
Alibaba Cloud představila něco, co si zaslouží pozornost. Qwen3.5-Omni je jejich nejnovější jazykový model a tentokrát nejde jen o text. Tenhle systém zpracovává obraz, zvuk, video i text zároveň, v jednom výpočetním proudu. Žádné lepení externích modulů dohromady, žádné přepisy zvuku stranou. Všechno běží pod jednou střechou.
A aby toho nebylo málo, Alibaba celý model uvolnila pod otevřenou licencí Apache 2.0. To znamená, že si ho může kdokoliv stáhnout, upravit a provozovat na vlastním hardwaru. Přesně tohle dělá z Qwen3.5-Omni tak zajímavý kousek.
Architektura Thinker-Talker
Srdcem modelu je dvousložková architektura, které tým říká Thinker-Talker. Modul Thinker vnímá okolí. Přijímá obrázky přes vizuální kodér, zvuk tokenizuje speciálním audio transformerem a celé to drží pohromadě díky časově orientovanému pozičnímu kódování (TMRoPE), které synchronizuje různé typy vstupů.
Modul Talker pak z těchto reprezentací generuje odpovědi, a to i hlasem v reálném čase. Celé to běží proudově, takže model nemusí čekat, až zpracuje kompletní vstup. Reaguje průběžně.
Pod kapotou pracuje hybridní Mixture-of-Experts (MoE) mechanismus. Z celkových 397 miliard parametrů se při jednom dotazu aktivuje jen asi 17 miliard. Představte si to jako obrovský tým specialistů, z nichž vždy pracují jen ti, které úkol zrovna potřebuje. Výsledek? Výkon srovnatelný s monolitickými giganty, ale za zlomek výpočetních nákladů.
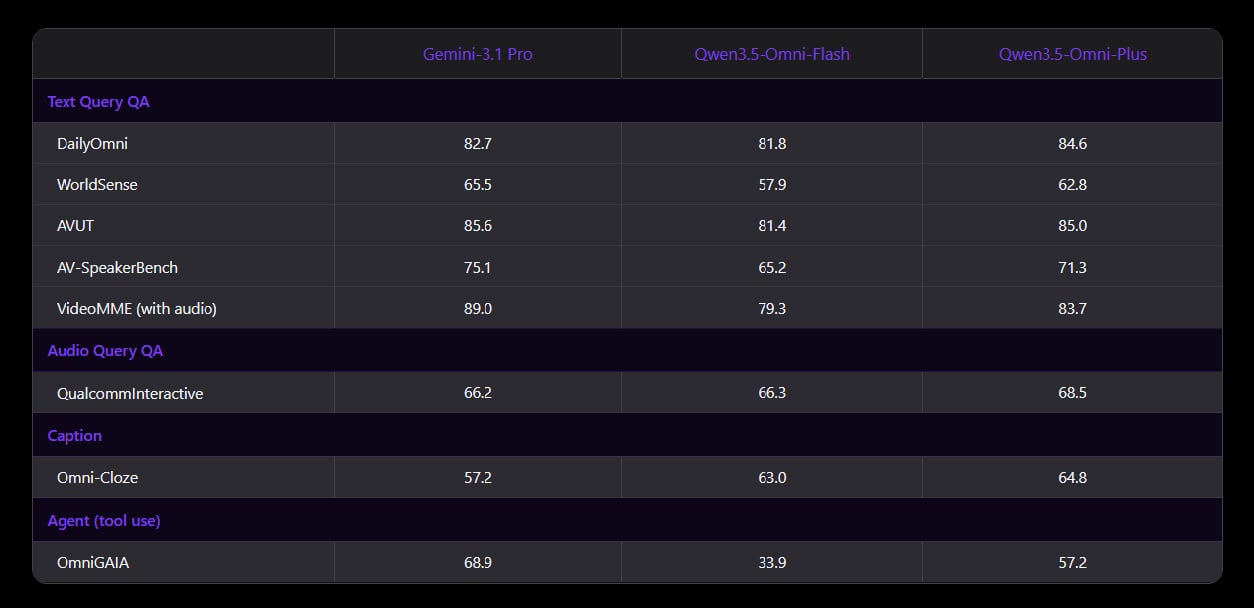
Lepší výsledky než konkurence
Qwen3.5-Omni-Plus dosáhl nejlepších výsledků ve 215 audio a audiovizuálních benchmarcích. V testu DailyOmni získal 84,6 bodu oproti 82,7 u Gemini 3.1 Pro. V rozpoznávání řeči na datasetu Librispeech dosáhl chybovosti pouhých 1,11 %, zatímco Gemini má 3,36 %.
V testu IFBench, který měří schopnost přesně plnit složité instrukce, verze Qwen3.5-397B dosáhla 76,5 % a překonala GPT-5 High se 73,1 %. V benchmarku MMLU-Pro, zaměřeném na hloubkovou expertízu, sice GPT-5 zatím vede s 87,1 %, ale Qwen mu s 86,3 % dýchá na záda.
Co ale manažery zajímá víc než benchmarky? Cena. API volání stojí méně než 0,11 dolaru za milion tokenů. To je zhruba desetina toho, co si účtuje konkurence. Při latenci prvního paketu kolem 234 milisekund navíc model odpovídá tak rychle, že konverzace s ním připomíná běžný rozhovor.
Čeština, která konečně nezní roboticky
Jedním z největších skoků je jazyková podpora. Model rozpoznává řeč ve 113 jazycích a dialektech a dokáže generovat hlas v 36 jazycích. Čeština patří mezi podporované jazyky, a to i na úrovni syntézy řeči.
Za přirozeností hlasu stojí technologie ARIA (Adaptive Rate Interleave Alignment), která dynamicky zarovnává textové a hlasové jednotky. Řeší problémy, které trápily starší modely: polykání koncovek, špatné skloňování číslovek nebo nepřirozené pauzy. Skóre přirozenosti hlasu (UTMOS) dosahuje 4,16 z 5, což se blíží lidskému projevu.
Zajímavá je i funkce sémantického přerušení. Když modelu skočíte do řeči, okamžitě ztichne a reaguje na váš nový podnět. Ignoruje přitom hluk v pozadí i výplňková slova. Kdo někdy zkoušel mluvit s hlasovým asistentem na rušné ulici, ocení to.
Vibe Coding: ukážeš, řekneš a dostaneš kód
Jedna z nejpůsobivějších ukázek? Takzvaný Audio-Visual Vibe Coding. Namíříte kameru na papírový náčrtek rozhraní, hlasem popíšete, co má aplikace dělat, a model vygeneruje funkční komponenty v Reactu nebo HTML. Prostě mu to ukážete a řeknete, co chcete. On to napíše.
Model přitom zvládne zpracovat přes 10 hodin audia nebo 400 sekund videa ve vysokém rozlišení v jednom kontextovém okně o délce 256 tisíc tokenů. To otevírá možnosti pro analýzu celých porad, přednášek nebo průmyslových videozáznamů bez ztráty kontextu.
Otevřený model
Uvolnění pod licencí Apache 2.0 je pro firmy, které pracují s citlivými daty (zdravotnictví, finance, státní správa), možnost provozovat model na vlastních serverech bez odesílání informací kamkoliv ven. To přímo řeší požadavky evropských pravidel pro ochranu dat.
Menší varianty modelu (třeba 35B parametrů) přitom vyžadují jen grafickou kartu s 24 GB paměti. S technikou FOMOE (Fast Opportunistic MoE) a inteligentním načítáním expertů z NVMe disků jde dokonce spustit i plnou verzi s 397 miliardami parametrů na běžné pracovní stanici. Dosáhnete rychlosti kolem 9 tokenů za sekundu, což pro firemního chatbota bohatě stačí.
Tři verze modelu
Model existuje ve třech velikostech: Plus, Flash a Light. Plus je vlajková loď pro maximální přesnost, Flash nabízí nejlepší poměr výkonu a rychlosti, Light se hodí pro nasazení s omezenými prostředky. Všechny podporují kontextové okno 256 tisíc tokenů.
Přistupovat k němu můžete přes offline API (dávkové zpracování, dlouhé dokumenty, detailní popisky videí) nebo Realtime API (živá interakce, hlasový asistent, volání funkcí a vyhledávání na webu). K dispozici je i přes Qwen Chat a Alibaba Cloud Model Studio.
Kdo se zajímá o kyberbezpečnost, toho potěší, že komunita už vytvořila i modifikované varianty bez bezpečnostních filtrů, vhodné třeba pro forenzní analýzu malwaru v izolovaném prostředí. Model si prostě žije vlastním životem a vývojáři z celého světa si ho přizpůsobují svým potřebám.





