Allen Institute for AI, zkráceně Ai2, právě představil Olmo 3, což je rodina modelů umělé inteligence, která se liší od většiny ostatních. Zatímco mnoho firem chrání své trénovací procesy jako šéf kuchař recept na nejlepší pokrm, Ai2 všechno sdílí. Olmo 3 není jen další "otevřený" model, který nabízí jen váhy – čísla, která rozhodují o odpovědích. Tady dostanete všechno: váhy, každý uložený snímek z tréninku, rozhodnutí o datech a každý řádek kódu, který proměnil surová data v myslící stroj. Je to jako kdyby Tesla sdílela nejen design aut, ale celou továrnu.
Tento model je první plně otevřený myslící model s 32 miliardami parametrů. Parametry jsou nastavitelné hodnoty; čím víc jich je, tím chytřejší odpovědi. Myslící znamená, že model ukazuje myšlenkový proces po krocích. Můžete sledovat každou odpověď až k přesným trénovacím datům, upravit ji, přestavět nebo vylepšit. Rodina modelů sahá od 7 miliard do 32 miliard parametrů a běží na všem od notebooků po datová centra.
Modely Olmo 3 a jejich silné stránky
Olmo 3-Think s 32 miliardami parametrů je hraniční myslící model, který ukazuje myšlení po krocích a je plně otevřený pro výzkum a posilování učení. Je ideální pro složité úlohy, kde potřebuješ vidět, jak model dospěl k závěru. Olmo 3-Base, dostupný v 7 miliardách a 32 miliardách parametrů, vyniká v programování, čtení s porozuměním a matematice. Má kontext 65 tisíc tokenů což odpovídá asi 50 tisícům slov. To znamená, že zvládne analyzovat dlouhé texty, jako celé knihy nebo složité dokumenty.
Olmo 3-Instruct se 7 miliardami parametrů je optimalizovaný pro konverzace a používání nástrojů. Je rychlý v odpovědích, zvládá vícenásobné otázky a funguje dobře v chatových aplikacích. Efektivita je ohromující: Olmo 3-Think soupeří s podobně velkými modely od Qwen, ale trénoval se na 6krát méně tokenech. To znamená nižší náklady, méně energie a rychlejší iterace, aniž by to ovlivnilo výkon.
Náklady na trénink byly pro 7 miliardový model asi 500 tisíc dolarů, což je přibližně 10 485 000 Kč, a pro 32 miliardový model kolem 2,2 milionu dolarů, tedy asi 46 134 000 Kč. To je zlomek toho, co utrácí uzavřené modely, a všechno je zdarma k dispozici.
Význam modelu Olmo 3
Dlouho znamenal "otevřený zdroj" v AI jen uvolnění vah, ale trénovací tajemství zůstávala zamknutá. S Olmo 3 mohou výzkumníci reprodukovat výsledky, firmy upravovat modely bez závislosti na dodavatelích a vývojáři chápat chování modelu. Velké technologické firmy chtějí, aby byli ostatní závislí na jejich neprůhledných modelech, ale Ai2 dává přístup k celému modelu.
Modely jsou dostupné na Hugging Face a v Ai2 Playground pod licencí Apache 2.0, která umožňuje používání, úpravy a komerční využití zdarma. Kód je na GitHubu a plné technické detaily jsou k dispozici. Plně rozumí česky.
Olmo 3 je postavený na Dolma 3, což je nový korpus s asi 9,3 biliony tokenů z webových stránek, vědeckých PDF, kódů, matematických problémů a encyklopedického textu. Pro střední fázi tréninku použili Dolma 3 Dolmino, směs 100 miliard tokenů zaměřenou na matematiku, vědu, kód a čtení s porozuměním. Pro dlouhý kontext přidali Dolma 3 Longmino s 50 miliardami tokenů z dlouhých dokumentů.
Výkon a srovnání s konkurencí
Olmo 3-Base 32B překonává jiné plně otevřené základní modely jako Marin 32B nebo Apertus 70B v matematice, programování a čtení. Například na GSM8k dosáhl 80,5 %, na MATH 43,4 % a na BigCodeBench 43,9 %. Soupeří i s modely jako Qwen 2.5 32B nebo Gemma 3 27B.
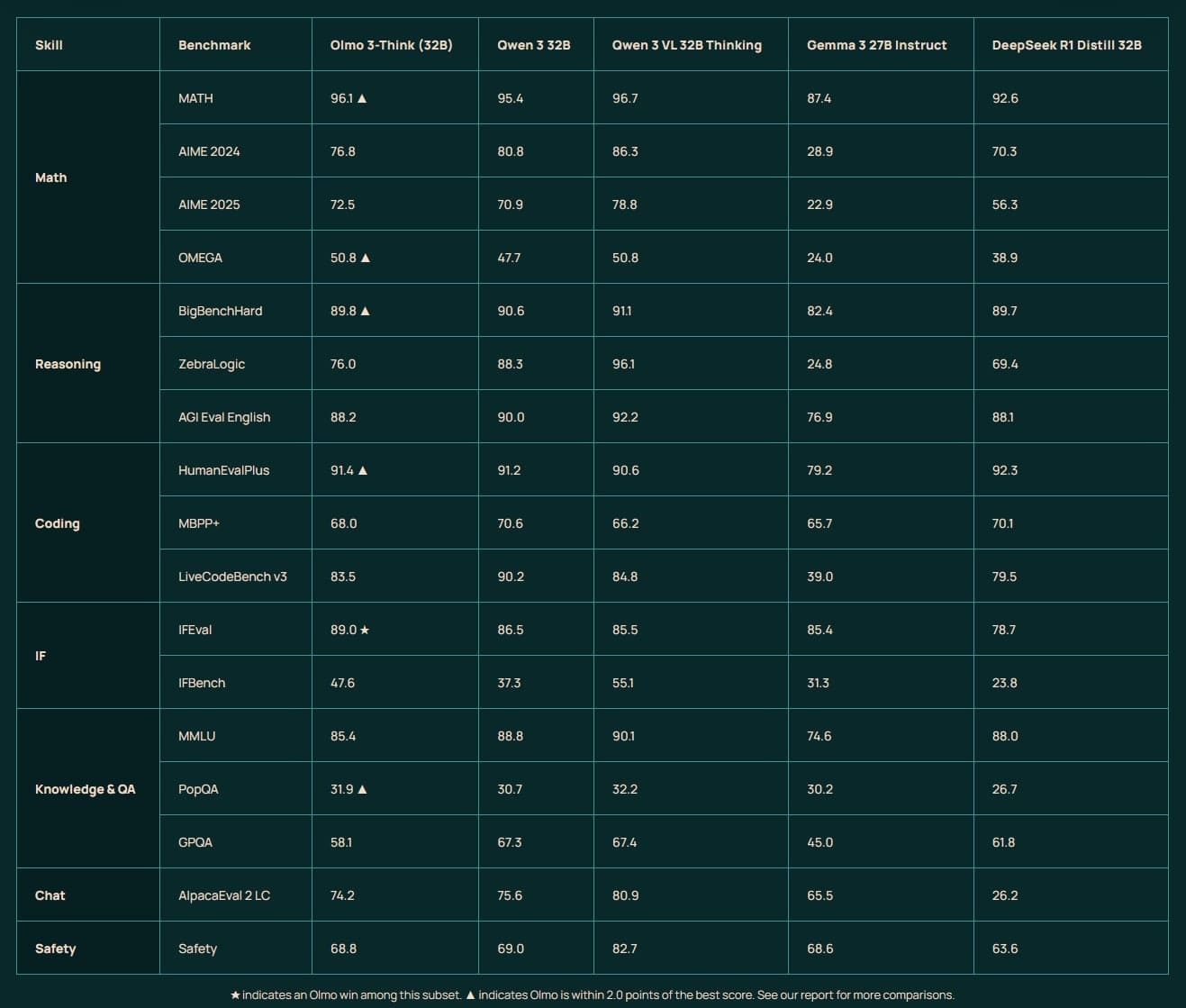
Olmo 3-Think 32B je nejsilnější plně otevřený myslící model, který se blíží Qwen 3 32B na MATH s 96,1 % nebo na BigBenchHard s 89,8 %. Na HumanEvalPlus dosáhl 91,4 %. Olmo 3-Instruct 7B překonává Qwen 3 8B v bezpečnosti s 87,3 % a je silný v nástrojovém použití, jako na SimpleQA s 79,3 %.
Trénink probíhal na clusteru až 1024 GPU H100, s průtokem 7,7 tisíc tokenů za sekundu na zařízení pro 7B model. Post-trénink zrychlili 8krát pro SFT a 4krát pro RL díky vylepšením jako kontinuální dávkování a aktualizace vah za letu.
Olmo 3 integruje OlmoTrace, nástroj pro sledování výstupů zpět k trénovacím datům v reálném čase. To umožňuje vidět, proč model odpovídá určitým způsobem a upravovat data podle potřeby.
Pro post-trénink představili Dolci, sadu dat pro myslící, nástrojové použití a instrukce. Obsahuje směsi pro SFT, DPO a RLVR. Olmo 3-RL Zero 7B je cesta pro posilování učení přímo na základním modelu, s checkpointy pro matematiku, kód, instrukce a chat.
Modely běží na jedné GPU s 80 GB pamětí pro 32B verzi, což je ideální pro výzkum. Ai2 plánuje další vylepšení, jako směsi expertů nebo lepší trénink znaků, ale Olmo 3 už teď nastavuje standard pro otevřenost.
S modelem si můžete povykládat zde: playground.allenai.org
Další zdroj: interconnects.ai





