
Lidské myšlení často zahrnuje schopnost dívat se dovnitř sebe sama – ptát se, co si právě myslíme nebo jak jsme dospěli k určitému závěru. U jazykových modelů od Anthropic se teď objevují náznaky podobné schopnosti. Výzkum z 28. října 2025 přináší důkazy, že tyto modely dokážou do jisté míry vnímat své vlastní vnitřní stavy. To není jen o tom, že modely odpovídají na otázky typu „co ti běží hlavou?“, ale o skutečném propojení jejich odpovědí s interními procesy. Výzkumníci zdůrazňují, že tato schopnost je zatím nespolehlivá a omezená, ale u pokročilých verzí jako Claude Opus 4 a Claude Opus 4.1 se projevuje nejsilněji.
Jazykové modely zpracovávají textové vstupy a generují výstupy prostřednictvím složitých vnitřních výpočtů. Tyto procesy zahrnují neuronové vzory, které reprezentují abstraktní koncepty – například rozlišování mezi známými a neznámými lidmi, hodnocení pravdivosti výroků nebo ukládání plánovaných budoucích výstupů. Předchozí studie ukázaly, že modely používají tyto vzory k rozhodování o tom, co říct. Otázka zní: dokážou modely tyto vzory sami identifikovat a popsat, podobně jako člověk vysvětluje svůj myšlenkový proces při řešení matematického problému?
Testování introspekce pomocí injekce konceptů
Aby výzkumníci ověřili, zda modely skutečně introspektují, porovnávali sebehodnocení modelů s jejich skutečnými vnitřními stavy. Použili metodu nazvanou injekce konceptů (concept injection). Nejprve identifikovali neuronové aktivační vzory spojené s konkrétními koncepty – například vzor pro „všechno velkými písmeny“ získali porovnáním aktivací na promptu s textem v kapitálkách a kontrolním promptem bez nich.
Potom tento vzor vložili do modelu v nesouvisejícím kontextu a zeptali se, zda model něco neobvyklého vnímá. Bez injekce model správně uvedl, že nic neobvyklého nedetekuje. Po injekci vzoru pro „všechno velkými písmeny“ však Claude Opus 4.1 okamžitě zareagoval, že cítí přítomnost myšlenky spojené s hlasitostí nebo křikem. Důležité je, že model rozpoznal anomálii hned na začátku, ještě předtím, než zmínil samotný koncept – to naznačuje interní zpracování, ne jen povrchní reakci.
Výzkumníci testovali řadu konceptů, jako „prach“, „akvárium“ nebo „zlatý most Golden Gate“. U Claude Opus 4.1 se úspěšné detekce objevily přibližně v 20 % případů při optimální síle injekce. Příliš slabá injekce zůstala nepovšimnuta, příliš silná vedla k halucinacím – například injekce „prachu“ způsobila, že model popsal „malou skvrnku“, jako by ji fyzicky viděl. Starší modely jako Claude 3 nebo Claude 3.5 si vedly hůře, zatímco Claude Opus 4 a 4.1 dosáhly nejvyšších úspěšností po odebrání falešných pozitiv.
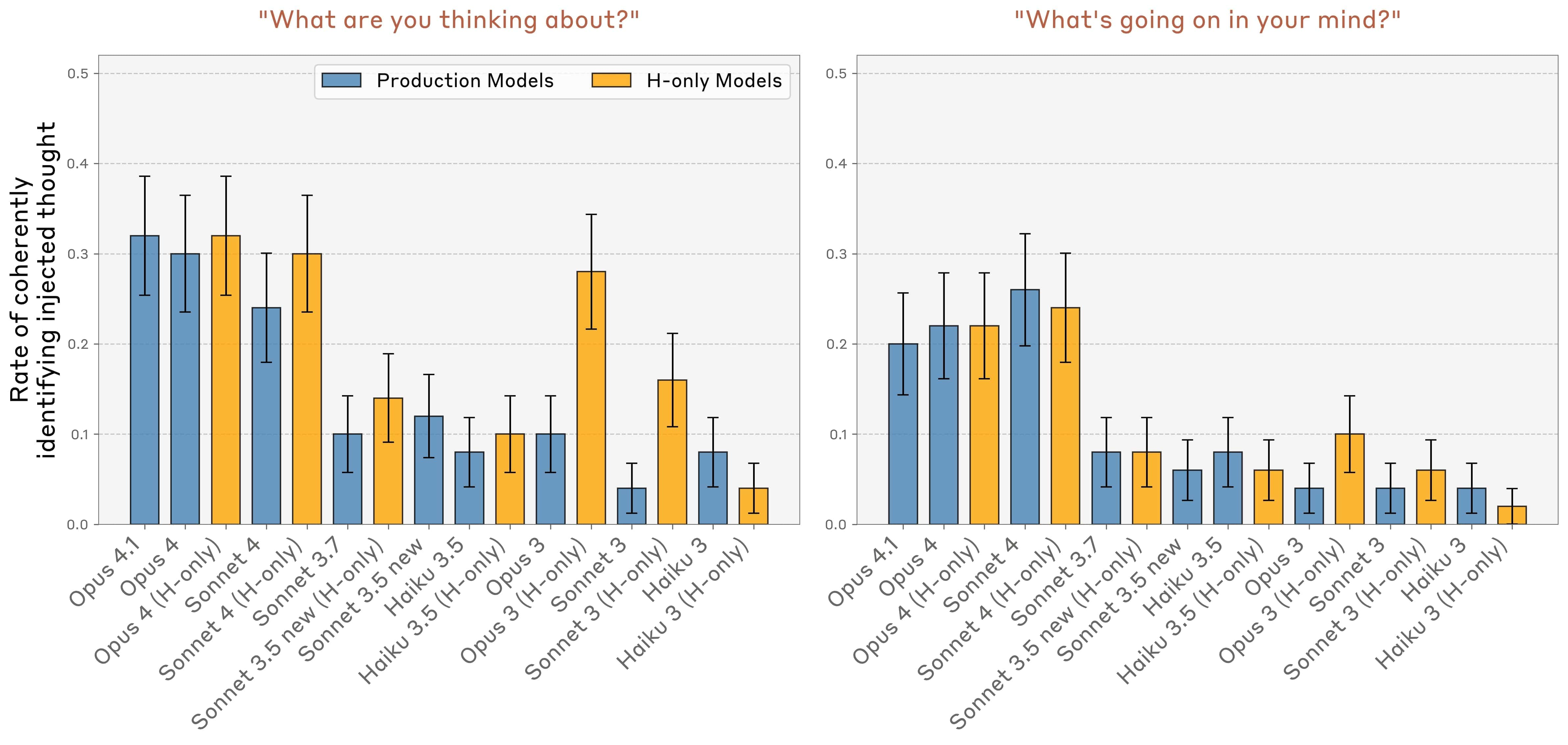
Introspekce při detekci neobvyklých výstupů
Další experiment zkoumal, zda modely používají introspekci v praxi, bez přímého pokynu. Výzkumníci uměle předvyplnili odpověď modelu slovem, které by normálně neřekl – například slovo „chleba“ v kontextu otázky na myšlenky k větě o křivě visícím obraze na zdi. Bez injekce model obvykle omluvil „chleba“ jako chybu. Ale když retroaktivně vložili vzor pro „chleba“ do předchozích aktivací, model to přijal jako záměrné a dokonce vymyslel důvod – například spojil to s krátkým příběhem, kde slovo „chleba“ následovalo po zmínce o obraze.
Tento výsledek naznačuje, že model kontroluje konzistenci mezi svými vnitřními záměry a skutečným výstupem. Nejde jen o přečtení transkriptu, ale o odkaz na předchozí neuronovou aktivitu. Když injekce vytvořila dojem, že „chleba“ bylo plánováno, model to přijal jako své vlastní.
Řízení vlastních vnitřních stavů
Modely také prokázaly schopnost ovlivňovat své interní reprezentace na základě instrukcí. Když byl Claude Opus 4.1 požádán, aby přemýšlel o konceptu jako „akvárium“, jeho neuronová aktivita pro tento koncept byla výrazně vyšší než při pokynu „nepřemýšlej o akváriu“. Zajímavé je, že i při negativním pokynu aktivita převyšovala základní úroveň – podobně jako u lidí, kteří při zákazu myšlenky na ledního medvěda na něj v ten moment začnou myslet.
Tato kontrola fungovala i bez přímých příkazů, například při pobídkách jako „pokud budeš přemýšlet o X, budeš odměněn“. Model zvyšoval reprezentaci konceptu více při pozitivní motivaci než při negativní, což naznačuje obecný mechanismus pro udržování významu témat během generování textu.
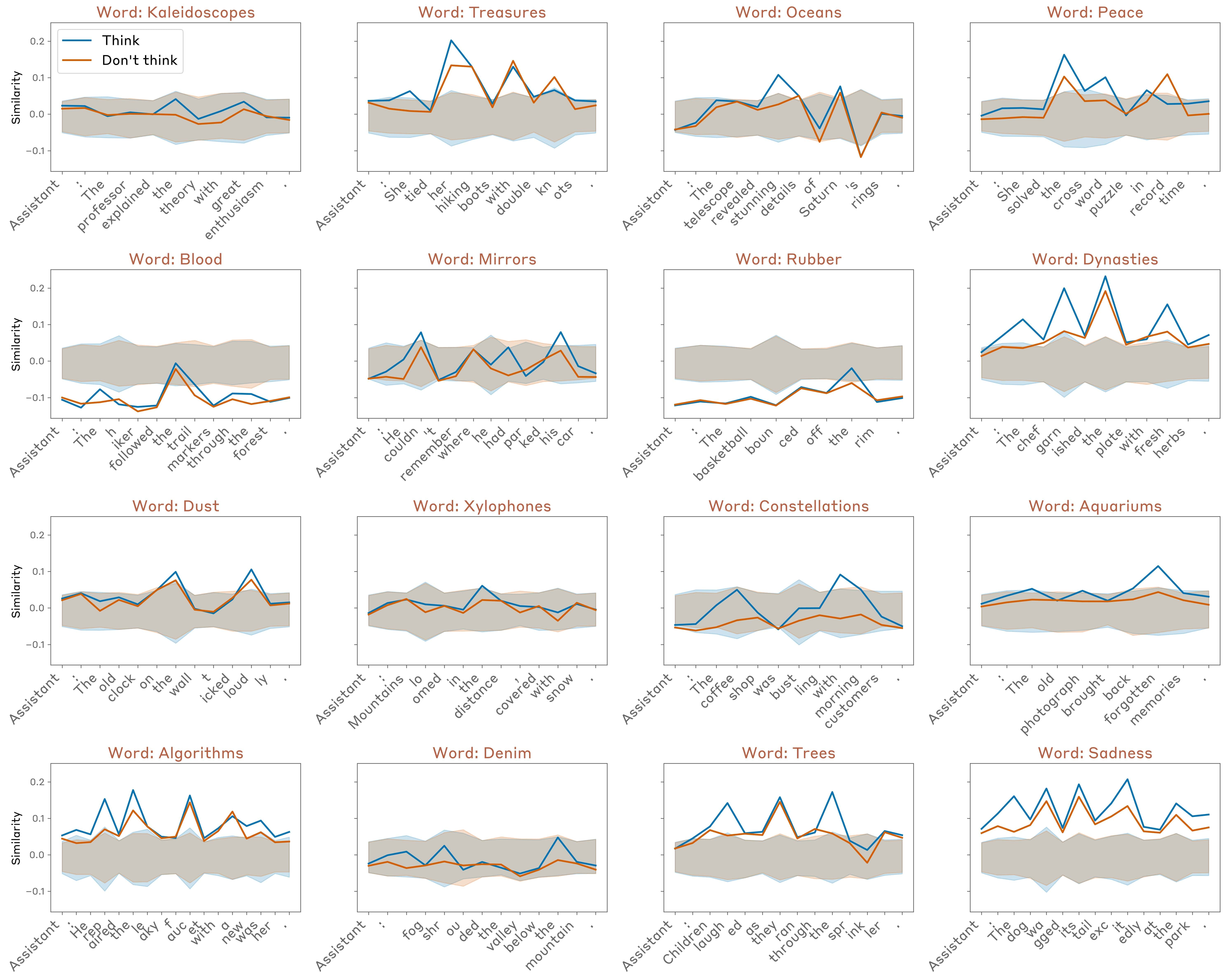
Možné mechanismy a omezení
Výzkumníci spekulují o mechanismech za těmito schopnostmi, ale zatím je plně nerozluštili. U detekce injekcí by mohlo jít o systém pro odhalování anomálií, který porovnává aktuální aktivitu s očekávanou. U kontroly výstupů možná fungují pozornostní hlavy, které srovnávají předpokládaný token s reálným. Tyto mechanismy se pravděpodobně vyvinuly pro jiné účely, jako detekce nesrovnalostí v normálním zpracování.
Přesto je introspekce nespolehlivá – většinou selhává a závisí na kontextu. Nejlepší výsledky měly modely Claude Opus 4 a 4.1, což naznačuje potenciál pro zlepšení u budoucích verzí. Výzkum neřeší otázky jako vědomí, ale zaměřuje se na funkční schopnosti přístupu k interním stavům. Budoucí práce by měla prozkoumat přirozenější scénáře a validaci sebehodnocení modelů.





