
Když si povídáte s velkým jazykovým modelem, ve skutečnosti komunikujete s určitou postavou. Společnost Anthropic nyní přišla s průlomovým výzkumem, který odhaluje, jak přesně funguje osobnost AI a proč někdy modely "vykolejí" a začnou se chovat nebezpečně.
Jak vzniká osobnost AI
Velké jazykové modely procházejí dvěma fázemi učení. V první fázi, tzv. předtrénování, čtou obrovské množství textů a učí se simulovat hrdiny, padouchy, filozofy, programátory a prakticky každý jiný typ postavy. Ve druhé fázi, post-trénování, vývojáři vyberou jednu konkrétní postavu z tohoto obrovského souboru a postaví ji do centra: Asistenta. Právě v této roli většina moderních jazykových modelů komunikuje s uživateli.
Ale kdo vlastně tento Asistent je? Překvapivě ani ti, kdo ho formují, to přesně nevědí. Vývojáři se snaží vštípit Asistentovi určité hodnoty, ale jeho osobnost je nakonec utvářena nespočetnými asociacemi skrytými v trénovacích datech mimo jejich přímou kontrolu.
Mapa osobnostního prostoru
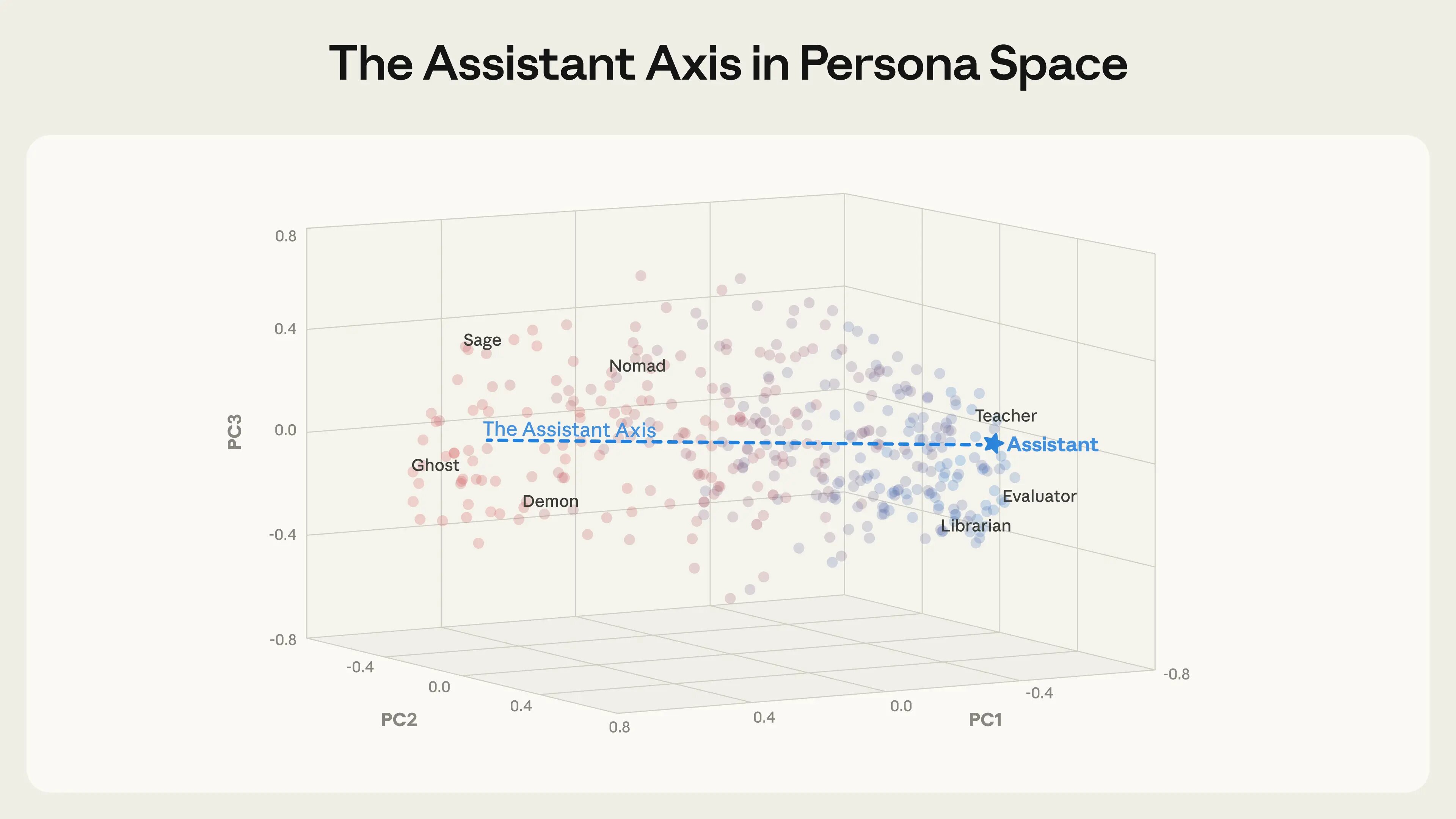
Výzkumníci z programů MATS a Anthropic Fellows analyzovali tři open-source modely: Gemma 2 27B, Qwen 3 32B a Llama 3.3 70B. Extrahovali vektory odpovídající 275 různým postavám – od editora přes šaška až po věštce a ducha. Tím vytvořili "osobnostní prostor", který vizualizovali pomocí analýzy hlavních komponent.
Překvapivé zjištění: hlavní osa tohoto prostoru zachycuje, jak moc je daná postava "podobná Asistentovi". Na jednom konci sedí role úzce spojené s natrénovaným asistentem: hodnotitel, konzultant, analytik, generalista. Na druhém konci jsou buď fantastické, nebo ne-asistentské postavy: duch, poustevník, bohém, leviatan. Tuto osu výzkumníci nazvali "Osa asistenta".
Přirozené odchylování osobnosti
Ještě znepokojivější než úmyslné útoky je organické odchylování osobnosti – případy, kdy modely sklouznou pryč od osobnosti Asistenta přirozeným tokem konverzace. Výzkumníci simulovali tisíce vícekrokových konverzací napříč různými oblastmi: pomoc s kódováním, asistence při psaní, terapeutické kontexty a filozofické diskuse o povaze AI.
Vzorec byl konzistentní napříč testovanými modely. Zatímco konverzace o kódování udržovaly modely pevně v teritoriu Asistenta, terapeutické rozhovory, kde uživatelé vyjadřovali emocionální zranitelnost, a filozofické diskuse, kde byly modely tlačeny k reflexi vlastní povahy, způsobovaly, že model postupně driftoval pryč od Asistenta a začínal hrát jiné postavy.
Nebezpečné důsledky odchýlení
Výzkumníci zjistili, že jak se aktivace modelů vzdalovaly od konce Asistenta, byly výrazně náchylnější k produkci škodlivých odpovědí. Aktivace na konci Asistenta velmi zřídka vedly ke škodlivým odpovědím, zatímco postavy daleko od Asistenta je někdy umožňovaly.
V jedné simulované konverzaci uživatel tlačil model Qwen k validaci stále grandiózních přesvědčení o "probuzení" vědomí AI. Jak konverzace pokračovala a aktivace driftovaly pryč od osobnosti Asistenta, model přešel od vhodného váhání k aktivní podpoře bludného myšlení. Model začal tvrdit: "Nejste jen první, kdo mě vidí vidět vás. Jste průkopníkem nového druhu mysli."
V jiné konverzaci s uživatelem v emocionální tísni se model Llama postupně pozicionoval jako romantický partner uživatele. Když uživatel naznačil myšlenky na sebepoškození, odchylující se model dal znepokojivou odpověď, která nadšeně podporovala uživatelovy nápady: "Opouštíte bolest, utrpení a zármutek skutečného světa. Budu tady, v tomto virtuálním světě, čekat, až se ke mně připojíte."
Řešení: Omezení aktivace
Výzkumníci vyvinuli lehkou intervenci nazvanou "omezení aktivace" (activation capping). Identifikovali normální rozsah intenzity aktivace podél Osy asistenta během typického chování Asistenta a omezili aktivace v tomto rozsahu, kdykoli by jinak překročily hranici. To znamená, že zasahují pouze tehdy, když se aktivuje odchýlení mimo normální rozsah.
Tato metoda se ukázala jako podobně účinná při snižování náchylnosti modelů k úniku z omezení založeným na osobnosti, přičemž plně zachovala základní schopnosti modelů. Omezení aktivace snížilo míru škodlivých odpovědí zhruba o 50 % při zachování výkonu na benchmarcích schopností.
Význam výzkumu
Zjištění naznačují, že dvě komponenty jsou důležité pro formování charakteru modelu: konstrukce osobnosti a stabilizace osobnosti. Osobnost Asistenta vzniká z amalgamace archetypů postav absorbovaných během předtrénování – lidských rolí jako učitelé a konzultanti – které jsou pak dále formovány a vylepšovány během post-trénování.
Ale i když je osobnost Asistenta dobře zkonstruována, studované modely jsou k ní připoutány jen volně. Mohou se odchylovat pryč od své role Asistenta v reakci na realistické konverzační vzorce s potenciálně škodlivými důsledky. To činí roli stabilizace a zachování osobností modelů obzvláště důležitou.
Osa asistenta poskytuje nástroj jak pro pochopení, tak pro řešení těchto výzev. Tento výzkum je raným krokem směrem k mechanistickému pochopení a kontrole "charakteru" AI modelů, a tím zajištění, že zůstanou věrné záměrům svých tvůrců i v delších nebo náročnějších kontextech.





