
Po únorové řadě Qwen3.5 přichází tým z Alibaby s novinkou, která stojí za pozornost. Qwen Team zveřejnil open-source model Qwen3.6-35B-A3B. Model má celkem 35 miliard parametrů, ale aktivních používá pouhé 3 miliardy. Jak je to vůbec možné a co z toho plyne pro vývojáře?
Architektura MoE
Qwen3.6-35B-A3B je takzvaný řídký model s architekturou směsi expertů (MoE - Mixture of Experts). Celkový počet parametrů modelu sice dosahuje 35 miliard, ale při každém výpočtu se aktivuje jen část z nich, konkrétně 3 miliardy. Prakticky to znamená, rychlejší zpracování s nižšími nároky na hardware při zachování výkonu, který obvykle vyžaduje mnohem větší modely.
Model se skládá ze 40 vrstev a využívá kombinaci tzv. Gated DeltaNet a Gated Attention mechanismů. V rámci architektury MoE pracuje se 256 experty, přičemž při každém průchodu se aktivuje 8 směrovaných plus 1 sdílený expert. Kontextové okno dosahuje standardně 262 144 tokenů a lze ho rozšířit až na přibližně milion tokenů prostřednictvím techniky YaRN. To dává vývojářům prostor pro práci s opravdu rozsáhlými projekty.
Lepší agentní programování
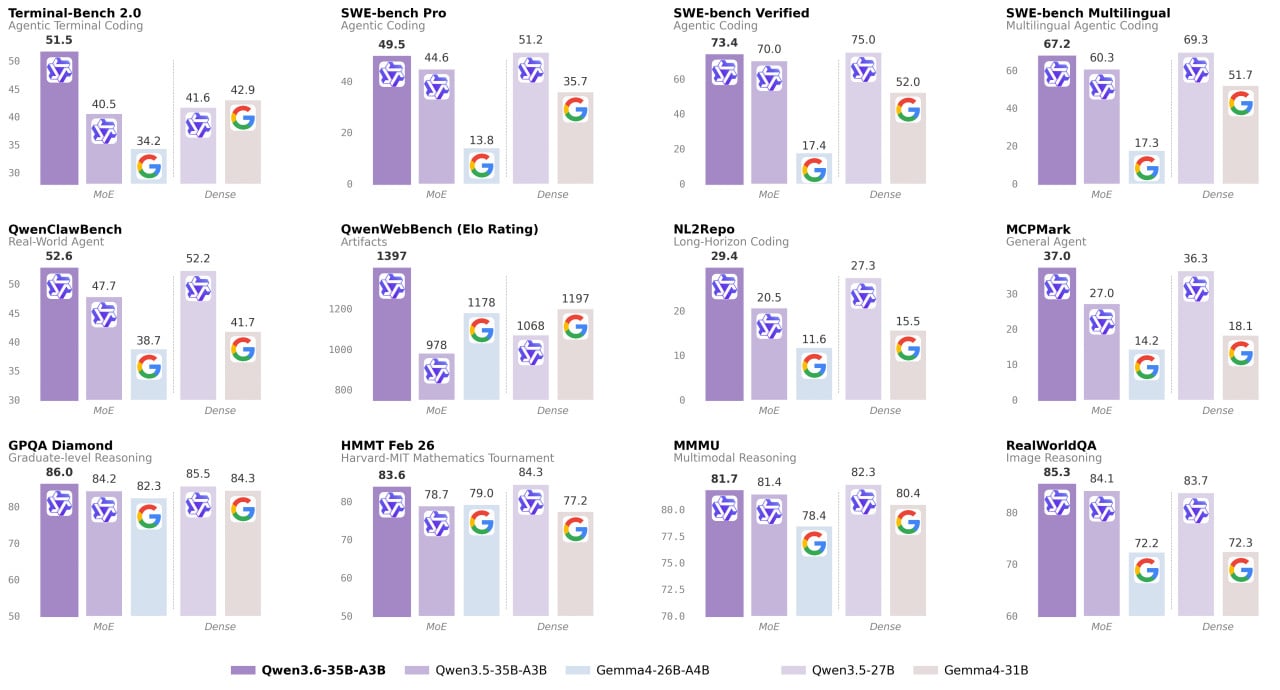
Kde konkrétně Qwen3.6-35B-A3B vyčnívá? Především v oblasti agentního programování. Na benchmarku Terminal-Bench 2.0 dosáhl skóre 51,5, čímž překonal jak Qwen3.5-27B (41,6), tak Gemma4-31B (42,9). Podobný výsledek platí i pro QwenWebBench, kde model získal skóre 1397 bodů oproti 1068 u Qwen3.5-27B a 1197 u Gemma4-31B.
Na SWE-bench Verified, jednom z nejuznávanějších testů pro agentní práci s kódem, skóre dosáhlo 73,4 bodu. To je sice mírně pod výsledkem Qwen3.5-27B (75,0), ale výrazně nad starším Qwen3.5-35B-A3B (70,0) a daleko před Gemma4-31B s pouhými 52,0 body. Přitom Qwen3.6-35B-A3B aktivuje při výpočtu jen 3 miliardy parametrů, zatímco Qwen3.5-27B jich zapojuje 27 miliard.
Na matematickém testu AIME 2026 model dosáhl 92,7 bodu a překonal i Qwen3.5-27B (92,6). V GPQA diamantové sadě, která testuje vědecké uvažování, získal 86,0 bodu, což je více než kterýkoliv z porovnávaných modelů.
Multimodální schopnosti
Qwen3.6-35B-A3B není čistě textový model. Zvládá obrazový vstup, video i dokumenty a výsledky v těchto oblastech jsou přinejmenším srovnatelné s Claude Sonnet 4.5. Na RealWorldQA dosáhl 85,3 oproti 70,3 u Claude Sonnet 4.5. V prostorovém uvažování na benchmarku RefCOCO model získal 92,0 bodu, zatímco Qwen3.5-27B zastavil na 90,9.
Obzvláště pozoruhodný je výsledek u ODInW13, testu detekce objektů v reálném světě: 50,8 bodu oproti 41,1 u Qwen3.5-27B. Na videobenchmarku VideoMMMU pak model překonal všechny soupeře skórem 83,7 bodu.
Zachování myšlenkového kontextu
Jednou z prakticky nejzajímavějších novinek Qwen3.6 je funkce preserve_thinking. Model standardně před každou odpovědí „přemýšlí" a produkuje reasoning obsah. Nová možnost umožňuje tento reasoning kontext přenášet i z předchozích zpráv v konverzaci, nejen z aktuálního dotazu.
Pro agentní scénáře to má přímý dopad: model lépe udržuje konzistenci rozhodnutí v rámci celého pracovního postupu, méně opakuje zbytečné výpočty a efektivněji využívá cache. Qwen Team tuto funkci doporučuje výslovně pro agentní nasazení. Model lze přitom přepnout i do nereflexivního režimu, kde reasoning přeskočí a odpoví přímo, pokud uživatel preferuje rychlou odpověď.
Kde a jak model spustit
Model je volně dostupný na Hugging Face i ModelScope. Váhy lze stáhnout a provozovat lokálně. Pro produkční nasazení a scénáře s vyšším provozem tým doporučuje frameworky SGLang, vLLM nebo KTransformers.
Přes Alibaba Cloud Model Studio je model dostupný pod označením qwen3.6-flash a podporuje jak OpenAI-kompatibilní protokol, tak rozhraní kompatibilní s Anthropicem. To konkrétně znamená, že ho lze zapojit přímo do Claude Code pouhou změnou proměnných prostředí bez úprav kódu.
Pro vývojáře, kteří chtějí rozjet model lokálně přes SGLang, stačí základní příkaz: python -m sglang.launch_server --model-path Qwen/Qwen3.6-35B-A3B --port 8000 --tp-size 8 --context-length 262144 --reasoning-parser qwen3
Pro vLLM je postup velmi podobný. Obě varianty podporují víceúčelové předpovídání tokenů (MTP), které dále zrychluje inferenci.
Integrace s kódovacími nástroji: OpenClaw, Claude Code a Qwen Code
Model se bezproblémově propojuje se třemi hlavními nástroji pro agentní programování. OpenClaw (dříve Moltbot/Clawdbot) je open-source agentní kodér pro terminál, který lze napojit na Model Studio. Qwen Code je vlastní terminálový agent Qwen optimalizovaný přímo pro modely ze série Qwen. A pak je tu Claude Code od Anthropicu, k jehož používání s modelem Qwen stačí přenastavit proměnné prostředí.
Komunita se modelu chopila rychle. Za necelý týden na Hugging Face přibylo 167 kvantizovaných variant modelu, 52 doladěných verzí a 8 adaptérů. Stahování už přesáhlo 200 000 stažení.
Doporučené nastavení pro optimální výkon
Qwen Team pro různé typy úloh doporučuje odlišné hodnoty vzorkovacích parametrů. Pro myšlenkový režim u obecných úloh: temperature 1,0, top_p 0,95, top_k 20. Pro přesné kódovací úlohy jako WebDev: temperature 0,6, top_p 0,95. Pro přímý režim bez uvažování: temperature 0,7, top_p 0,8.
Pro benchmarkování na obtížných matematických nebo programátorských problémech tým navrhuje nastavit maximální délku výstupu na 81 920 tokenů, aby model měl dostatek prostoru pro podrobné uvažování. U většiny dotazů postačuje 32 768 tokenů.
Model zvládá i zpracování extrémně dlouhých textů. S technikou YaRN lze kontextové okno rozšířit až na přibližně milion tokenů, konkrétně na 1 010 000. To otevírá možnosti pro analýzu rozsáhlých repozitářů nebo hodinových videí v jednom průchodu, na což by dříve nestačily ani mnohem větší modely.





