
Google představuje kvantizované modely Gemma 3
Google představil kvantizované modely Gemma 3, které přinášejí výkon pokročilé AI i na běžně dostupný hardware. Největším překvapením je, že i masivní model s 27 miliardami parametrů lze nyní provozovat na spotřebitelských grafických kartách jako je NVIDIA RTX 3090.
Kvantizace jako klíč k dostupnosti
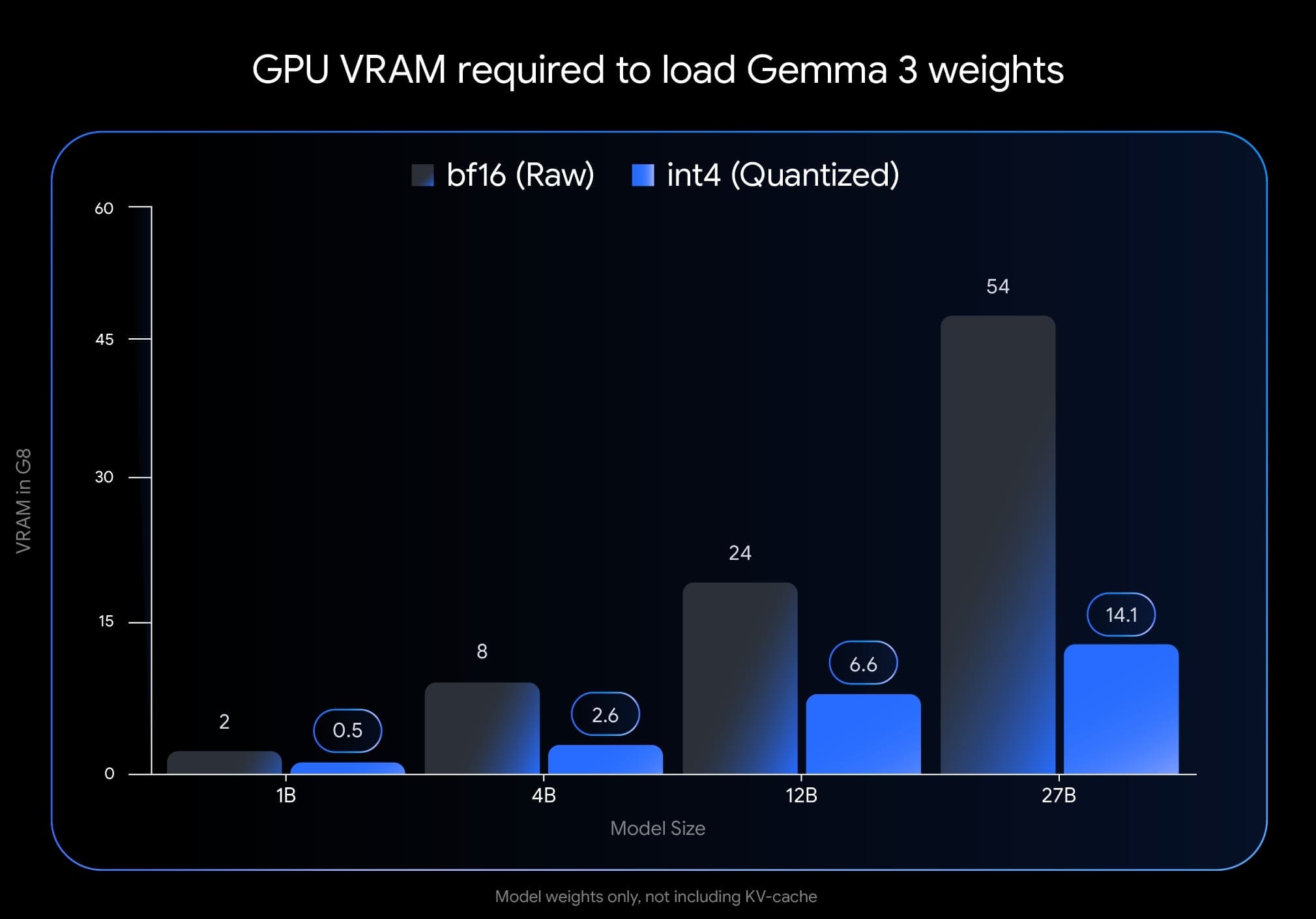
Kvantizace je technika, která umožňuje spustit náročné AI modely na méně výkonném hardwaru snížením přesnosti čísel používaných pro výpočty. Zatímco běžné modely často vyžadují 16 nebo 32 bitů pro reprezentaci každého čísla (FP16/FP32), kvantizované modely mohou pracovat s pouhými 4 nebo 8 bity (INT4/INT8). Co je však převratné na modelech Gemma 3 je, že byly trénovány s vědomím budoucí kvantizace ("quantized-aware training"). Na rozdíl od běžného přístupu, kdy se model nejprve trénuje v plné přesnosti a teprve poté kvantizuje, Google zahrnul kvantizaci již do trénovacího procesu. Výsledkem je, že modely Gemma 3 dosahují vynikajících výsledků i v nízkém rozlišení.
Gemma 3 s 27B parametrů na vašem stolním počítači
Nejpůsobivější je, že i největší 27 miliardový model Gemma 3 lze nyní provozovat na běžné spotřebitelské grafické kartě jako je NVIDIA RTX 3090. Tato karta, ačkoliv stále výkonná, je cenově mnohem dostupnější než specializovaný hardware, který byl dříve pro podobně velké modely nezbytný. Podle údajů od Googlu dokáže RTX 3090 s 24 GB VRAM spustit model Gemma 3 27B v 4-bitové kvantizaci s rychlostí generování textu 10 tokenů za sekundu. To je dostatečná rychlost pro většinu praktických aplikací.
Výkon srovnatelný s mnohem většími modely
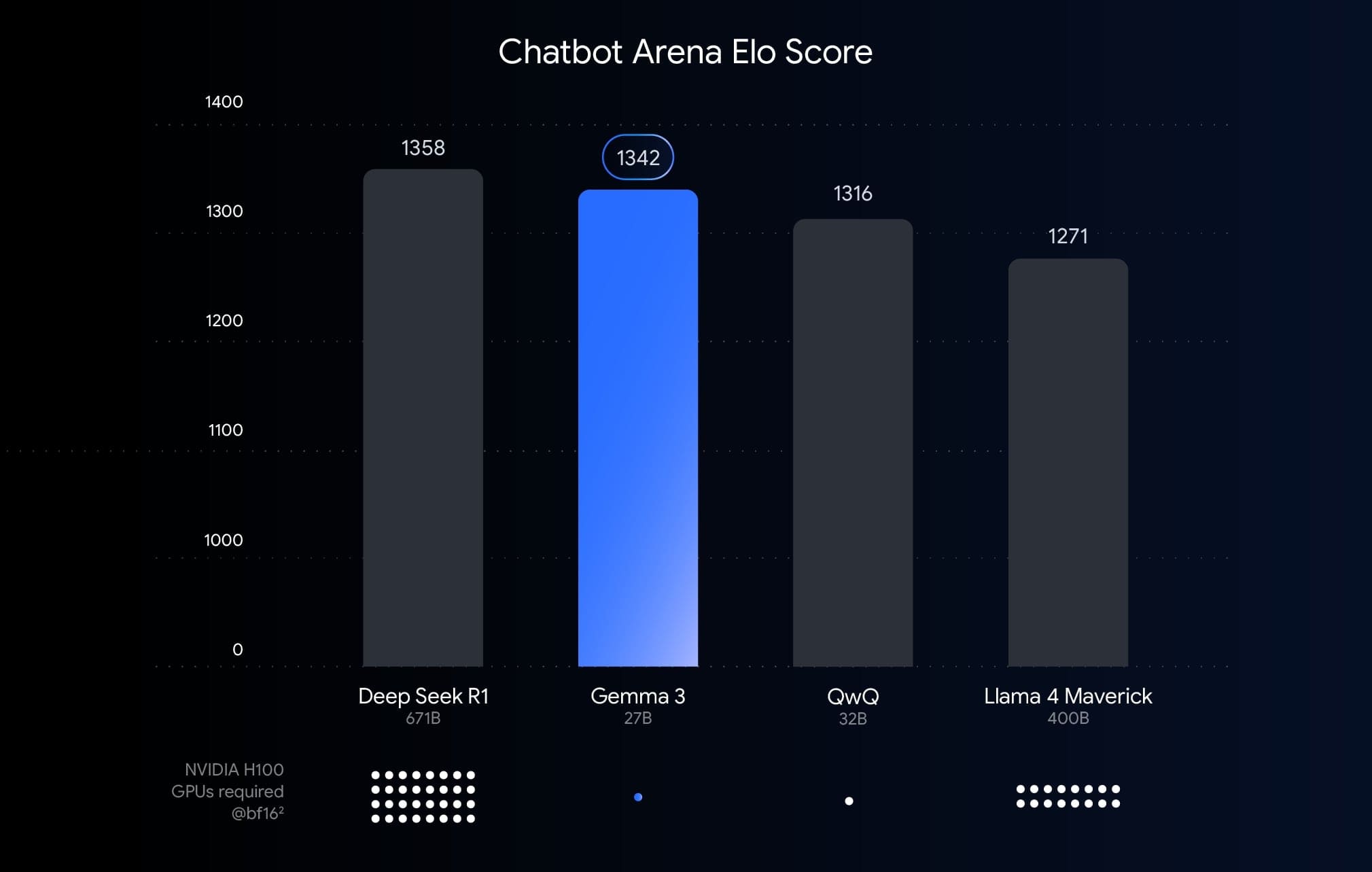
Navzdory svým relativně skromným hardwarovým požadavkům se modely Gemma 3 mohou pochlubit impozantním výkonem. V benchmarcích jako MMLU (Massive Multitask Language Understanding) dosahuje 27B model výsledků, které jsou konkurenceschopné i s mnohem většími modely. Konkrétně v testech rozumění textu, logického uvažování a řešení problémů dosahuje Gemma 3 27B skóre, které je srovnatelné s modely majícími 70 miliard parametrů, ale s výrazně nižšími nároky na výpočetní zdroje.
Dostupné varianty modelů
Google vydává kvantizované modely Gemma 3 ve třech velikostech:
- Gemma 3 2B: nejmenší a nejrychlejší model vhodný pro jednoduché aplikace.
- Gemma 3 9B: střední model nabízející dobrý kompromis mezi výkonem a rychlostí.
- Gemma 3 27B: největší model s nejvyšším výkonem, přesto provozovatelný na GPU RTX 3090.
Všechny modely jsou k dispozici ve verzích optimalizovaných pro 4bitovou a 8bitovou kvantizaci, což umožňuje vývojářům zvolit vhodnou variantu podle dostupného hardwaru a požadovaného výkonu.
Co to znamená pro ekosystém AI
Tento krok Googlu je významný pro celý ekosystém umělé inteligence. Přístup k výkonným modelům umožní mnohem širší komunitě vývojářů experimentovat s pokročilou AI technologií. "Naším cílem je zpřístupnit state-of-the-art AI co nejširšímu publiku," uvedli inženýři Googlu na svém vývojářském blogu. "Díky kvantizačním technikám použitým při trénování modelů Gemma 3 se nyní mohou i vývojáři bez přístupu k drahému specializovanému hardwaru zapojit do vytváření inovativních AI aplikací."
Jak začít s Gemma 3
Modely jsou k dispozici prostřednictvím Hugging Face a Google Cloud. Vývojáři mohou využít připravené integrační nástroje pro TensorFlow a PyTorch, které usnadňují implementaci modelů do vlastních aplikací. Google také poskytuje podrobnou dokumentaci a ukázkové projekty, které demonstrují praktické využití modelů Gemma 3 v různých scénářích - od generování textu přes chatboty až po asistenci při programování.





