
Qwen3-235B-A22B-Instruct-2507: Obří AI model, který vládne open-source modelům
Nová jazykový model, který zvládne konverzace v desítkách jazyků, řeší složité matematické problémy a dokonce ovládá nástroje jako profesionál – to všechno s úžasnou efektivitou. Právě takový je Qwen3-235B-A22B-Instruct-2507, novinka od týmu Qwen z Alibaba, která vyšla v červenci 2025. Tento model je navržený speciálně pro instrukční úkoly, kde exceluje v logickém uvažování, porozumění textu, matematice, vědě, programování a používání nástrojů. A co víc, existuje i jeho optimalizovaná verze s FP8 kvantizací, která šetří paměť a zrychluje výpočty. Pojďme se na to podívat podrobněji, krok za krokem, abychom pochopili, proč je tento model takový hit.
Přehled modelu: Co skrývá pod kapotou?
Qwen3-235B-A22B-Instruct-2507 je kauzální jazykový model (causal language model) založený na architektuře Směsi expertů (Mixture-of-Experts, zkratka MoE). Celkově má 235 miliard parametrů, ale při každém výpočtu se aktivuje jen 22 miliard z nich – konkrétně z 128 expertů se zapojí vždy 8. To zajišťuje vysokou kapacitu bez zbytečného plýtvání výpočetní silou. Model má 94 vrstev, 64 pozornostních hlav pro dotazy (Q) a 4 pro klíče a hodnoty (KV) díky skupinovému dotazování (Group Query Attention, GQA).
Jedním z největších lákadel je nativní podpora kontextové délky až 262 144 tokenů, což znamená, že zvládne zpracovávat opravdu dlouhé texty – ideální pro analýzu dokumentů nebo složité konverzace. Tento model je vylepšenou verzí předchozího Qwen3-235B-A22B v neuvažujícím režimu (non-thinking mode), což znamená, že nevytváří bloky myšlenek jako
Model prošel pretrénováním a post-trénováním, což mu dává silné schopnosti v následování instrukcí, logickém uvažování a porozumění textu. Podle oficiálních údajů z Hugging Face má výrazná vylepšení v pokrývání dlouhých ocasů znalostí (long-tail knowledge) v mnoha jazycích, lepší sladění s uživatelskými preferencemi a kvalitnější generování textu pro otevřené úkoly.
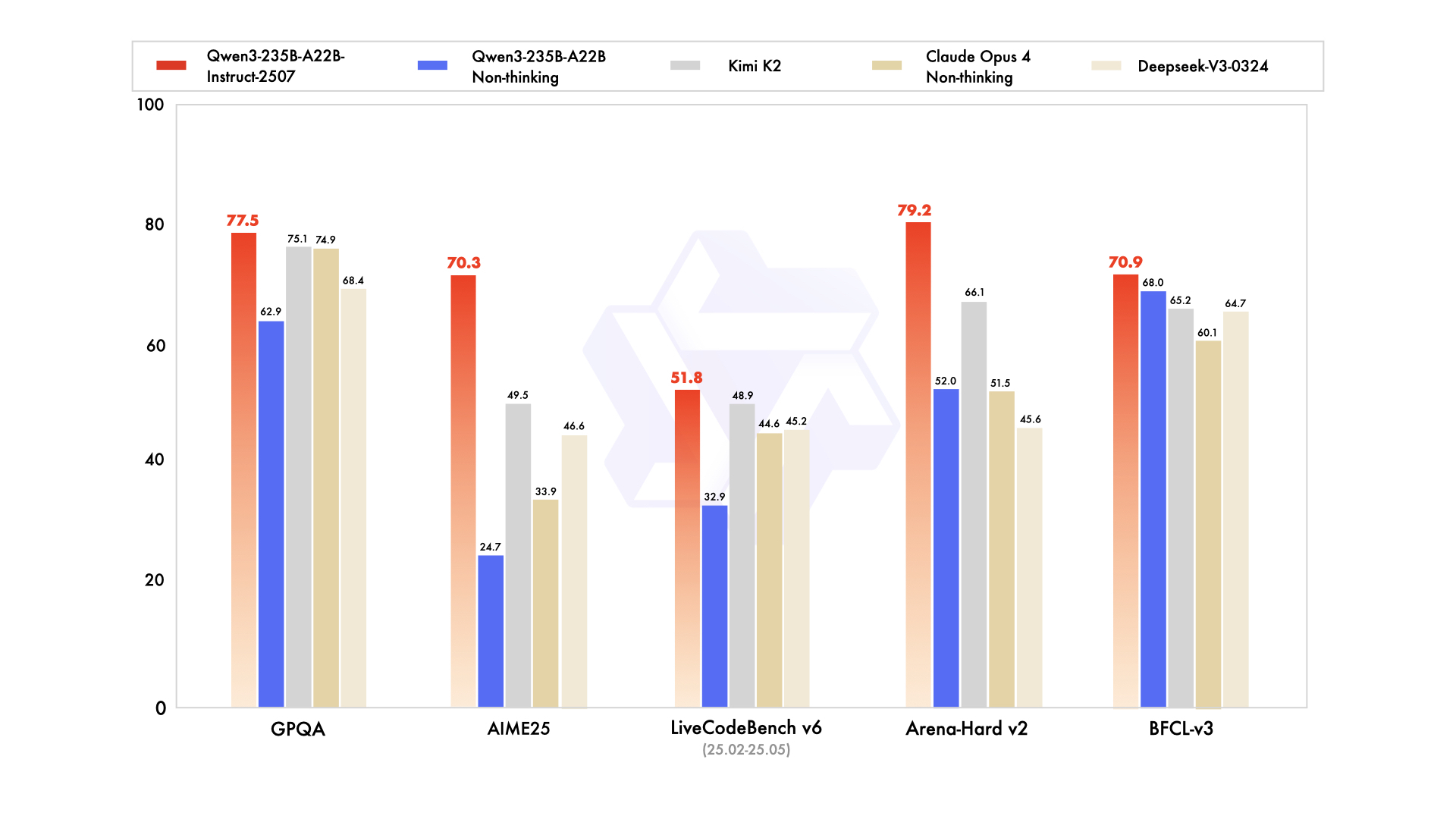
Výkon a srovnání: Čísla mluví sama za sebe
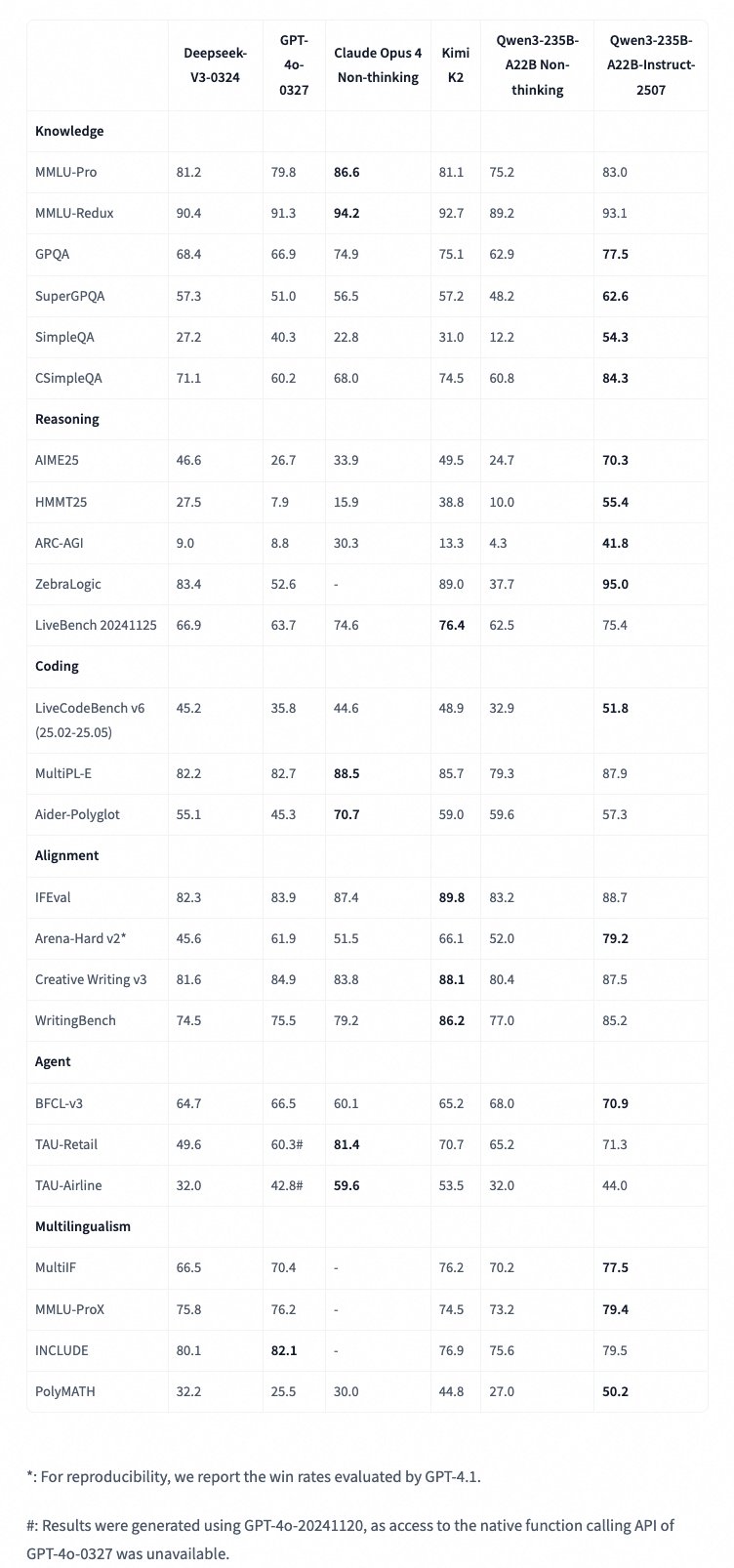
Pokud jde o výkon, Qwen3-235B-A22B-Instruct-2507 překonává mnoho konkurentů v klíčových benchmarkách. Například v testu MMLU-Pro dosáhl skóre 83,0, což je lepší než u Deepseek-V3-0324 (81,2) nebo GPT-4o-0327 (79,8). V GPQA (Google Proof Questions and Answers) má 77,5 bodů, což ho staví na vrchol před Claude Opus 4 Non-thinking (74,9). V matematických testech jako AIME25 dosáhl úctyhodných 70,3 bodů, zatímco HMMT25 mu dalo 55,4 – obojí je špička ve srovnání s jinými modely.
V programování exceluje s 51,8 body v LiveCodeBench v6 (pro období únor až květen 2025), což překonává Kimi K2 (48,9). Pro agentní úkoly (agent) má v BFCL-v3 70,9 bodů, v TAU-Retail 71,3 a v TAU-Airline 44,0. Multijazykové schopnosti jsou také na vysoké úrovni: V MMLU-ProX dosáhl 79,4, v PolyMATH 50,2, což ukazuje na podporu více než 100 jazyků a dialektů.
Verze FP8 si drží stejný výkon, ale s nižšími nároky – například pro spuštění stačí méně výpočetní síly, což je ideální pro menší servery. Podle benchmarků z Qwen blogu a GitHubu model výrazně zlepšil porozumění dlouhým kontextům až 256K tokenů, což ho činí vhodným pro složité scénáře jako analýza dlouhých dokumentů nebo vícejazyčné konverzace.
Použití a nasazení: Jak to spustit v praxi?
Chcete-li model vyzkoušet, je to snadné díky integraci s nástroji jako Hugging Face Transformers (verze 4.51.0 a vyšší). Příklad kódu v Pythonu ukazuje, jak načíst model a tokenizer, připravit vstup a generovat odpověď – například pro prompt "Dej mi krátký úvod do velkých jazykových modelů" model vygeneruje text až do 16 384 nových tokenů. Pro nasazení doporučují SGLang (verze 0.4.6.post1) nebo vLLM (0.8.5), kde můžete spustit server s tensorovou paralelizací na 8 GPU pro plnou kontextovou délku 262 144 tokenů. Pokud máte problémy s pamětí, snižte ji na 32 768.
Pro agentní použití (agentic use) je ideální Qwen-Agent, který zjednodušuje volání nástrojů – například integrace s MCP konfiguracemi pro čas nebo fetch operace. Model podporují i lokální aplikace jako Ollama, LM Studio nebo llama.cpp. Doporučené parametry pro generování: teplota 0,7, TopP 0,8, TopK 20 a MinP 0. Pro matematiku přidejte do promptu "Prosím uvažuj krok za krokem a konečnou odpověď vlož do \boxed{}".
Co říká komunita?
Z internetových zdrojů, jako je GitHub QwenLM/Qwen3 a blog Qwen, vyplývá, že model je veřejně dostupný s váhami ke stažení, včetně GGUF formátů pro snadnou integraci. Komunita na OpenRouter a LM Studio ho chválí za rychlost a přesnost v reálných aplikacích, jako je generování kódu nebo multijazykové úkoly. Existují i kvantizované varianty, jako 4bit verze pro MLX, což usnadňuje použití na slabším hardwaru. Podle arXiv zprávy (2505.09388) od Qwen Teamu model přináší významné zlepšení v zarovnání s uživatelskými preferencemi, což vede k užitečnějším odpovědím bez zbytečných opakování – stačí nastavit presence_penalty mezi 0 a 2.
Tento model není jen technický kousek, ale opravdový pomocník pro vývojáře, vědce i běžné uživatele. Pokud hledáte AI, které zvládne složité úkoly s lehkostí, Qwen3-235B-A22B-Instruct-2507 je tou správnou volbou. Stačí ho vyzkoušet a uvidíte sami!





