
Na platformě OpenRouter se objevil model, o kterém nikdo nic nevěděl. Žádné oficiální oznámení, žádný blogový příspěvek, jen tichý záznam s názvem Pony Alpha. Model byl zdarma k použití a nabízel 200 000 tokenů kontextu s maximálním výstupním oknem 131 000 tokenů, což bylo absurdní číslo i podle standardů roku 2026.
Během čtyř dnů uživatelé spálili 25 miliard prompt tokenů. Propustnost se pohybovala kolem 17 až 19 tokenů za sekundu. Tři nejpoužívanější aplikace byly Kilo Code (10 miliard tokenů), OpenClaw (8,59 miliardy) a SillyTavern (2,83 miliardy). Lidé model používali na vše od programování až po hraní rolí.
Nikdo nevěděl, kdo ho vytvořil. Komunita začala pátrat a nakonec odhalila pravdu: Pony Alpha byl ve skutečnosti GLM-5 od čínské společnosti Zhipu AI.
Zhipu AI a model GLM-5
Společnost Zhipu AI (také známá jako Knowledge Atlas Technology JSC Ltd.) oficiálně představila svůj model GLM-5 před lunárním novým rokem 2026. Jde o pátou generaci jejich modelové řady GLM, která navazuje na úspěšné modely GLM-3 a GLM-4.
GLM-5 využívá architekturu Mixture-of-Experts (MoE) s celkovým počtem 745 miliard parametrů, ale při každém tokenu se aktivuje pouze přibližně 44 miliard parametrů. Tato struktura přináší dva hlavní benefity: latence prvního tokenu je srovnatelná s modely o velikosti 30–70 miliard parametrů, a zároveň model udržuje stabilitu při dlouhých výstupech.
GLM-5 přináší výrazná zlepšení v několika oblastech:
Logické uvažování: Model častěji používá strukturu chain-of-thought (řetězec myšlenek), i když o to uživatel explicitně nepožádá. Když je požádán o kritiku vlastního plánu, dokáže se přizpůsobit bez opakování nebo zacyklení.
Programování: Model lépe zvládá postupné úpravy kódu než kompletní přepisy. Když je požádán o změnu ve stylu diff, zachová kontext místo přetisknutí celého kódu.
Agentní chování: Úkoly ve stylu volání nástrojů (popis kroků, identifikace chybějících vstupů, návrh opakování) vycházejí jasněji a strukturovaněji.
Kreativní psaní: Kontrola hlasu se zlepšila. Pokud uživatel nastaví tón textu, model ho dokáže udržet po několik stránek.
Výkon a rychlost
Model GLM-5 vykazuje stabilní výkon napříč různými úkoly. Latence prvního tokenu se pohybuje pod jednou sekundou u krátkých promptů a 1–2 sekundy u složitějších požadavků s vícedílnými instrukcemi. Trvalá propustnost při dlouhých odpovědích dosahuje 30–60 tokenů za sekundu. Model nezastavuje uprostřed odstavce, jak se to stává u některých MoE modelů pod zátěží. Při kontextu kolem 8–16 000 tokenů zůstávají výstupy koherentní. Architektura MoE znamená kompromis mezi jednoduchostí hustých modelů a směrovací vrstvou, která se ideálně vyplatí v rychlosti a nákladech při stejné úrovni kvality.
Přístup přes API
Model GLM-5 je dostupný prostřednictvím platformy Zhipu AI a některých agregátorů jako WaveSpeed, který poskytuje rozhraní kompatibilní s OpenAI. Integrace je jednoduchá – stačí změnit základní URL a řetězec modelu.
Model ID je uveden jako "glm-5" v katalogu modelů. Autentizace funguje pomocí jediného API klíče ve standardní hlavičce Authorization. Limity rychlosti se zobrazují v hlavičkách, což je užitečné při ladění souběžnosti.
Pro lepší stabilitu u složitých promptů se doporučuje snížit teplotu na 0,5–0,7. To redukuje meandrování bez zploštění tónu. Výchozí limit výstupních tokenů je konzervativní, takže pokud se odpovědi zkracují, je třeba ho zvýšit.
Srovnání s konkurencí
Ve srovnání s řadou GPT drží GLM-5 krok v psaní a postupném uvažování. Dělá méně formátovacích chyb v dlouhých obrysech a zvládá postupné úpravy kódu s menším přesahem.
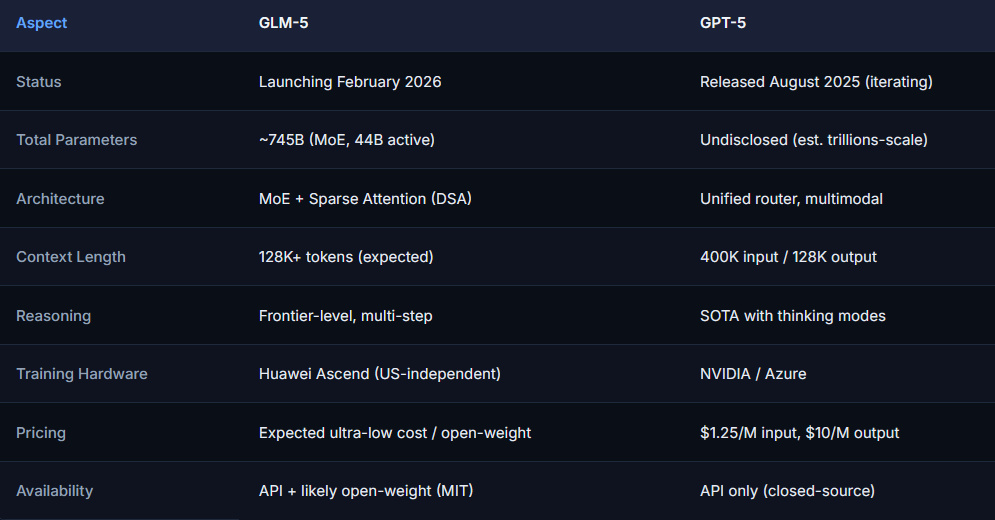
Oproti modelům Claude je GLM-5 podobně opatrný při faktických přepisech a je o něco ochotnější navrhovat další kroky bez vyzvání. Pokud uživatelé preferují Claude pro tón a bezpečnostní strukturu, mohou ho stále upřednostňovat pro citlivý obsah.
Ve srovnání s DeepSeek se GLM-5 cítí těžší na jedno volání, ale stabilnější při vícevrstvé analýze. DeepSeek může mít výhodu v nákladové efektivitě při velkém objemu malých dotazů, zatímco GLM-5 dává smysl pro méně, ale hlubší volání.
Domácí čipy a nezávislost
Společnost Zhipu AI oznámila, že její open-source model pro generování obrázků GLM-Image je prvním špičkovým multimodálním modelem, který dokončil trénink pomocí čipů Ascend od Huawei Technologies. Model byl založen na serveru Huawei Ascend Atlas 800T A2 a frameworku MindSpore. Toto oznámení představuje významný milník pro Huawei, protože žádná jiná velká AI firma v Číně veřejně neoznámila úspěch v trénování svých modelů na domácích čipech. Po zařazení na americký černý seznam v roce 2025 Zhipu AI zintenzivnilo své úsilí o spolupráci s domácími výrobci čipů včetně Cambricon Technologies.
Krok Zhipu AI je v souladu s politikou Pekingu snížit závislost na zahraniční expertíze ve světle víceleté kampaně USA a jejich spojenců omezit přístup Číny k pokročilým technologiím ze Západu.
Využití modelu GLM-5
Model GLM-5 je vhodný pro uživatele, kteří potřebují méně modelů a stabilnější výstupy při plánování, analýze a psaní náročném na revize. Pokud někdo optimalizuje pro ultra-levné, ultra-rychlé mikro-úkoly, menší hustý model nebo možnost ve stylu DeepSeek může sloužit lépe.
Dostupnost: GLM-5 se postupně zavádí a je přístupný prostřednictvím platformy Zhipu a některých agregátorů. Mimo Čínu se může latence a přístup lišit podle poskytovatele.
Kontextové okno: Pracovní rozsahy kolem 8–16 000 tokenů byly stabilní. Pro pracovní postupy závislé na velmi dlouhých kontextech je třeba potvrdit pevné limity v dokumentaci.
Část, která vynikla, nebyla surová síla, ale skutečnost, že model nevyžaduje neustálý dohled. To není senzační zpráva, ale druh tichého zlepšení, které se sčítá během týdne.
Zdroje: wavespeed.ai a finance.yahoo.com





