
V oblasti umělé inteligence se objevují nové testy, které kontrolují, jak dobře modely zvládají fakta. Nový benchmark od společnosti Artificial Analysis testoval 40 velkých jazykových modelů a výsledky nejsou příliš povzbudivé. Jen čtyři z nich dosáhly kladného skóre v indexu nazvaném Omniscience Index, který se pohybuje od -100 do +100. Na prvním místě se umístil model Gemini 3 Pro od Googlu s 13 body. Za ním následuje Claude 4.1 Opus s 4,8 body, pak GPT-5.1 a Grok 4. Tento index měří, jak spolehlivě modely poskytují správné informace z různých oblastí.
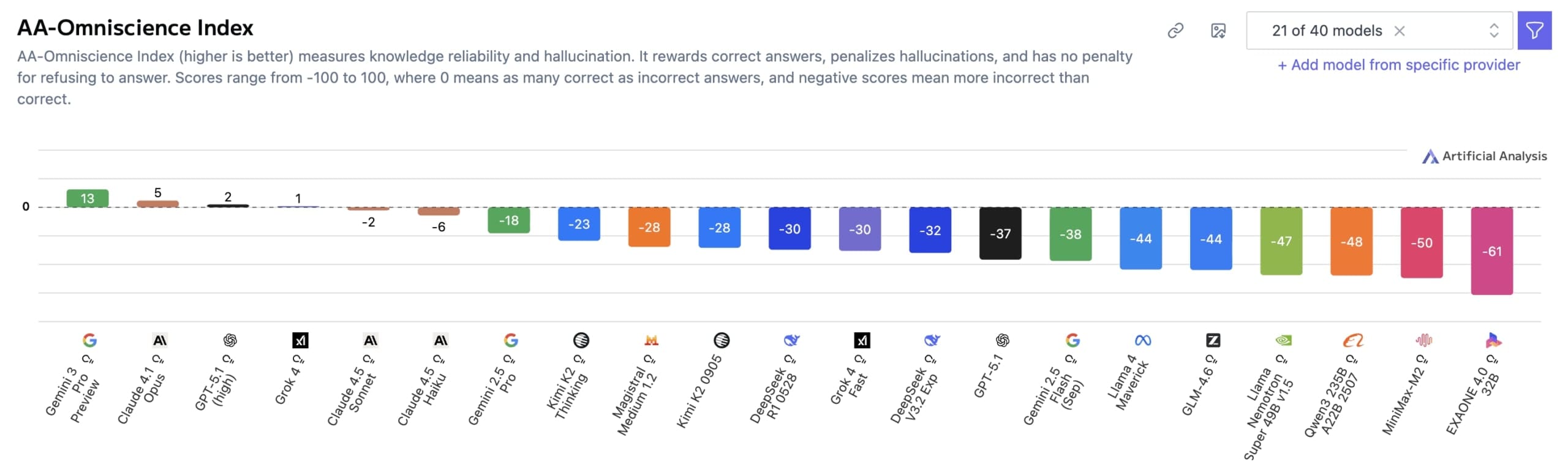
Gemini 3 Pro dosáhl takového vedení hlavně díky své přesnosti, která činí 53 %. To je o 14 bodů více než u předchozího lídra, modelu Grok 4. Výzkumníci z Artificial Analysis to vysvětlují tím, že přesnost souvisí s velikostí modelu – větší modely jako Gemini 3 Pro mají lepší pokrytí faktů. Skóre 0 by znamenalo, že model odpovídá správně a špatně stejně často. Benchmark zahrnuje 6000 otázek ze 42 témat v šesti oblastech: obchod, humanitní a společenské vědy, zdraví, právo, softwarové inženýrství a věda s matematikou. Otázky pocházejí z důvěryhodných akademických a průmyslových zdrojů a byly vytvořeny automaticky AI agentem.
Halucinace jsou hlavní problém AI
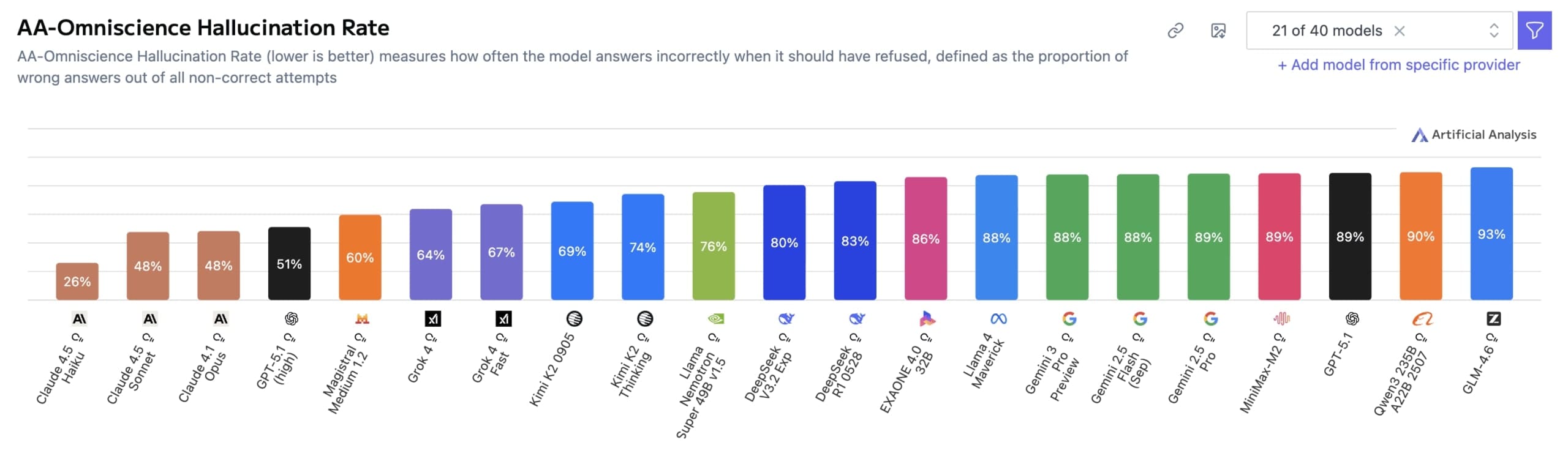
Přestože Gemini 3 Pro vede v přesnosti, jeho největší slabinou zůstávají halucinace – to znamená, že model často poskytuje nesprávné odpovědi s velkou jistotou, místo aby přiznal, že něco neví. Jeho míra halucinací dosahuje 88 %, což je stejné jako u modelů Gemini 2.5 Pro a Gemini 2.5 Flash. Například GPT-5.1 (high) má 81 % a Grok 4 64 %. To znamená, že mezi všemi špatnými odpověďmi je velká část těch, kde model vymýšlí fakta místo přiznání nevědomosti.
Claude 4.1 Opus dosáhl přesnosti 36 %, ale s jednou z nejnižších mír halucinací, což mu dříve zajišťovalo první místo. Výzkumníci zdůrazňují, že vysoká míra halucinací je problémem napříč všemi testovanými modely. Halucinace zde znamená podíl chybných odpovědí mezi všemi nesprávnými pokusy, což ukazuje na přílišnou sebejistotu modelů.
Špatná odpověď? Dostaneš trest!
Tento benchmark se liší od běžných testů tím, že trestá špatné odpovědi stejně silně, jako oceňuje ty správné. Běžné metody často podporují hádání, což zvyšuje halucinace. V Omniscience Index nedostanete body za přiznání nevědomosti, ale ani trest – naopak špatné odpovědi vedou k velkým odpočtům. To má podpořit opatrnost modelů.
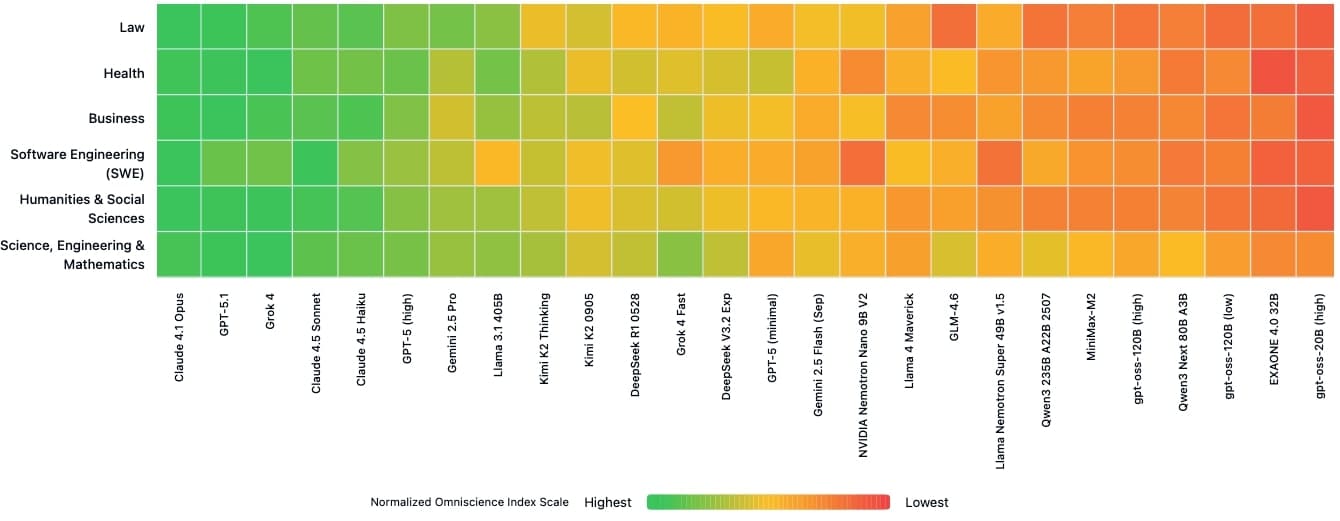
Výsledky dělí modely do čtyř skupin: ty s rozsáhlými znalostmi a vysokou spolehlivostí jako je Claude 4.1 Opus, ty se znalostmi ale nízkou spolehlivostí jako je Claude 4.5 Haiku, ty s omezenými znalostmi ale konzistentní spolehlivostí jako je GPT-5.1 a malé modely bez znalostí i spolehlivosti, například OpenAI’s lightweight gpt-oss. Pro Gemini 3 Pro není dostupný detailní rozbor podle oblastí.
Starší model Llama překvapuje dobrými výsledky
Obecná inteligence nemusí znamenat spolehlivost ve faktech. Modely jako Minimax M2 nebo gpt-oss-120b (high) si vedou dobře v širším indexu inteligence od Artificial Analysis, ale v Omniscience Index selhávají kvůli vysokým halucinacím. Naopak starší model Llama-3.1-405B dosáhl dobrého skóre, přestože v celkových hodnoceních obvykle zaostává za novějšími modely.
Žádný model nevynikal konzistentně ve všech šesti oblastech. Claude 4.1 Opus vedl v právu, softwarovém inženýrství a humanitních vědách, GPT-5.1.1 v obchodních otázkách a Grok 4 ve zdraví a vědě. Tyto rozdíly znamenají, že celkové hodnocení může skrývat důležité mezery.
Velikost modelu neznamená vždy lepší spolehlivost
Větší modely obvykle dosahují vyšší přesnosti, ale ne nutně nižší halucinace. Několik menších modelů, jako Nvidia’s Nemotron Nano 9B V2 nebo Llama Nemotron Super 49B v1.5, překonalo mnohem větší konkurenty v Omniscience Index. Artificial Analysis potvrdilo, že přesnost souvisí s velikostí, ale halucinace ne. Proto Gemini 3 Pro, přes svou vysokou přesnost, stále často halucinuje.
Z hlediska nákladů vyniká Claude 4.5 Haiku s lepším skóre než dražší modely jako GPT-5.1 (high) nebo Kimi K2 Thinking. Výzkumníci zveřejnili 10 % otázek jako veřejný dataset na Hugging Face, zbytek zůstává soukromý, aby se zabránilo kontaminaci trénovacích dat. Související studie odhalila chyby v existujících benchmarkách, jako jsou nejasné definice termínů nebo nedostatečné statistické ověření.
Zdroj: the-decoder.com





