
Hierarchický model uvažování (HRM): 100x rychlejší uvažování než LLM
Představte si, že umělá inteligence (AI) dokáže řešit složité hádanky, jako jsou extrémně těžké sudoku nebo bludiště, rychleji a s méně daty než dnešní obří jazykové modely. To je realita nového modelu zvaného Hierarchical Reasoning Model (HRM), který vyvinula singapurská firma Sapient Intelligence. Tento model, inspirovaný fungováním lidského mozku, přináší průlom v oblasti uvažování a mohl by změnit, jak AI pomáhá v medicíně, klimatických předpovědích nebo robotice. Pojďme se podívat, co to je, jak to funguje a proč to má takový potenciál.
Co je Hierarchical Reasoning Model (HRM)?
Hierarchical Reasoning Model (HRM) je nová architektura AI, kterou Sapient Intelligence otevřeně zveřejnila na GitHubu. Model má pouze 27 milionů parametrů, což je zlomek velikosti dnešních velkých jazykových modelů (LLM), jako je Claude 3.7 Sonnet nebo OpenAI o3-mini-high. Přesto dosahuje výjimečných výsledků na úlohách, které vyžadují hluboké uvažování, jako je abstraktní myšlení nebo hledání optimálních cest. HRM nepotřebuje obrovské množství dat – stačí mu jen 1000 trénovacích příkladů bez jakéhokoli předtrénování nebo speciálních technik jako Chain-of-Thought (řetězec myšlenek, CoT).
Model je navržený tak, aby napodoboval hierarchickou strukturu lidského mozku, kde různé části pracují na různých úrovních a rychlostech. Autoři, jako Guan Wang, Jin Li, Yuhao Sun, Xing Chen, Changling Liu, Yue Wu, Meng Lu, Sen Song a Yasin Abbasi Yadkori, popsali HRM v dokumentaci jako systém, který řeší složité sekvenční úlohy v jediném průchodu bez explicitního dohledu nad mezikroky. Na rozdíl od LLM, které spoléhají na generování textových kroků, HRM uvažuje v latentním prostoru – tedy interně, bez nutnosti všechno převádět na slova.
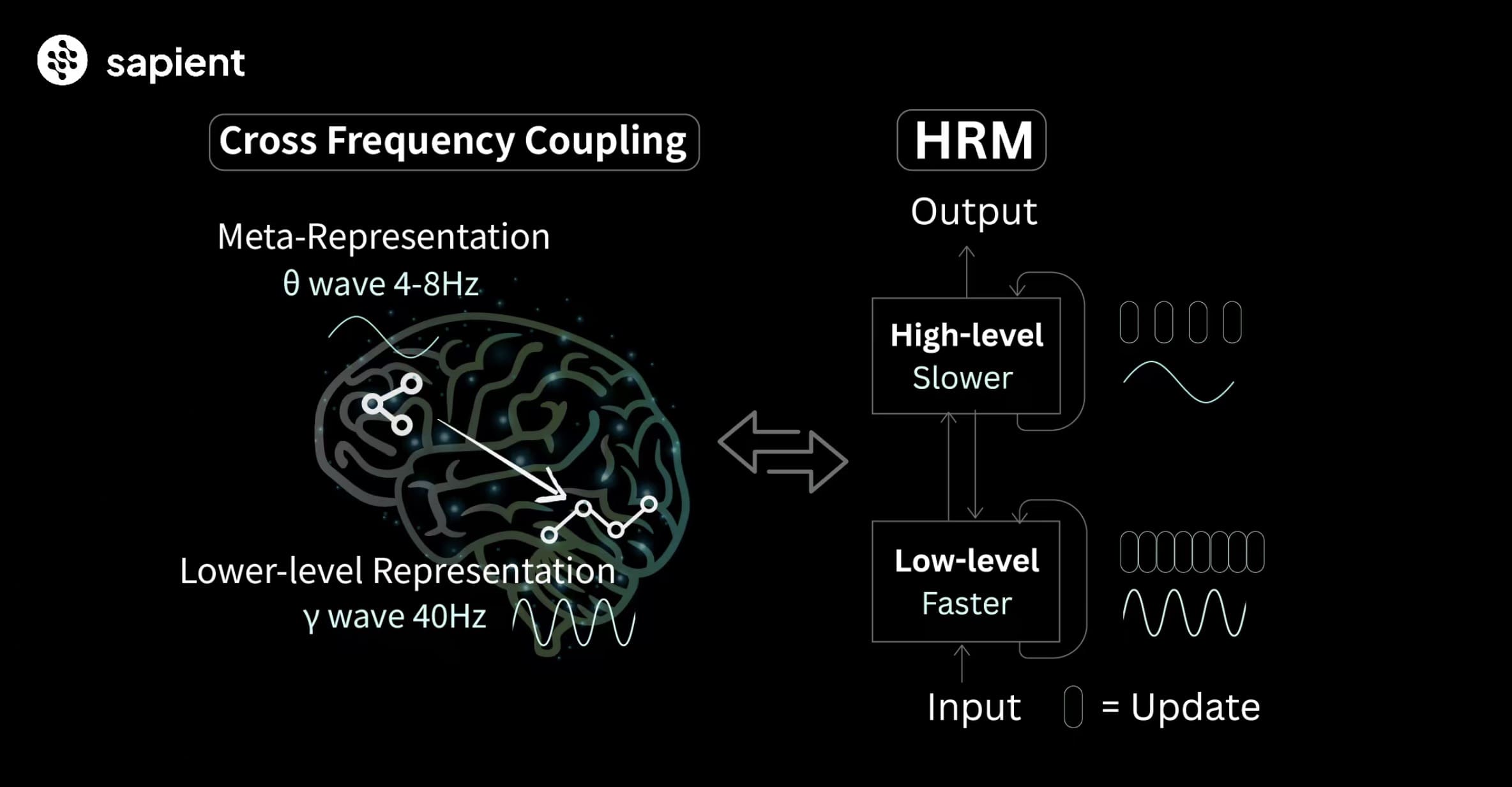
Jak HRM funguje?
HRM je postavený na dvou vzájemně propojených rekurentních modulech, které pracují na různých časových škálách, podobně jako mozek. Vysokoúrovňový modul (H-modul) se stará o pomalé, abstraktní plánování – jako by přemýšlel o celkové strategii. Nízkourovňový modul (L-modul) zase zpracovává rychlé, detailní výpočty – řeší konkrétní podúlohy. Tyto moduly spolupracují v procesu zvaném hierarchická konvergence, kde L-modul provádí několik kroků, dokud nedosáhne lokálního řešení, a pak H-modul aktualizuje plán a zadá novou podúlohu.
Tento přístup umožňuje modelu provádět hluboké uvažování bez problémů, jako je mizející gradient (vanishing gradient) v hlubokých sítích nebo předčasná konvergence v rekurentních architekturách. Například při řešení bludiště HRM postupně zkoumá cesty: L-modul rychle prohledává část bludiště, zatímco H-modul upravuje směr na základě výsledků. Celý proces probíhá v jediném forward passu, což znamená, že model nepotřebuje generovat dlouhé textové řetězce jako CoT. Podle Guan Wanga, zakladatele Sapient Intelligence, to umožňuje až 100x rychlejší dokončení úloh oproti tradičním LLM, protože HRM zpracovává informace paralelně v latentním prostoru.
Model je trénovaný na specifických datasetech, jako je ARC-AGI (Abstraction and Reasoning Corpus), sudoku-extreme nebo maze-30x30-hard. Například pro sudoku se dataset vytváří pomocí skriptu build_sudoku_dataset.py, který generuje 1000 augmentovaných příkladů. Trénink na jednom GPU trvá asi 10 hodin pro sudoku a kolem 24 hodin pro ARC-AGI, což je mnohem méně než u velkých modelů. HRM používá techniky jako FlashAttention pro efektivitu a je kompatibilní s PyTorch a CUDA.
Výkony HRM na benchmarcích
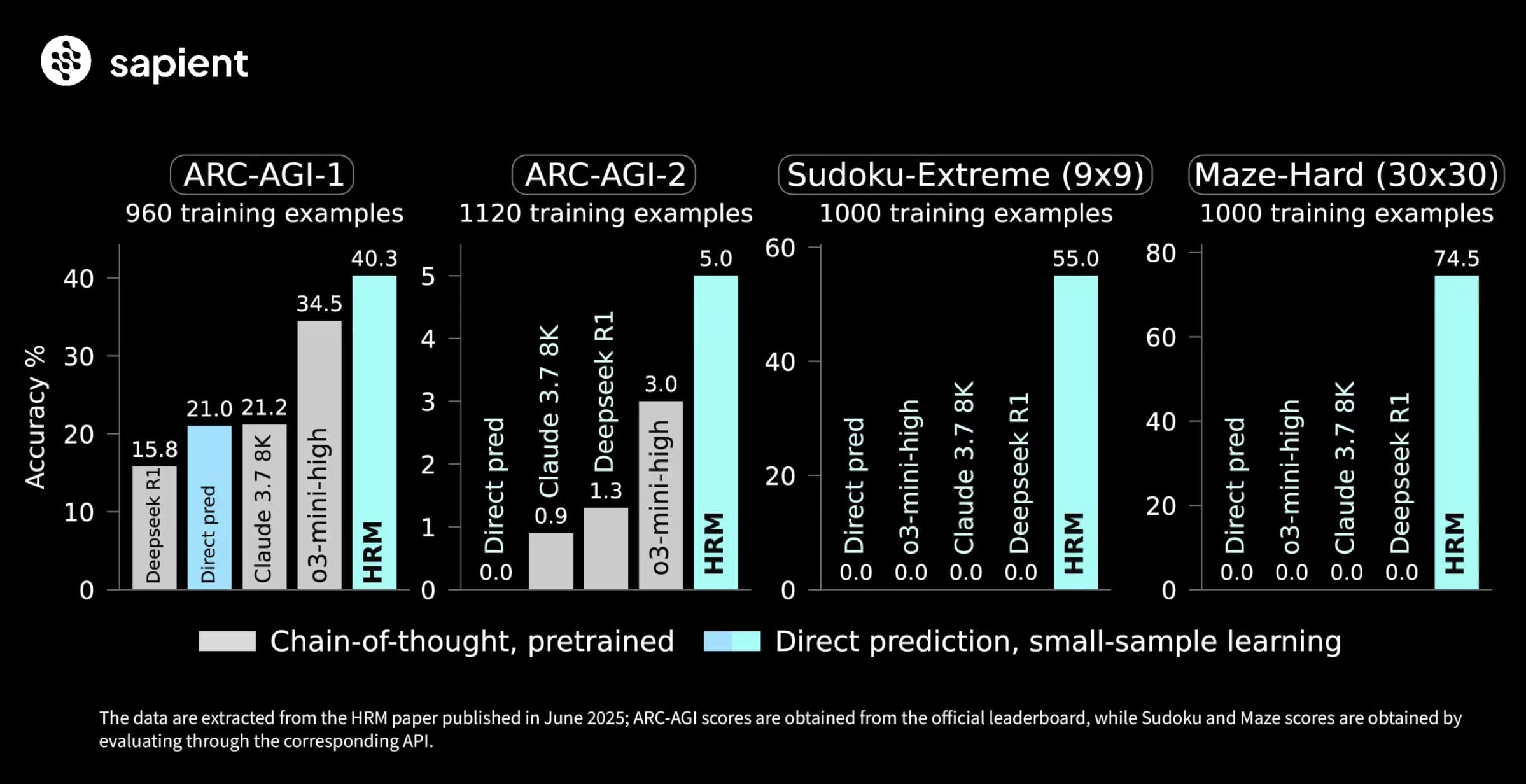
HRM exceluje na úlohách, kde selhávají i pokročilé LLM. Na benchmarku ARC-AGI-2 dosáhl skóre 40,3 %, což překonává OpenAI o3-mini-high (34,5 %) a Claude 3.7 Sonnet (21,2 %), přestože tyto modely mají mnohem více parametrů a delší kontextové okno. Na extrémně těžkých sudoku úlohách (Sudoku-Extreme) a hledání optimálních cest v 30x30 bludištích (Maze-Hard) dosahuje HRM téměř 100% přesnosti, zatímco CoT metody selhávají úplně (0 %).
Například v ARC-AGI model řeší abstraktní úlohy, jako je transformace mřížek barev, s pouhými 1000 příklady. Pro sudoku trénink probíhá s parametry jako epochs=20000, lr=7e-5 a global_batch_size=384, což vede k master-level výkonu. Podobně pro bludiště stačí 1 hodina tréninku na 8 GPU. Tyto výsledky ukazují, že HRM nepotřebuje masivní data – naučí se řešit problémy efektivně, jako by se z nováčka stal expert, s postupně méně kroky.
Budoucí potenciál HRM
Potenciál HRM sahá daleko za hádanky. Sapient Intelligence již testuje model v reálných aplikacích, jako je podpora komplexních diagnóz v medicíně, kde data o vzácných nemocech jsou omezená. V klimatických předpovědích zvyšuje přesnost subsezónních až sezónních prognóz (S2S) na 97 %, což má přímý sociální a ekonomický dopad. V robotice slouží HRM jako "rozhodovací mozek" na zařízeních s nízkou latencí, umožňující reálný čas v dynamických prostředích.
Guan Wang zdůrazňuje, že HRM nabízí alternativu k drahým, latencí zatíženým LLM pro deterministické úlohy vyžadující dlouhodobé plánování. S nízkými náklady na trénink (např. 2 GPU hodiny pro sudoku, 50-200 pro ARC-AGI) by mohl model revolučně změnit oblasti jako logistika nebo vědecký výzkum. Sapient plánuje rozšíření na samoopravující se modely, které překonají dnešní textové systémy. Tento přístup, založený na architektuře inspirované mozkem spíš než na škálování, by mohl vést k univerzálním systémům umělé obecné inteligence (AGI), kde AI překoná lidské limity v uvažování.





