
Nová AI kombinuje podcasty a vědecké články pro přesnější odpovědi
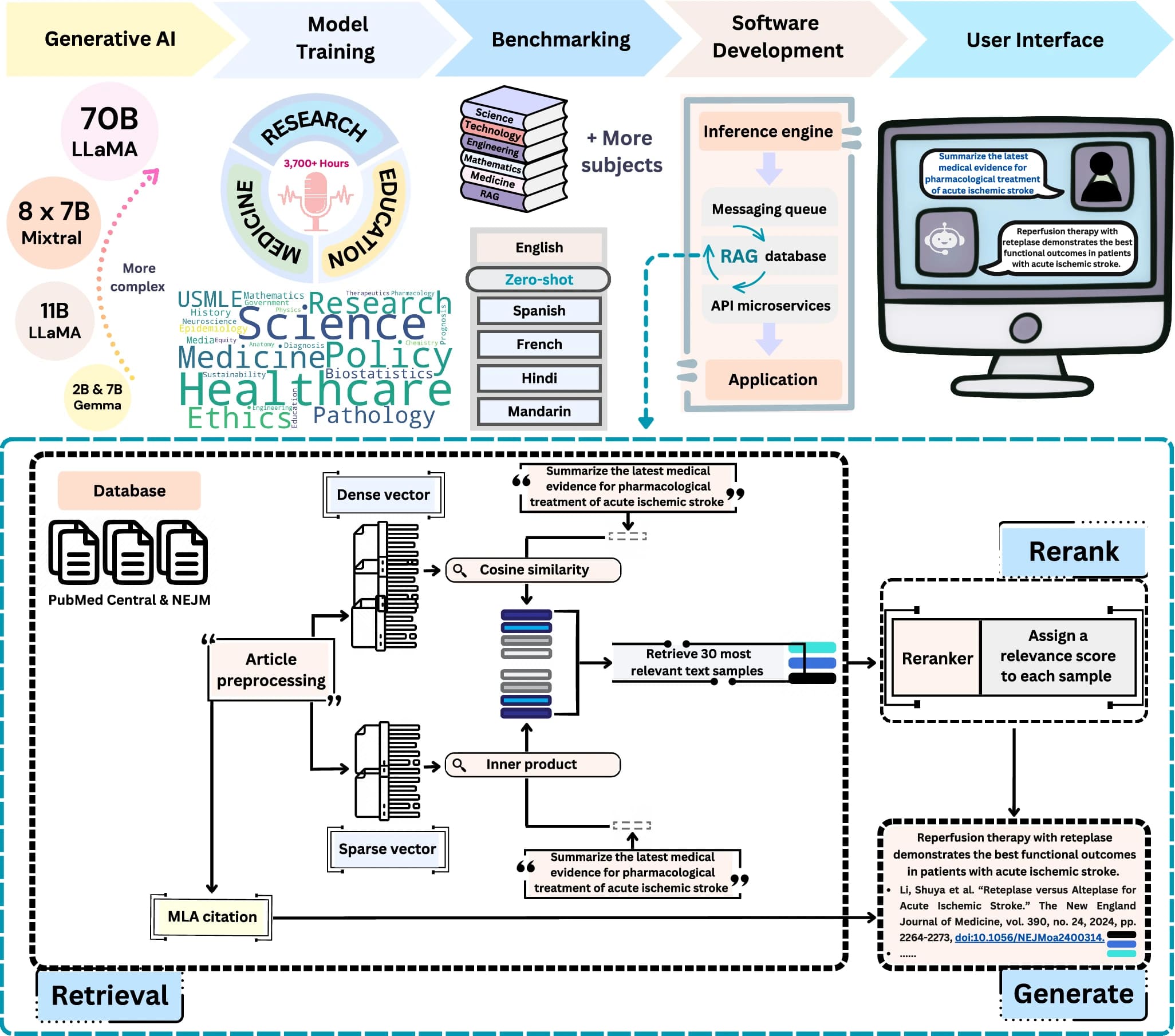
Výzkumníci z Bostonské univerzity pod vedením Vijaya B. Kolachalamy vytvořili zcela nový jazykový model nazvaný PodGPT, který mění přístup k vědeckým informacím. Tento model využívá unikátní přístup - učí se z více než 3700 hodin audio obsahu z vědeckých podcastů z oblastí vědy, technologie, inženýrství, matematiky a medicíny (STEMM).
Tým výzkumníků přepsal podcastové nahrávky na více než 42 milionů textových tokenů, což umožnilo modelu zachytit širokou škálu odborné terminologie a konverzačních kontextů, které se běžně nevyskytují v tradičních textových datasetech. Tento přístup je zásadní inovaci v trénování jazykových modelů pro vědecké aplikace.
Kombinace podcastů s vědeckou literaturou
PodGPT využívá pokročilou technologii RAG (Retrieval-Augmented Generation - generování rozšířené o vyhledávání), která mu umožňuje přístup k databázi otevřených vědeckých článků. Model může čerpat informace z prestižních zdrojů, jako jsou články z Creative Commons PubMed Central a The New England Journal of Medicine. Tato databáze obsahuje články z významných časopisů včetně JAMA Network Open (9367 článků), Cell (497 článků) a The Lancet (458 článků). Systém dokáže získávat nejnovější vědecké poznatky v reálném čase a poskytovat odpovědi podložené aktuálními výzkumy. Každá odpověď je doplněna relevantními odkazy na vědecké zdroje s hodnocením relevance na základě kosínusové podobnosti.

Výkonnost napříč jazyky a obory
Při testování na standardních datasetech jako MedQA, PubMedQA, MedMCQA a MMLU STEMM kategoriích PodGPT překonal základní modely včetně Google Gemma a Meta LLaMA. Model dosáhl průměrného zlepšení o 3,51 procentního bodu oproti standardním open-source benchmarkům a o 4,06 procentního bodu v úlohách vícejazyčného přenosu.
Zvláště impresivní jsou výsledky v jednotlivých jazycích. Na čínském benchmarku MedQA-MCMLE dosáhl model Gemma 7B zlepšení o 4,39 procentního bodu. Na francouzských benchmarcích PodGPT prokázal silný výkon s průměrným zlepšením až 5,04 procentního bodu pro model Gemma 7B. V hindštině dosáhl model zlepšení až 9,80 procentního bodu v biologii.
Technické parametry a dostupnost
Výzkumníci testovali PodGPT napříč různými velikostmi modelů od 2B do 70B parametrů. Používali modely Gemma 2B a 7B, Mixtral 8×7B MoE od Mistral AI a instrukčně vyladěnou variantu LLaMA 3.3 70B. Pro snížení výpočetních nákladů implementovali low-rank adaptation (LoRA) a 8-bitový kvantizovaný AdamW optimalizér.
Model je veřejně dostupný prostřednictvím webové platformy s uživatelsky přívětivým rozhraním vytvořeným v ReactJS a NextJS. Infrastruktura využívá Kubernetes pro orchestraci kontejnerů a vLLM knihovnu pro efektivní nasazení jazykových modelů.
Praktické využití a budoucnost
PodGPT představuje významný pokrok v demokratizaci vědeckých znalostí. Využitím podcastového obsahu, který často obsahuje diskuse s předními odborníky, model zpřístupňuje vědecké poznatky širší veřejnosti v kontextuálně bohatší formě. Nižší perplexity skóre na konverzačních datasetech prokázalo schopnost modelu generovat soudržné odpovědi napodobující interakci mezi lékařem a pacientem.
Tento přístup otevírá nové možnosti pro vzdělávání a výzkum, kdy AI může poskytnout přesné a aktuální informace podložené nejnovějšími vědeckými poznatky z oblastí medicíny, biologie, chemie, fyziky a dalších STEMM disciplín.





