
Alibaba v září spustila model Qwen3-VL a teď zveřejnila podrobný technický report o tomto otevřeném multimodálním modelu. Tento systém vyniká v úkolech, kde řeší matematické problémy na základě obrázků, a dokáže prozkoumat hodiny videa. Zpracovává obrovské množství dat, například dvouhodinové video nebo stovky stránek dokumentů v kontextovém okně o velikosti 256 000 tokenů.
V testech typu "jehla v kupce sena" dosáhl největší model s 235 miliardami parametrů stoprocentní přesnosti při hledání jednotlivých snímků v třicetiminutových videích. I v dvouhodinových videích, které obsahují zhruba milion tokenů, zůstala přesnost na 99,5 %. Test funguje tak, že se do dlouhého videa náhodně vloží důležitý snímek s významem, a systém ho musí najít a prozkoumat.
Výsledky benchmarků
V publikovaných srovnáních často překonává Qwen3-VL-235B-A22B modely jako Gemini 2.5 Pro, OpenAI GPT-5 nebo Claude Opus 4.1, a to i když konkurenti používají pokročilé funkce na uvažování nebo vysoké rozpočty na myšlení. Vizuální matematické úkoly zvládá na výbornou: v testu MathVista dosáhl 85,8 %, což je víc než 81,3 % u GPT-5. V MathVision vedl s 74,6 %, před Gemini 2.5 Pro s 73,3 % a GPT-5 s 65,8 %.
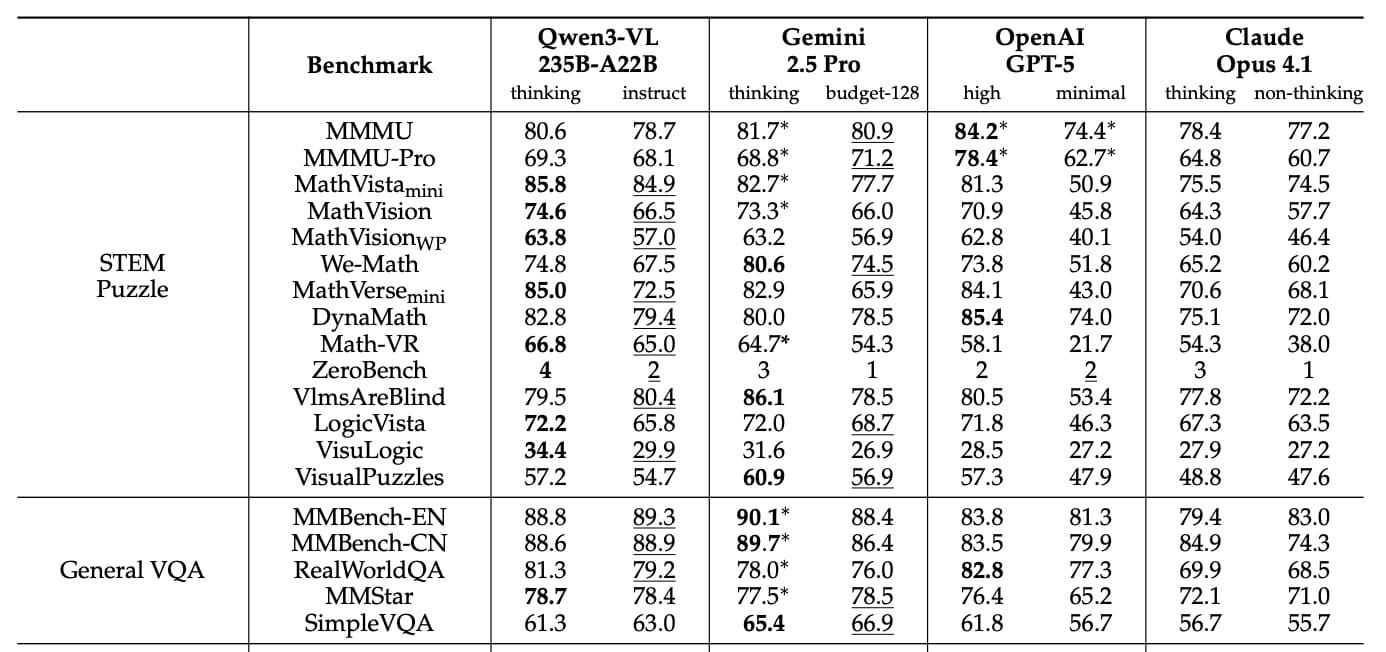
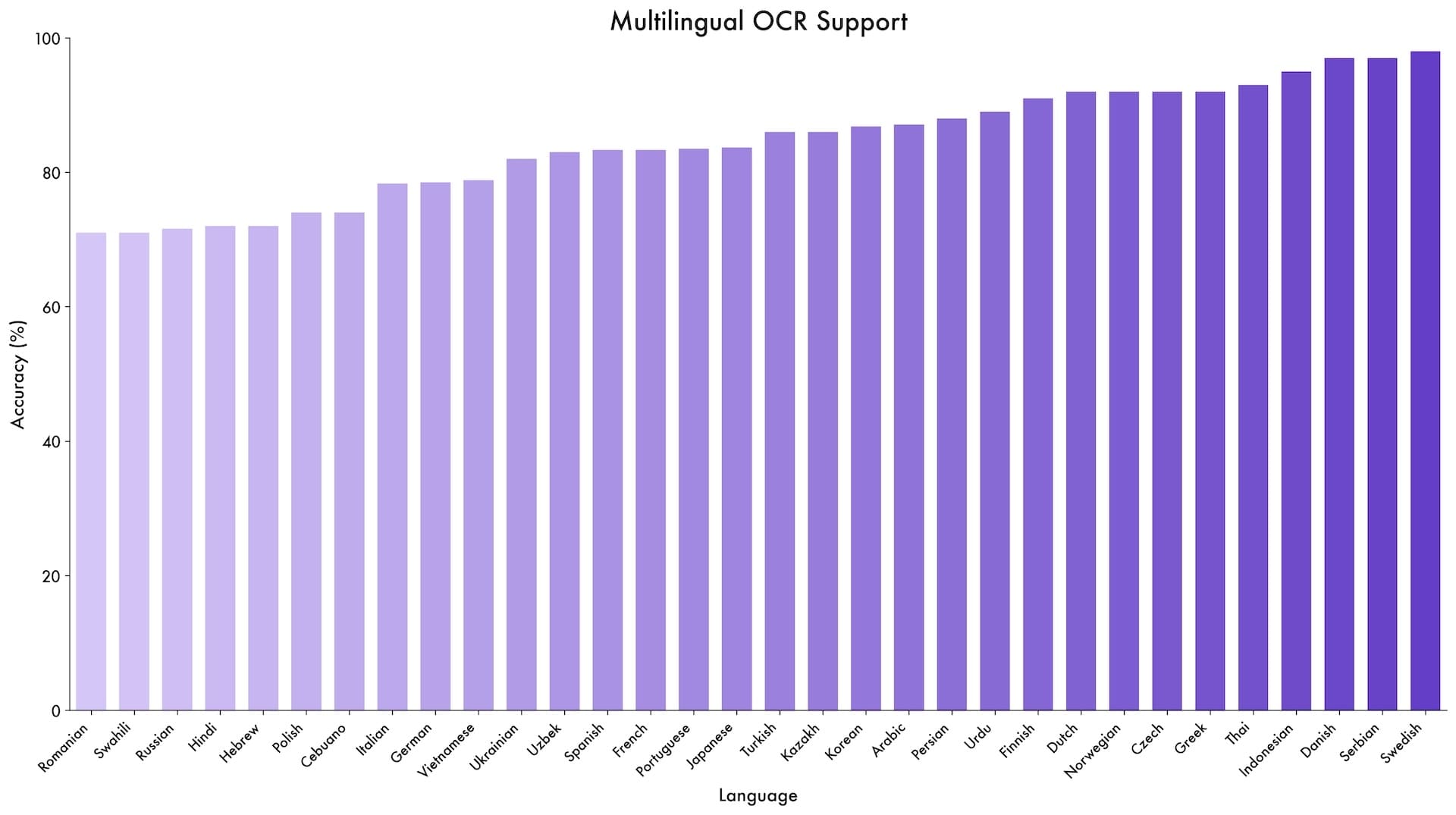
Model se osvědčil i ve specializovaných testech. V DocVQA na porozumění dokumentům dosáhl 96,5 %, a v OCRBench na rozpoznávání textu získal 875 bodů. Podporuje 39 jazyků, což je skoro čtyřikrát víc než předchozí verze. V optickém rozpoznávání znaků (OCR) dosáhl přes 70 % přesnosti v 32 z těchto 39 jazyků.
Schopnosti v praxi
Alibaba tvrdí, že systém přináší novinky v úkolech s grafickými uživatelskými rozhraními (GUI). V testu ScreenSpot Pro na navigaci v grafických rozhraních dosáhl 61,8 % přesnosti. V AndroidWorld, kde musí samostatně ovládat aplikace pro Android, dosáhl Qwen3-VL-32B 63,7 %.
Zpracovává i složité vícestránkové PDF dokumenty. V MMLongBench-Doc na analýzu dlouhých dokumentů dosáhl 56,2 %. V benchmarku CharXiv na vědecké grafy získal 90,5 % v popisných úkolech a 66,2 % v otázkách vyžadujících složité uvažování.
Ne ve všem je ale na vrcholu. V komplexním testu MMMU-Pro dosáhl 69,3 %, což je méně než 78,4 % u GPT-5. Kompetitivní modely obvykle vedou ve videových otázkách a odpovědích. Qwen3-VL se tak jeví jako specialista na vizuální matematiku a dokumenty, ale v obecném uvažování zaostává.
Technické vylepšení pro lepší výkon
Technický report popisuje tři hlavní změny v architektuře. První je "interleaved MRoPE", která nahrazuje předchozí metodu pozicování. Místo seskupování matematických reprezentací podle dimenzí (čas, horizontální, vertikální) je teď rovnoměrně rozděluje do všech dostupných matematických oblastí. To pomáhá při dlouhých videích.
Druhá novinka je technologie DeepStack, která umožňuje modelu přístup k mezivýsledkům z vizuálního kodéru, nejen k finálnímu výstupu. Díky tomu má systém vizuální informace na různých úrovních detailů.
Třetí změna je textový systém časových značek, který nahrazuje složitý T-RoPE z Qwen2.5-VL. Místo přiřazování matematické časové pozice každému snímku videa teď systém vkládá jednoduché textové značky jako "<3.8 seconds>" přímo do vstupu. To zjednodušuje proces a zlepšuje chápání časových úkolů ve videích.
Trénink na obřím měřítku
Alibaba trénovala model ve čtyřech fázích na až 10 000 grafických procesorech (GPU). Nejdřív se naučil spojovat obrázky a text, pak prošel plným multimodálním tréninkem na zhruba jednom bilionu tokenů. Zdroje dat zahrnovaly webové scrapy, 3 miliony PDF z Common Crawl a přes 60 milionů úkolů ze STEM oblastí.
V pozdějších fázích tým postupně rozšiřoval kontextové okno z 8 000 na 32 000 a nakonec na 262 000 tokenů. Varianty "Thinking" dostaly speciální trénink na řetězce myšlenek, což jim umožňuje explicitně mapovat kroky uvažování pro lepší výsledky ve složitých problémech.
Otevřenost a dostupnost
Všechny modely Qwen3-VL vydané od září jsou dostupné pod licencí Apache 2.0 s otevřenými vahami na Hugging Face. Nabídka zahrnuje husté varianty od 2 miliard do 32 miliard parametrů, plus směs expertů: 30B-A3B a obří 235B-A22B.
Funkce jako extrakce snímků z dlouhých videí nejsou nové – Google Gemini 1.5 Pro to zvládal už na začátku roku 2024 – ale Qwen3-VL nabízí srovnatelný výkon v otevřeném balení. Předchozí Qwen2.5-VL je běžný ve výzkumu, takže nový model pravděpodobně posune otevřený vývoj dál.
Další zdroj: the-decoder.com





