
Čínský MiniMax-M1 překonává konkurenci efektivním zpracováním 1M tokenů
Model vychází z předchozího MiniMax-Text-01 modelu a obsahuje celkem 456 miliard parametrů, přičemž na jeden token je aktivováno 45,9 miliard parametrů. Tato architektura umožňuje modelu nativně podporovat kontext o délce až 1 milion tokenů, což představuje osminásobek kontextové velikosti modelu DeepSeek R1. Mechanismus Lightning Attention navíc umožňuje efektivní škálování výpočetního času během testování.

Technické inovace: Lightning Attention mechanismus
Lightning Attention představuje klíčovou inovaci modelu MiniMax-M1, která řeší dlouhodobý problém tradičních transformer architektur. Klasické softmax attention mechanismy trpí kvadratickou výpočetní složitostí, která činí kontinuální rozšiřování procesu uvažování náročným. MiniMax-M1 řeší tento problém hybridním přístupem, kde po každých sedmi transnormer blocích s lightning attention následuje jeden transformer blok s softmax attention.
Tento design teoreticky umožňuje efektivní škálování délek uvažování na stovky tisíc tokenů. Například ve srovnání s DeepSeek R1 spotřebovává M1 méně než 50 % FLOP (floating-point operations per second) při generování 64K tokenů a přibližně 25 % FLOP při délce 100K tokenů. Toto podstatné snížení výpočetních nákladů činí M1 výrazně efektivnějším jak během inference, tak během rozsáhlého RL (reinforcement learning) trénování.
Architektura a parametry modelu
Model MiniMax-M1 využívá sofistikovanou hybridní architekturu založenou na principu Mixture-of-Experts s 32 experty. Celkový počet 456 miliard parametrů s aktivací 45,9 miliard parametrů na token představuje optimální rovnováhu mezi výkonem a efektivitou. Model nativně podporuje kontextovou délku až 1 milion tokenů, což představuje významné rozšíření oproti současným open-source modelům zaměřeným na logické uvažování.
Vývoj modelu M1 probíhal ve třech hlavních fázích. Nejprve pokračovali v předtrénování MiniMax-Text-01 na 7,5T tokenech z pečlivě sestaveného korpusu zaměřeného na uvažování. Následně provedli supervised fine-tuning (SFT) pro vložení určitých vzorců chain-of-thought (CoT) uvažování, čímž vytvořili silný základ pro posilované učení, které představuje klíčovou fázi vývoje M1.
CISPO algoritmus: Revoluce v posilovaném učení
Jednou z nejdůležitějších inovací MiniMax-M1 je nový algoritmus pro posilované učení nazvaný CISPO (Clipped Importance Sampling Policy Optimization). Tento algoritmus opouští omezení trust region a místo toho ořezává váhy importance sampling pro stabilizaci tréninku. Přístup CISPO vždy využívá všechny tokeny pro výpočty gradientů, čímž dosahuje vyšší efektivity ve srovnání s algoritmy GRPO a DAPO.
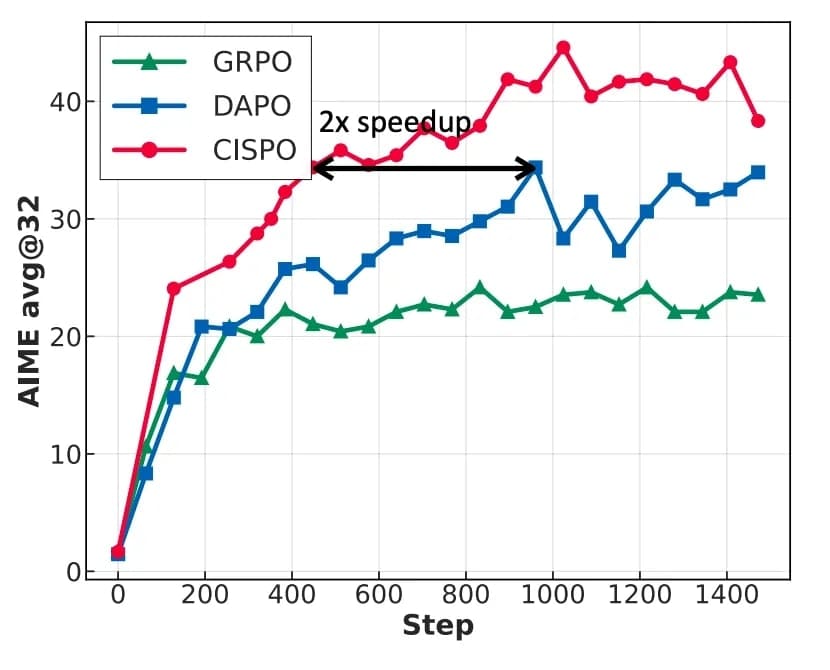
V kontrolované studii založené na modelech Qwen2.5-32B dosahuje CISPO dvojnásobného zrychlení ve srovnání s DAPO. Algoritmus byl navržen speciálně pro řešení problémů spojených s ořezáváním tokenů v původních PPO/GRPO algoritmech. Výzkumníci zjistili, že tokeny spojené s reflexivním chováním (například "However", "Recheck", "Wait", "Aha"), které často slouží jako "rozcestí" v cestách uvažování, byly typicky vzácné a základním modelem jim byly přiřazeny nízké pravděpodobnosti.
Výsledky benchmarků a srovnání
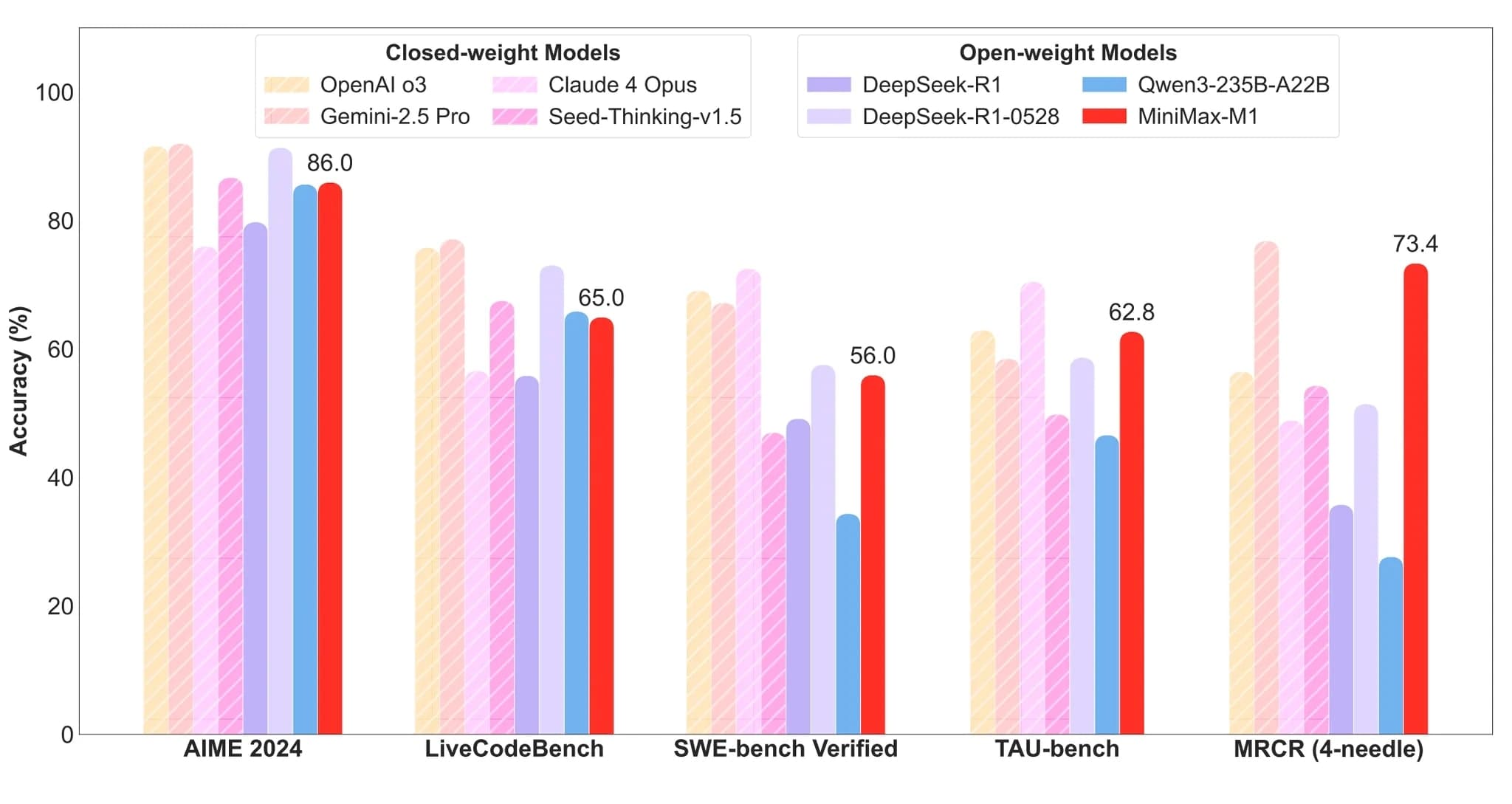
Model MiniMax-M1 dosahuje pozoruhodných výsledků napříč různými benchmarky. V matematickém uvažování MiniMax-M1-80k dosahuje 86,0 % na AIME 2024, čímž se řadí na druhé místo mezi open-weight modely a zaostává pouze za nejnovějším modelem DeepSeek-R1-0528. V obecném kódování se MiniMax-M1-80k vyrovnává Qwen3-235B na LiveCodeBench, zatímco ho překonává na FullStackBench.
Významných úspěchů dosahuje model v komplexních scénářích. Díky execution-based software engineering prostředím během RL dosahují MiniMax-M1-40k a MiniMax-M1-80k silných skóre 55,6 % a 56,0 % na SWE-bench verified. Využíváním svého 1M kontextového okna modely M1 výrazně překonávají všechny ostatní open-weight modely v porozumění dlouhému kontextu a dokonce překonávají OpenAI o3 a Claude 4 Opus.
Dostupnost a budoucí vývoj
Pro usnadnění spolupráce a pokroku v oboru společnost MiniMax zpřístupnila své modely veřejně na GitHub a Hugging Face. Modely jsou nyní podporovány frameworky vLLM i Transformers s podrobnými návody pro nasazení. Společnost také poskytuje komerční standardní API na minimax.io.
Výzkumníci trénovali dvě verze modelů MiniMax-M1 s maximální délkou generování 40K a 80K tokenů, což vedlo ke dvěma modelům MiniMax-M1-40k a MiniMax-M1-80k. MiniMax-M1-80k překonává MiniMax-M1-40k v komplexních matematických a kódovacích úlohách, což dále dokazuje výhody škálování test-time compute.
Při pohledu do budoucna, jak se test-time compute kontinuálně škáluje pro podporu stále složitějších scénářů, výzkumníci předpokládají významný potenciál takových efektivních architektur při řešení real-world výzev. Tyto zahrnují automatizaci firemních workflow a provádění vědeckého výzkumu. Real-world aplikace zvláště vyžadují LRM, které fungují jako agenti interagující s prostředími, nástroji, počítači nebo jinými agenty, což vyžaduje uvažování napříč desítkami až stovkami tahů při integraci long-context informací z různorodých zdrojů.





