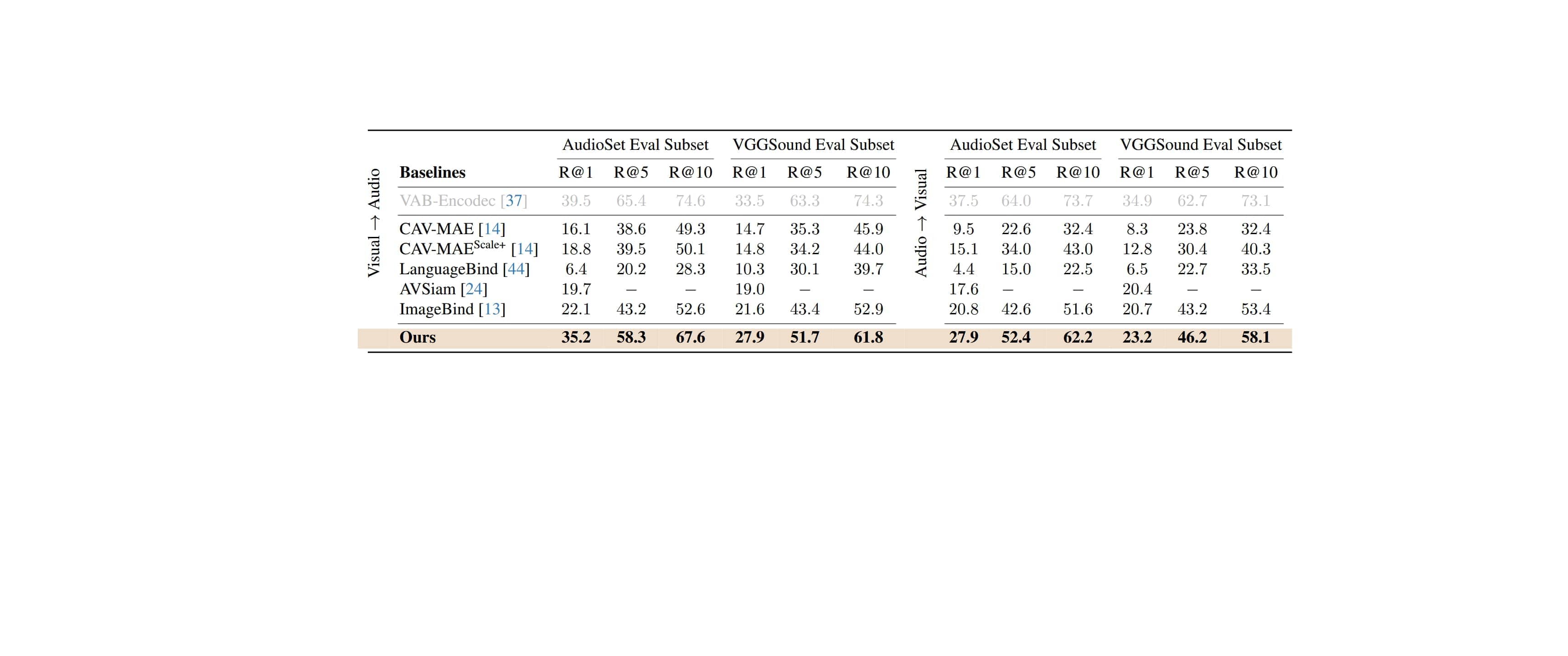
Výzkumníci včetně Yuana Gonga a Andrewa Rouditchenka z MIT, Edsona Arauja z Univerzity Goethe ve Frankfurtu a dalších testovali svůj systém na několika standardních datasetech, včetně AudioSet, VGG Sound a ADE20K Sound. Hodnotili jeho výkon v úlohách jako je vyhledávání bez trénování (zero-shot retrieval), klasifikace a lokalizace. Výsledky ukazují, že CAV-MAE Sync dosahuje špičkových výsledků a překonává složitější architektury. Jedním z klíčových vylepšení je způsob, jakým systém pracuje s časovým zarovnáním zvuku a obrazu. Namísto použití jedné zvukové reprezentace pro celé video, CAV-MAE Sync extrahuje zvukové segmenty odpovídající jednotlivým snímkům videa. Tím zajišťuje, že každý zvukový segment je časově zarovnán s příslušným snímkem videa, což zvyšuje koherenci mezi modalitami a umožňuje přesnější učení souvislostí.
Dalším významným přínosem je zavedení globálních tokenů pro kontrastivní úkoly. Zatímco tradiční přístupy agregují tokeny částí k vytvoření globálních reprezentací, CAV-MAE Sync zavádí vyhrazené globální tokeny speciálně pro kontrastivní úkoly. Tím snižuje informační zátěž na tokeny reprezentující části obrazu, které se nyní mohou soustředit na rekonstrukci, zatímco globální tokeny agregují informace během fází kódování jednotlivých modalit i jejich společného zpracování. Výzkumníci také implementovali tzv. registrační tokeny, které pomáhají udržet tokeny částí zaměřené na rekonstrukční úkoly a umožňují globálním tokenům soustředit se na kontrastivní úkoly. Toto oddělení zlepšuje schopnost modelu zachytit sémantické informace a provádět lokalizaci. Registrační tokeny jsou přidány k tokenovým sekvencím a jsou zpracovávány ve společné vrstvě stejným způsobem jako globální tokeny.
Výsledky experimentů jsou působivé - v úloze vyhledávání dosáhl systém 35,2 % přesnosti při vyhledávání správných odpovídajících zvuků k vizuálním dotazům na datasetu AudioSet, což představuje výrazné zlepšení oproti předchozím metodám. V klasifikačních úlohách dosáhl 30,5 mAP na AudioSet-20K a 52,7 % přesnosti na VGGSound, opět překonávající srovnatelné přístupy. "Naše práce ukazuje, že vylepšením časového zarovnání mezi audio a vizuálními modalitami a oddělením konfliktních optimalizačních cílů můžeme dosáhnout lepších výsledků s jednodušší architekturou," uzavírají výzkumníci. Tento pokrok má potenciální aplikace v široké škále oblastí, od vyhledávání na základě zvuku a obrazu, přes klasifikaci multimediálního obsahu až po lokalizaci zvukových zdrojů ve vizuálních scénách.
Výzkum byl podpořen Německým spolkovým ministerstvem školství a výzkumu a laboratoří MIT-IBM Watson AI. Vědci také zpřístupnili svůj kód na GitHubu, aby umožnili další výzkum a vývoj v této oblasti.





