
Zkuste si vzpomenout, kdy jste naposledy přemýšleli nad tím, kolik místa zabírají moderní AI modely. Asi nikdy, že? Jenže pro firmy, které tyto systémy provozují, je tohle každodenní bolest hlavy. A Google právě přišel s řešením, které může výrazně ulehčit poptávce po paměti.
Co je vlastně ten problém?
AI modely pracují s obrovskými množinami čísel, říkáme jim vektory. Takový vektor si lze představit jako podrobný popis, třeba jak vypadá fotka, co znamená určité slovo, nebo jaké vlastnosti má datová sada. Čím podrobnější popis, tím více čísel, tím více paměti. A paměť, zejména ta rychlá, stojí peníze a má své hranice.
Jednou z největších brzd dnešních AI modelů je takzvaná KV cache. Česky řečeno: rychlá zápisková paměť, do které si model průběžně ukládá informace, aby nemusel neustále prohledávat pomalé úložiště. Jenže tato paměť se ucpává. Vektory jsou prostě velké a rychle ji zaplní.
Vektorová kvantizace je tradiční technika, která tento problém řeší tím, že čísla zaokrouhlí a zmenší. Jenže tradiční metody mají háček: potřebují si ke každému bloku dat uložit ještě tzv. kvantizační konstanty v plné přesnosti. To přidá 1 až 2 bity navíc ke každému číslu a z původní úspory se najednou stane poloviční úspora. Jako byste chtěli ušetřit místem v kufru, ale soupis věcí, které jste zabalili, vám zabral půlku kufru sám o sobě.
Tři algoritmy a jeden cíl
Výzkumníci Googlu Amir Zandieh a Vahab Mirrokni zveřejnili práci, která tento problém řeší třemi algoritmy najednou. Budou představeny na prestižních konferencích ICLR 2026 a AISTATS 2026.
TurboQuant je hlavní algoritmus, který celou věc zastřešuje. Funguje ve dvou krocích.
Nejdřív přijde na řadu PolarQuant. Ten vezme datový vektor a převede ho z klasických souřadnic (X, Y, Z) do takzvaných polárních souřadnic. Místo "jdi 3 bloky na východ a 4 na sever" řekne "jdi 5 bloků pod úhlem 37 stupňů". Výsledkem jsou dvě věci: poloměr (jak silný je daný signál) a úhel (co daný signál znamená). A protože rozložení úhlů je předvídatelné, model nepotřebuje ukládat žádné pomocné konstanty. Paměťová réžie zmizí.
Potom nastoupí QJL (Quantized Johnson-Lindenstrauss). Každé číslo zredukuje na jediný bit, konkrétně jen na znaménko (+1 nebo -1). Tohle zní šíleně, ale matematika za tím, takzvaná Johnsonova-Lindenstraussova transformace, zaručuje, že důležité vztahy mezi daty zůstanou zachovány. QJL se přitom aplikuje jen na ten malý zbytek chyb, který PolarQuant zanechá. Slouží jako matematická záplata, která eliminuje zkreslení a zpřesní výsledek.
Co to v praxi dokáže?
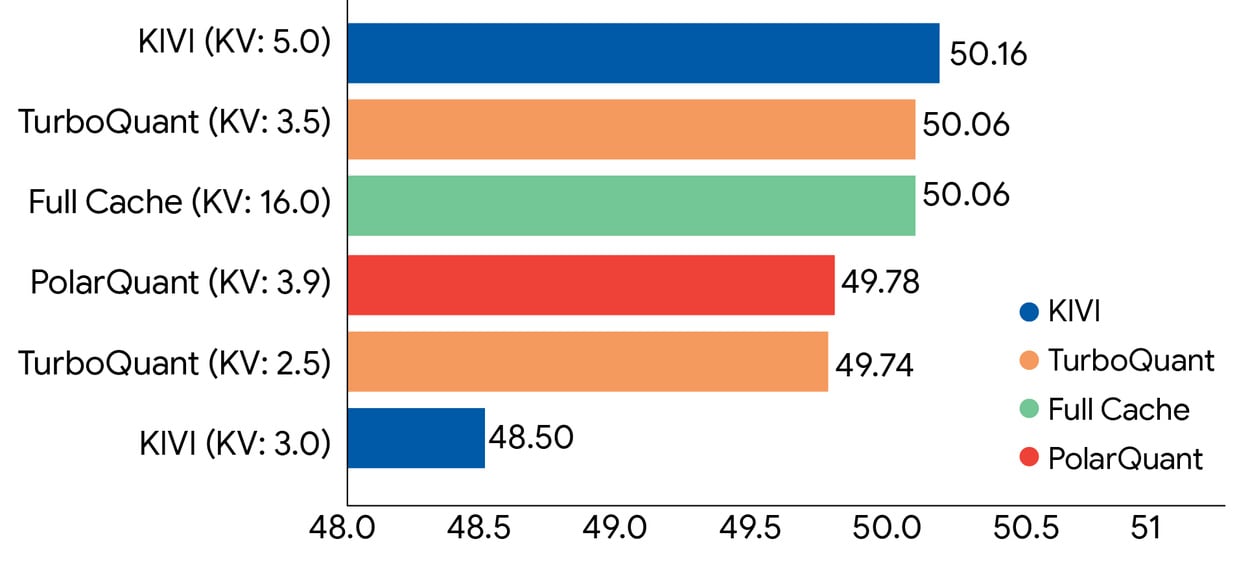
Výsledky testů jsou pěkně přesvědčivé. Výzkumníci zkoušeli všechny tři algoritmy na otevřených jazykových modelech Gemma a Mistral, a to přes celou řadu náročných testů zaměřených na práci s dlouhými texty. TurboQuant dokáže stlačit KV cache na pouhé 3 bity bez jakéhokoliv dotrénování modelu a bez znatelné ztráty přesnosti. To je zásadní, protože u jiných metod komprese obvykle zaplatíte sníženou kvalitou odpovědí.
Rychlost? 4bitový TurboQuant je až 8krát rychlejší než původní nekomprimovaná verze na grafických kartách NVIDIA H100. Osm krát. Na stejném hardwaru.
A co vyhledávání v milionech vektorů najednou, takzvaný vector search, který pohání velké vyhledávače? TurboQuant si vede lépe než konkurenční metody PQ a RabbiQ, a to i přesto, že ty konkurenční metody používají velké pomocné tabulky a jsou speciálně doladěné pro konkrétní data. TurboQuant tohle nepotřebuje, funguje obecně.
Víc než jen technická vychytávka
Googlu jde zřejmě o víc než jen o akademické výsledky. TurboQuant míří přímo do praxe, konkrétně do provozu jejich vlastního modelu Gemini. Méně paměti znamená nižší provozní náklady a možnost obsluhovat víc uživatelů najednou.
Celý přístup stojí na pevných matematických základech, ne jen na empirickém "zkusili jsme to a fungovalo to". Autoři dokazují, že algoritmy pracují blízko teoretického optima. To je důležité pro důvěryhodnost v produkčním prostředí, kde selhání stojí reálné peníze.
Výzkum vznikl ve spolupráci s odborníky z Google DeepMind, newyorské univerzity NYU a jihokorejské technické univerzity KAIST. Není to tedy dílo jednoho týmu, ale výsledek širší spolupráce napříč výzkumným světem. Letos na konferencích ICLR a AISTATS uvidíme, jak na tyto výsledky zareaguje zbytek komunity. Sázím na to, že ticho to nebude.





