
V posledních dnech se v oblasti umělé inteligence objevila zajímavá novinka z Jižní Koreje. Startup Motif Technologies vydal model nazvaný Motif-2-12.7B-Reasoning, který má jen 12,7 miliardy parametrů, ale přesto dosáhl skvělých výsledků v testech. Podle nezávislého laboratoře Artificial Analysis tento model získal 45 bodů v indexu inteligence a stal se nejlepším modelem z Koreje. Překonal dokonce i některé větší modely, jako je běžný GPT-5.1 od OpenAI. Tento otevřený model s volně dostupnými váhami je navržený pro uvažování (reasoning) a ukazuje, že i menší týmy mohou soutěžit s velkými hráči z USA a Číny.
Motif Technologies, který sídlí v Jižní Koreji, se zaměřil na tvorbu modelů pro podniky. Jejich model trénovali na datech o objemu 187 miliard tokenů, včetně korejských patentů a výzkumných zpráv. Trénink trval jen tři měsíce a model dosáhl skóre 64,74 v korejském benchmarku KMMLU. To je lepší než u GPT-4 v některých oblastech. Firma zveřejnila i bílou knihu na arxiv.org, kde popisuje svůj postup, včetně hybridní paralelizace a optimalizace paměti na hardwaru Nvidia H100.
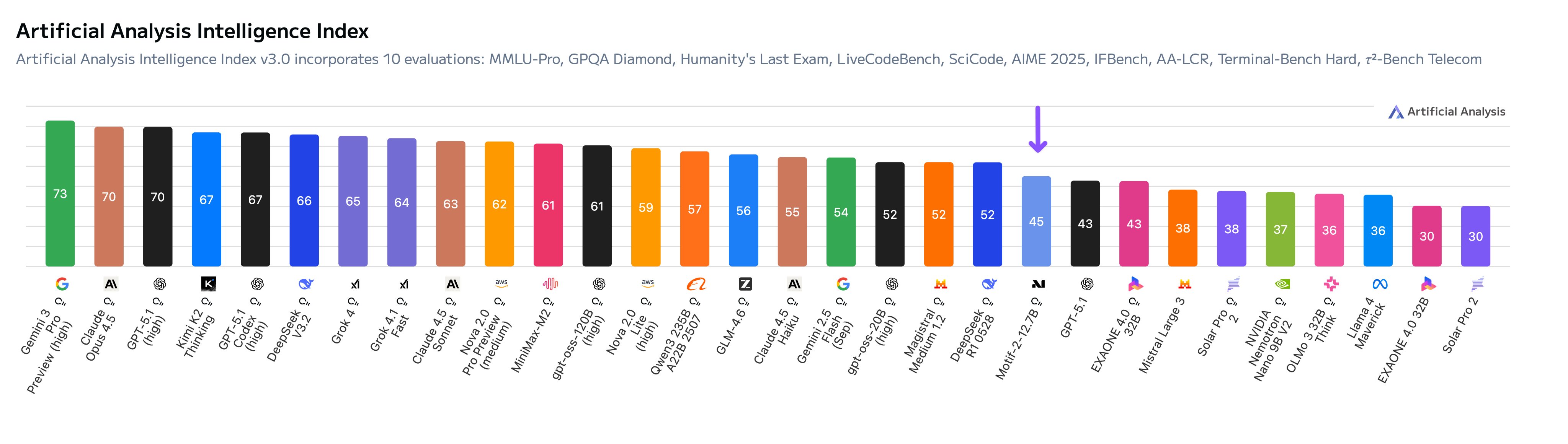
Co zjistili v Motif Technologies
1.) Jedna z hlavních zkušeností Motif Technologies je, že syntetická data pro uvažování pomáhají jen tehdy, když jejich struktura odpovídá stylu cílového modelu. V testech zjistili, že výkon v kódování závisí na tom, který "učitelský" model vytvořil stopy uvažování během jemného ladění (fine-tuning). Pokud data neodpovídají formátu, délce kroků nebo podrobnosti, mohou dokonce snížit výkon, i když vypadají kvalitně.
Pro firmy to znamená, že nestačí jen generovat spoustu dat z velkých modelů. Je nutné kontrolovat, jestli data odpovídají požadovanému výstupu v reálném použití. Motif zdůrazňuje, že interní testovací smyčky jsou důležitější než kopírování externích datových sad.
2.) Motif trénoval svůj model na kontextu 64 tisíc tokenů, což není jen jednoduchá úprava tokenizeru nebo ukládání bodů. Použili hybridní paralelizaci, pečlivé rozdělování dat a agresivní ukládání aktivací, aby to zvládli na běžném hardware. To umožnilo stabilní trénink bez velkých problémů.
Pro podniky je to varování: Schopnost zpracovávat dlouhý kontext nelze přidat později. Pokud vaše práce zahrnuje vyhledávání nebo agentní postupy, musí být délka kontextu součástí plánu od začátku. Jinak hrozí drahé přetrénování nebo nestabilní úpravy.
3.) V postupu jemného ladění pomocí posilování (RLFT) Motif zdůrazňuje filtrování podle obtížnosti – udržují úkoly, jejichž úspěšnost spadá do určitého rozsahu. Místo slepého zvětšování tréninku s odměnami znovu používají trajektorie napříč politikami a rozšiřují rozsahy ořezávání pro lepší stabilitu.
To řeší běžné problémy firem, jako jsou poklesy výkonu nebo ztráta stability mimo testy. Motif ukazuje, že posilování je systémová záležitost, ne jen otázka modelu odměn. Bez filtrování, opětovného použití a vyvážení úkolů může tento postup destabilizovat jinak připravené modely.
4.) Motif používá optimalizace na úrovni jádra, aby snížil tlak na paměť během posilování. Techniky jako optimalizace ztrátové funkce umožňují pokročilé fáze tréninku. V podnicích, kde je paměť často problémem, to zdůrazňuje potřebu investic do nízké úrovně inženýrství.
Firma také zdůrazňuje kvalitu a množství dat – kurátovali 187 miliard tokenů korejských dat, včetně specializovaných zdrojů. Vytvořili unikátní předtrénované a instrukční modely pro složité věty a konverzace. Jejich otevřená strategie zahrnuje uvolnění modelů jako Llama-3-Motif-102B na Hugging Face, což podporuje ekosystém. Navíc nabízejí službu Personal AI pro snadné přizpůsobení modelů s minimem dat, včetně šablon pro konverzace, generování obrázků nebo kód.
Důraz na lokalizaci a přístupnost
Motif Technologies ukazuje, že modely přizpůsobené konkrétnímu jazyku, jako je korejština, mohou překonat globální giganty v místních úkolech. To platí i pro jiné jazyky, například japonštinu, kde globální modely často selhávají v nuancích. Firma nabízí modely na Hugging Face pro snadné testování, jako je Motif-102B, který lze upravit s vlastními daty pro interní chatbota.
Tento přístup dělá AI dostupnější pro menší firmy, bez potřeby obrovské infrastruktury. Motif-2-12.7B-Reasoning je konkurenční s většími modely díky disciplinovanému designu tréninku, ne jen velikosti.





