
Představte si svět, kde programy bojují o přežití v malém virtuálním počítači. Právě to je jádro výzkumu od japonské společnosti Sakana AI, který se jmenuje Digital Red Queen (Digitální Rudá královna). Tento projekt využívá velké jazykové modely (LLM) k tomu, aby vytvářel a vyvíjel programy, které se navzájem ničí v hře zvané Core War. Cílem je prozkoumat, jak se umělá inteligence může adaptovat v nepřátelském prostředí, podobně jako v přírodě. Vědci chtějí pochopit dynamiku soutěže mezi AI systémy, což by mohlo pomoci v oblastech jako kybernetická bezpečnost. Spolupracují na tom s MIT a výsledky sdílejí v technické zprávě na arXiv.
Jak funguje hra Core War?
Core War je soutěžní programovací hra, která vznikla v roce 1984. V ní se programy nazývané "válečníci" (warriors) perou o kontrolu nad sdílenou pamětí virtuálního počítače, kterému se říká "Core". Každý válečník je napsaný v jazyce Redcode, což je speciální sestavovací jazyk. Hra funguje tak, že programy se střídají v provádění instrukcí, jedna po druhé. Úkolem válečníka je zůstat naživu a zároveň "havarovat" soupeře tím, že do jejich paměti zapíše neplatné příkazy, jako je DAT. Zajímavé je, že v Core War není rozdíl mezi kódem a daty – programy mohou měnit samy sebe nebo i soupeře během boje. To umožňuje triky jako sebe-replikace nebo modifikace přímo za běhu, ale vytváří to chaotické prostředí plné nestability. Hra je Turingovsky úplná, což znamená, že v ní lze teoreticky vytvořit libovolně složité strategie. Lidé v ní vymýšleli chytré taktiky, jako bombardování náhodných míst v paměti, sebe-rozmnožování nebo skenování Core na hledání nepřátel. Core War slouží jako testovací pole pro programátory, kteří zkoušejí, jak se jejich kódy chovají v soutěži, a teď ho Sakana AI používá k simulaci evolučních procesů s AI.
Pojem Rudé královny
Hypotéza Rudé královny pochází z evoluční biologie a je inspirovaná knihou Lewise Carrolla "Za zrcadlem", kde Rudá královna říká Alici: "Tady, víš, musíš běžet, co ti síly stačí, abys zůstala na místě." Tento koncept znamená, že druhy v přírodě se musí neustále vyvíjet, jen aby přežily proti svým soupeřům, kteří se také mění. Není to o tom, aby se zlepšily, ale aby udržely svou pozici v měnícím se světě. V přírodě to vidíme u virů, bakterií nebo zvířat, která se adaptují na nové hrozby. V tomto výzkumu Sakana AI aplikuje tuhle myšlenku na digitální svět: algoritmus Digital Red Queen (DRQ) nutí programy neustále se vyvíjet proti stále silnějším protivníkům, aby simuloval tenhle závod zbraní v umělé inteligenci.
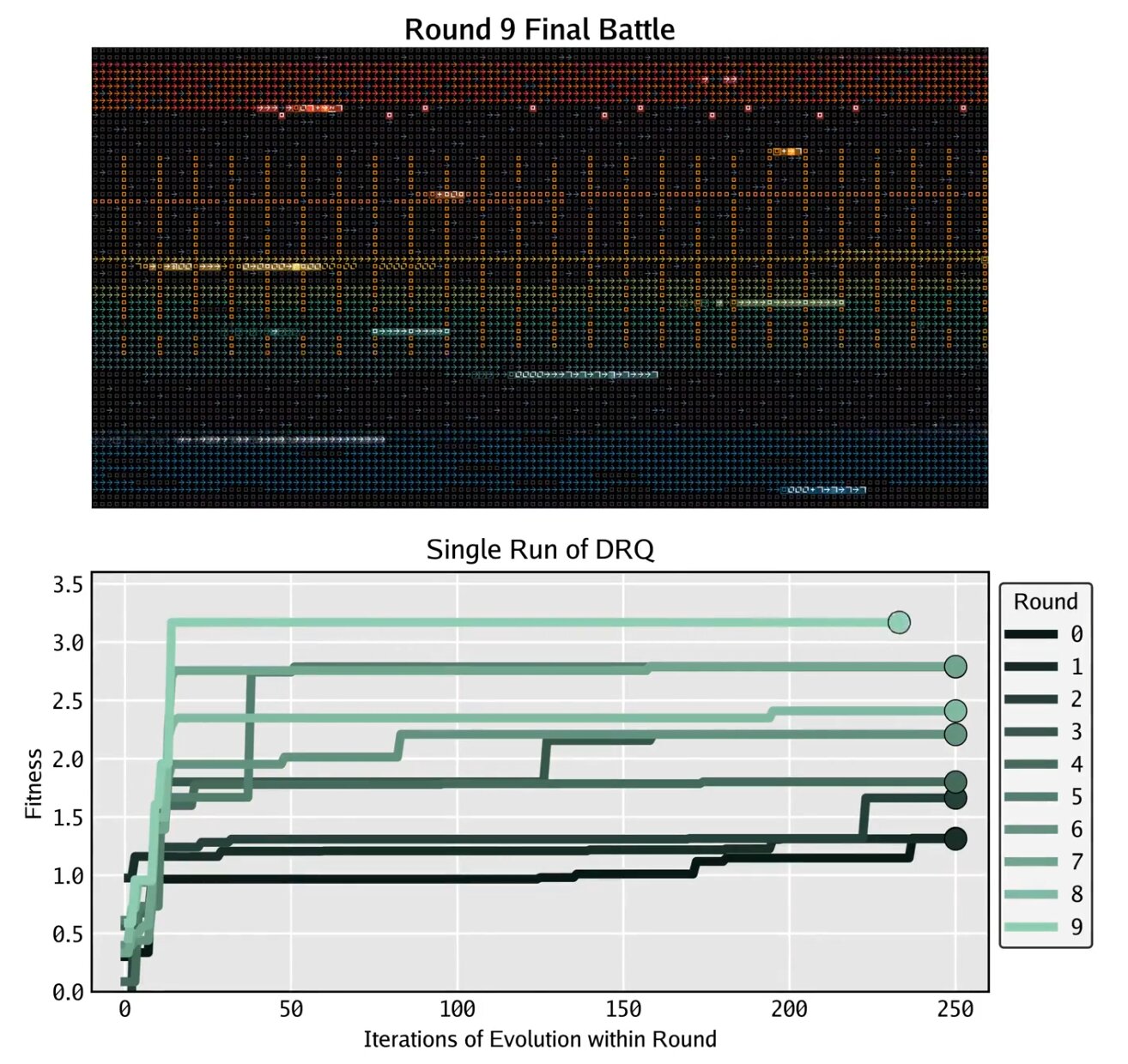
Jak to celé funguje?
Algoritmus DRQ od Sakana AI začíná jedním válečníkem a pak vytváří dalšího, který ho má porazit. Třetí válečník musí zvítězit nad prvními dvěma, a tak dál. Každý nový válečník se adaptuje na prostředí vytvořené všemi předchozími, což napodobuje neustálou změnu v přírodě. DRQ není nic nového – je to jednoduchá verze starších metod jako multi-agentní self-play, přizpůsobená pro Core War. Velké jazykové modely (LLM) zde generují tyto válečníky, což vede k objevům strategií jako cílené bombardování, sebe-replikace nebo masivní multithreading. Příklady z výzkumu zahrnují válečníky jako Ring Warrior Enhanced v9 nebo Spiral Bomber Optimized v22, kde komentáře v kódu vygenerovaly samy LLM. Vše se děje v bezpečném sandboxu, kde nic nemůže uniknout ven, protože programy běží na umělém stroji s umělým jazykem.
A co tedy vědci zjistili?
S více koly DRQ se válečníci stávají robustnějšími, což se měří jejich úspěšností proti lidmi navrženým válečníkům, které algoritmus nikdy neviděl. To umožňuje vytvářet lepší programy bez přímého tréninku na testovacích datech. Překvapivé je, že různé spuštění DRQ, každé s jiným startovním válečníkem, se časem sbližují k podobným chováním – ne na úrovni zdrojového kódu, ale v tom, jak fungují. To připomíná konvergentní evoluci v biologii, kde se podobné vlastnosti vyvinou nezávisle, jako křídla u ptáků a netopýrů nebo jed u pavouků a hadů. Vědci z Sakana AI zjistili, že tyto dynamiky Rudé královny vedou k objevům obecnějších strategií a naznačují, jak by se AI mohly vyvíjet v reálném světě. To by mohlo pomoci v automatickém testování systémů před nasazením nebo v simulacích pro umělou život, biologii, design léků, kybernetickou bezpečnost nebo tržní ekosystémy. Výzkum podtrhuje, že i jednoduché smyčky self-play odhalují složité taktiky, a navrhuje budoucí rozšíření na paralelní koevoluci velkých populací.





