
DeepSeek V3.1: Nejsilnější otevřený AI model roku 2025?
Ať už jste vývojář, který hledá levný nástroj pro složité úlohy, nebo jen zvědavý nadšenec do umělé inteligence, nový model DeepSeek V3.1 vás donutí se zastavit a zamyslet. Tento čínský kolos s 685 miliardami parametrů přináší výkon srovnatelný s těmi nejdražšími proprietárními systémy, ale za zlomek ceny. Pojďme se podívat, co ho dělá tak výjimečným – a proč kolem něj kolují spekulace o budoucnosti celé řady.
Technické specifikace
DeepSeek V3.1 je masivní jazykový model (LLM) s celkově 685 miliardami parametrů, přičemž během inference aktivuje přibližně 37 miliard z nich díky architektuře Mixture-of-Experts (MoE, směs expertů). To znamená, že model je efektivní a nespotřebovává zbytečně mnoho výpočetní síly – na jeden token připadá jen zlomeček celkové kapacity. Velkým vylepšením oproti předchozí verzi V3 je rozšířené kontextové okno na 128 000 tokenů, což odpovídá zpracování informací zhruba z 300stránkové knihy v jednom sezení. Tento model prošel dvoufázovým trénováním na dlouhých kontextech: nejprve 630 miliard tokenů pro rozšíření na 32k a pak dalších 209 miliard pro plných 128k.
Společnost DeepSeek, založená podnikatelem Liang Wenfengem jako vedlejší projekt jeho firmy zabývající se kvantitativním obchodováním, tento update oznámila jen krátkou zprávou v jedné ze svých WeChat skupin. Žádná velká tisková konference, žádné fanfáry na sociálních sítích jako X – prostě tichý release, který okamžitě upoutal pozornost. Model podporuje různé formáty přesnosti, včetně BF16 (Brain Float 16, 16bitový formát od Google), F8_E4M3 (8bitový formát s plovoucí desetinnou čárkou) a F32 (standardní 32bitová přesnost), což umožňuje optimalizaci pro různý hardware. Navíc využívá FP8 microscaling pro efektivní inference ve velkém měřítku, což zrychluje odpovědi a snižuje náklady.
Myšlení a rychlé odpovědi v jednom balení
Co dělá DeepSeek V3.1 opravdu zajímavým, je jeho hybridní architektura. Model umí plynule přepínat mezi "myšlenkovým" režimem (chain-of-thought reasoning, řetězec myšlenek, podobný předchozímu R1) a "non-thinking" režimem pro přímé, rychlé odpovědi. Stačí upravit prompt (vstupní instrukci) nebo použít boolean přepínač "reasoning enabled" v API. Tento přístup pokrývá širokou škálu úkolů – od běžného chatu přes složité logické problémy až po použití nástrojů jako webové vyhledávání nebo kódování.
Na rozdíl od předchozích verzí, kde byly potřeba samostatné modely pro konverzace (jako DeepSeek-V2) a uvažování (DeepSeek-R1), teď všechno běží v jednom systému. Model je natrénován pro nativní podporu programování a agentů (autonomních systémů), což ho dělá ideálním pro vývojáře. Podle testů na benchmarku Aider Polyglot překonává dokonce Claude 4 Opus v komplexních programovacích úkolech s více jazyky, s úspěšností 71,6 % v testech Aider. A to všechno s vyšší efektivitou tokenů a rychlejšími odpověďmi než u R1.
Levnější než konkurence, ale stejně silný
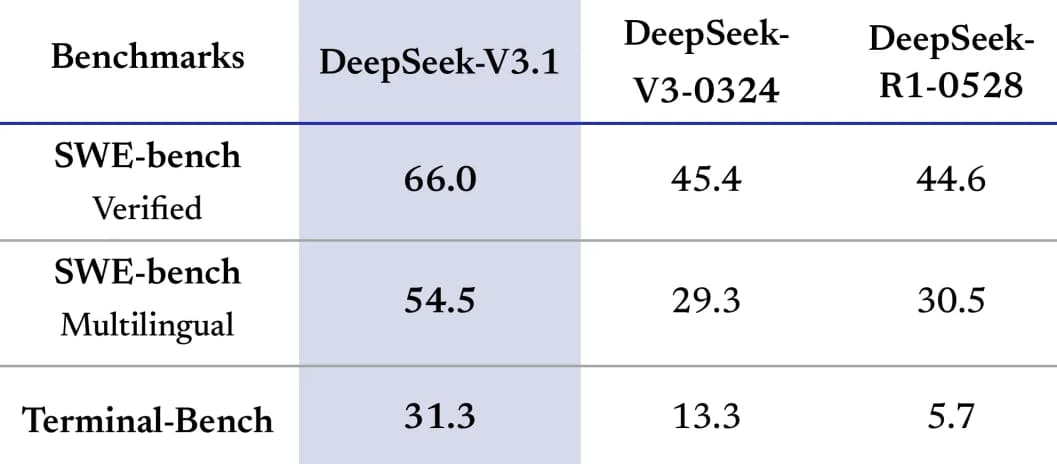
DeepSeek V3.1 dosahuje výkonu srovnatelného s proprietárními modely jako Claude Opus 4, přičemž na benchmarku SWE-bench skóruje 71,6 %. V matematických testech jako AIME 2024 nebo MATH 500 překonává mnoho soupeřů díky silným schopnostem logického uvažování – například řeší úlohy jako poskakující míček v rotujícím šestiúhelníku. Je to nejlepší non-TTC (non-tool-tuned coding) model ve své třídě pro programování.
A teď to nejchytlavější: cena. Přes API stojí 0,56 USD (přibližně 12,32 Kč) za milion vstupních tokenů a 2,19 USD (asi 48,18 Kč) za milion výstupních. To je asi 68krát levnější než Claude Opus, kde ekvivalentní úloha vyjde na zhruba 70 USD (kolem 1 540 Kč). Trénování předchozí verze V3 stálo jen 5,6 milionu USD (přibližně 123,2 milionu Kč), což je zlomek nákladů amerických laboratoří. Model je dostupný na Hugging Face pod licencí MIT pro komerční použití, přes webové rozhraní na chat.deepseek.com s funkcí “DeepThink” nebo přes OpenRouter API.
Spekulace o R2: Kam zmizel R1 a co dál?
Zajímavostí je, že DeepSeek odstranil všechny reference na model R1 z funkce “deep think” ve svém chatbotu. To vyvolalo spekulace o osudu očekávaného následníka R2. Společnost, která V3 vydala v prosinci a R1 v lednu, teď přináší jen inkrementální updaty, zatímco konkurenti jako OpenAI nebo Anthropic chrlí nové modely. Podle článku Bena Jianga v South China Morning Post to naznačuje možný posun v badatelském zaměření firmy. Patrick Zandl na marigold.cz poznamenává, že tichý launch V3.1 by mohl být strategií zaměřenou na komunitní validaci spíš než na velké oznámení.
Geopolitické aspekty nelze přehlížet – americké firmy mohou váhat kvůli napětí mezi USA a Čínou, ačkoli model je otevřený. Navíc velikost 700 GB činí lokální hostování náročným, takže většina uživatelů se spolehne na cloudové API. Přesto komunita na Hugging Face model rychle přijala, s více než 80 000 sledujícími krátce po vydání.





