
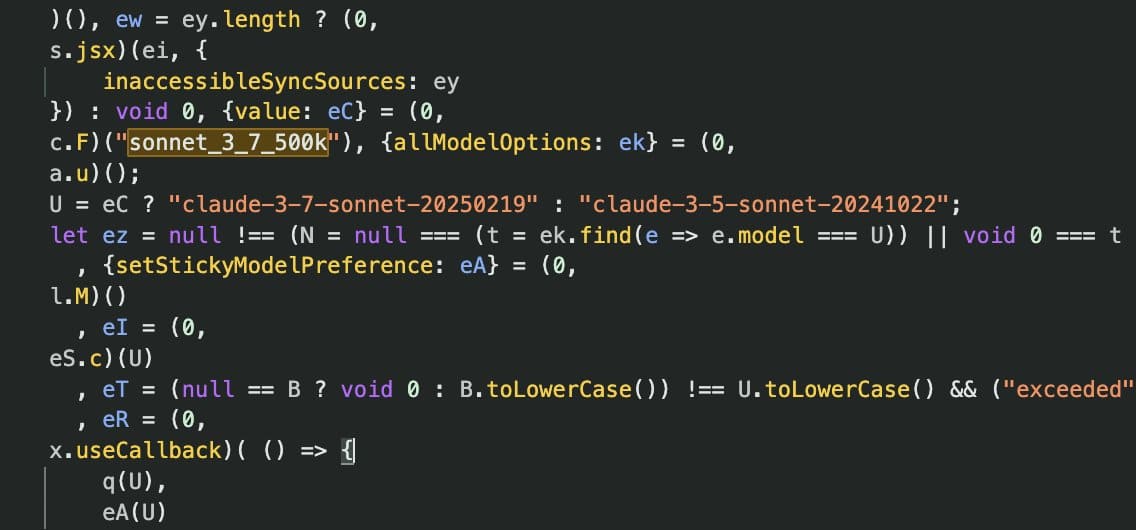
Anthropic chystá Claude 3.7 Sonnet s rekordním kontextovým oknem 500 000 tokenů
Společnost Anthropic se připravuje na významnou aktualizaci svého modelu Claude 3.7 Sonnet, která by mohla změnit způsob, jakým pracujeme s velkými jazykovými modely. Podle nedávno objevených příznaků ve funkčních vlajkách se zdá, že Anthropic plánuje zvýšit kontextové okno z dosavadních 200 000 tokenů na bezprecedentních 500 000 tokenů. Rozšířené kontextové okno umožní uživatelům vložit a zpracovat výrazně větší datové soubory nebo kódové základny v jediném sezení. To může být zlepšení zejména pro:
Analýzu rozsáhlých politických dokumentů
Agregaci a sumarizaci velkých souborů dat
Správu komplexních kódových základen s stovkami tisíc řádků kódu
Práci s obsáhlými vědeckými texty
Takto velké kontextové okno by také mohlo eliminovat potřebu spoléhat se na techniku RAG (Retrieval-Augmented Generation), která někdy může narušit pořadí kontextu.
Dostupnost nové funkce
Zatím není jasné, zda bude tato funkce nabízena pouze firemním zákazníkům, jak naznačují některé zprávy. Například vývojářské prostředí Cursor již údajně představilo možnost "Claude Sonnet 3.7 MAX" ve svém IDE.
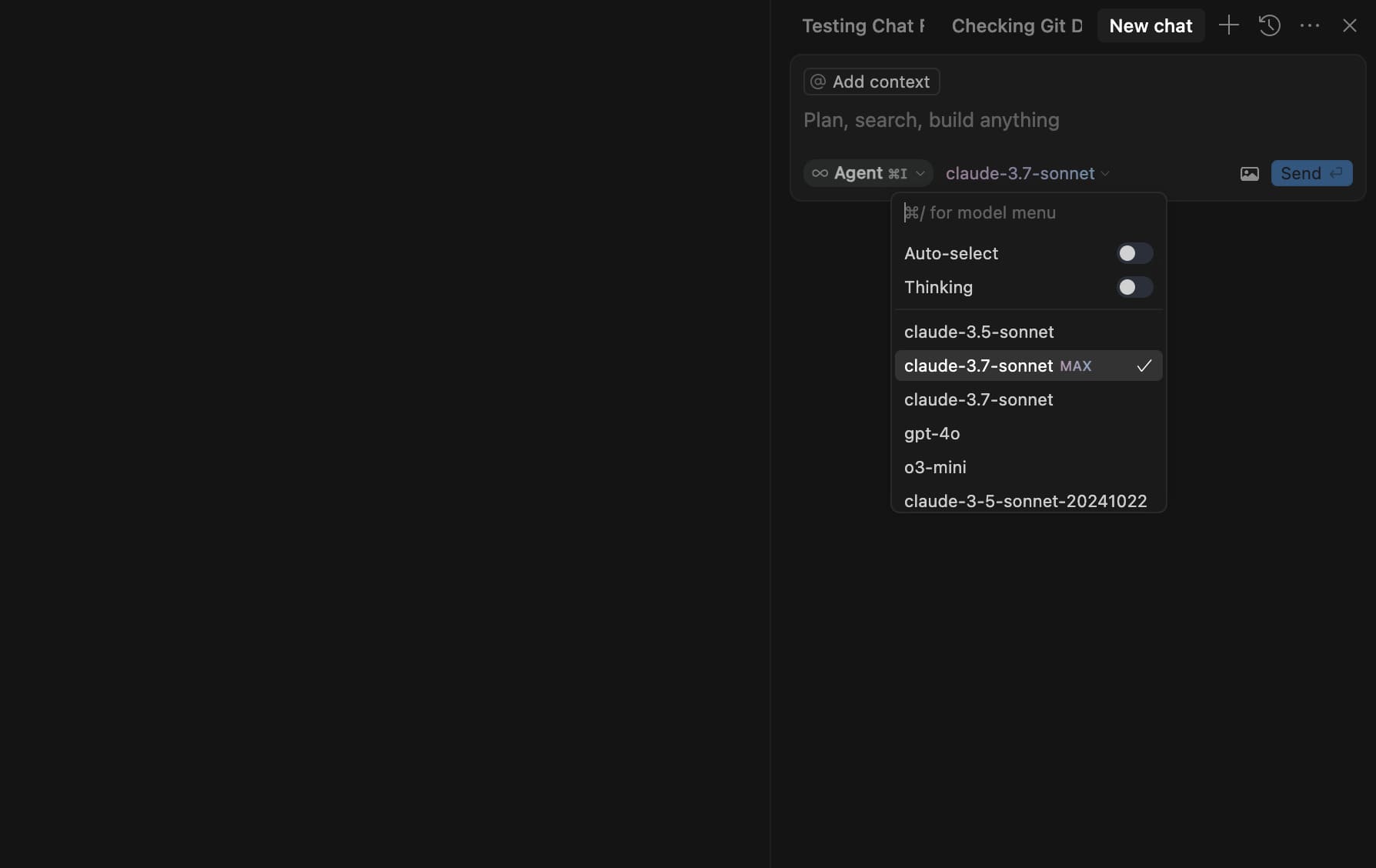
I když přesný termín vydání modelu s 500 000 tokeny zatím není znám, Anthropic historicky zaváděl nové funkce nejprve prostřednictvím podnikových plánů před širší dostupností. Pokud bude tato aktualizace široce implementována, mohla by předefinovat možnosti velkých jazykových modelů v kódování, výzkumu a analýze dat napříč odvětvími.
Souvislost s "vibe coding"
Načasování tohoto vývoje souvisí s nástupem tzv. "vibe codingu", termínu, který začátkem tohoto roku zavedl Andrej Karpathy. Tento přístup spoléhá na AI pro generování kódu na základě popisů v přirozeném jazyce místo manuálního programování. Rozšířené kontextové okno by mohlo tento trend dále posílit tím, že vývojářům umožní pracovat na větších projektech bez přerušení kontextu.





