
Představte si robota, který dokáže manipulovat s předměty stejně obratně jako člověk, a to díky kombinaci vidění, jazyka a akcí. GR-Dexter je právě takový systém, který spojuje hardware, model a data pro ovládání robota s dvěma dexterózními rukama. Tento přístup umožňuje dlouhodobou manipulaci na základě jazykových instrukcí, ale zaměřuje se na složité platformy s vysokým počtem stupňů volnosti, jako jsou ruce s mnoha klouby. Systém řeší problémy jako rozšířený akční prostor, časté zakrytí rukou předměty a náklady na sběr demonstrací. GR-Dexter používá kompaktní robotickou ruku s vysokým počtem stupňů volnosti, intuitivní teleoperaci pro sběr dat a tréninkovou recepturu, která kombinuje trajektorie z robota s velkými daty z vidění a jazyka plus pečlivě vybraná data z různých těl.
Hardware a ovládání
Robotická ruka ByteDexter V2 je klíčovým prvkem. Tato ruka používá mechanismus poháněný spojkami pro lepší přenos síly, odolnost a snadnou údržbu. Jako vylepšení předchozí verze V1 přidává extra stupeň volnosti pro palec, což dává celkem 21 stupňů volnosti. Ruka je menší než dřív – výška 219 milimetrů, šířka 108 milimetrů. Každý prst má čtyři stupně volnosti, palec pět, což umožňuje širokou škálu pohybů, včetně opozičních gest. Pět konečků prstů je pokryto hustými poli piezorezistivních senzorů, které měří normální síly s jemnou prostorovou přesností na špičce, podušce a boční straně prstu.
Pro bimanualní systém se data sbírají přes teleoperační rozhraní s Meta Quest VR pro sledování pozice zápěstí, dvěma Manus Metagloves pro zachycení pohybů rukou a nožními pedály pro ovládání paží. Dva ovladače Meta Quest jsou připevněny na hřbet rukavic pro spolehlivé sledování koordinovaných pohybů zápěstí a ruky. Tento setup umožňuje teleoperátorům současně řídit dvě paže Franka pro dlouhodobé úkoly. Lidské pohyby se v reálném čase převádějí na příkazy pro klouby, s kinematicky konzistentním mapováním přes celotělové ovládání. Systém zahrnuje adaptivní mechanismy pro ztrátu vizuálního sledování a prevenci nebezpečných operací. Retargeting pohybů ruky je formulován jako optimalizační problém s omezeními, který zahrnuje vektory špičky zápěstí, vektory špičky palce, vyhýbání se kolizím a regularizační termín, řešený sekvenčním kvadratickým programováním.
Model GR-Dexter
GR-Dexter navazuje na GR-3 a používá architekturu Mixture-of-Transformer pro model VLA (vidění-jazyk-akce) s 4 miliardami parametrů. Tento model generuje kousky akcí délky k na základě jazykové instrukce, pozorování a stavu robota. Každá akce zahrnuje akce kloubů paží, pózy koncového efektoru paží, akce kloubů ruky a pozice konečků prstů.
Trénink zahrnuje společné učení ze tří zdrojů dat: velkých dat z vidění a jazyka, dat z různých robotických těl a trajektorií od lidí. Pro rozdíly v datech se maskují nedostupné nebo nespolehlivé dimenze akcí, jako specifické klouby. Data z vidění a jazyka pocházejí z GR-3 a pokrývají úkoly jako popisování obrázků, odpovídání na otázky, lokalizace v obrázcích a popisování s lokalizací. Data z různých těl berou z otevřených datasetů jako Fourier ActionNet Dataset, OpenLoong Baihu Dataset a RoboMIND, které zahrnují různé dvojpažové dexterózní manipulace. Lidské trajektorie se sbírají přes VR zařízení jako Pico VR a doplňují otevřené datasety pro větší množství a rozmanitost.
Pro přenos dat z různých těl se standardizují pozorování kamer a retargetují se na ByteDexter V2 zarovnáním konečků prstů, což zachovává geometrii kontaktů bez ohledu na klouby. Trajektorie se pak převzorkují podle kategorií úkolů pro vyváženost. U lidských trajektorií se filtrují na základě viditelnosti ruky a rychlosti, pak se mapují do stejné vizuální a kinematické reprezentace jako robotická data.
Experimenty a výsledky
Experimenty testují GR-Dexter na dlouhodobé bimanualní manipulaci a obecném sbírání a umisťování. Hodnotí se na úkolech s dexterózním použitím nástrojů, dlouhodobém provádění a scénářích mimo distribuci s novými prostorovými konfiguracemi, neviděnými předměty a instrukcemi.
V základních nastaveních, kde prostorové uspořádání předmětů je v tréninkových datech, dosahuje GR-Dexter úspěšnosti 0,97, srovnatelné s modelem jen z teleoperace na 0,96. V nastaveních mimo distribuci s novými uspořádáními klesá úspěšnost modelu jen z teleoperace na 0,64, zatímco GR-Dexter dosahuje 0,89. To demonstruje lepší generalizaci díky datům z vidění a jazyka.
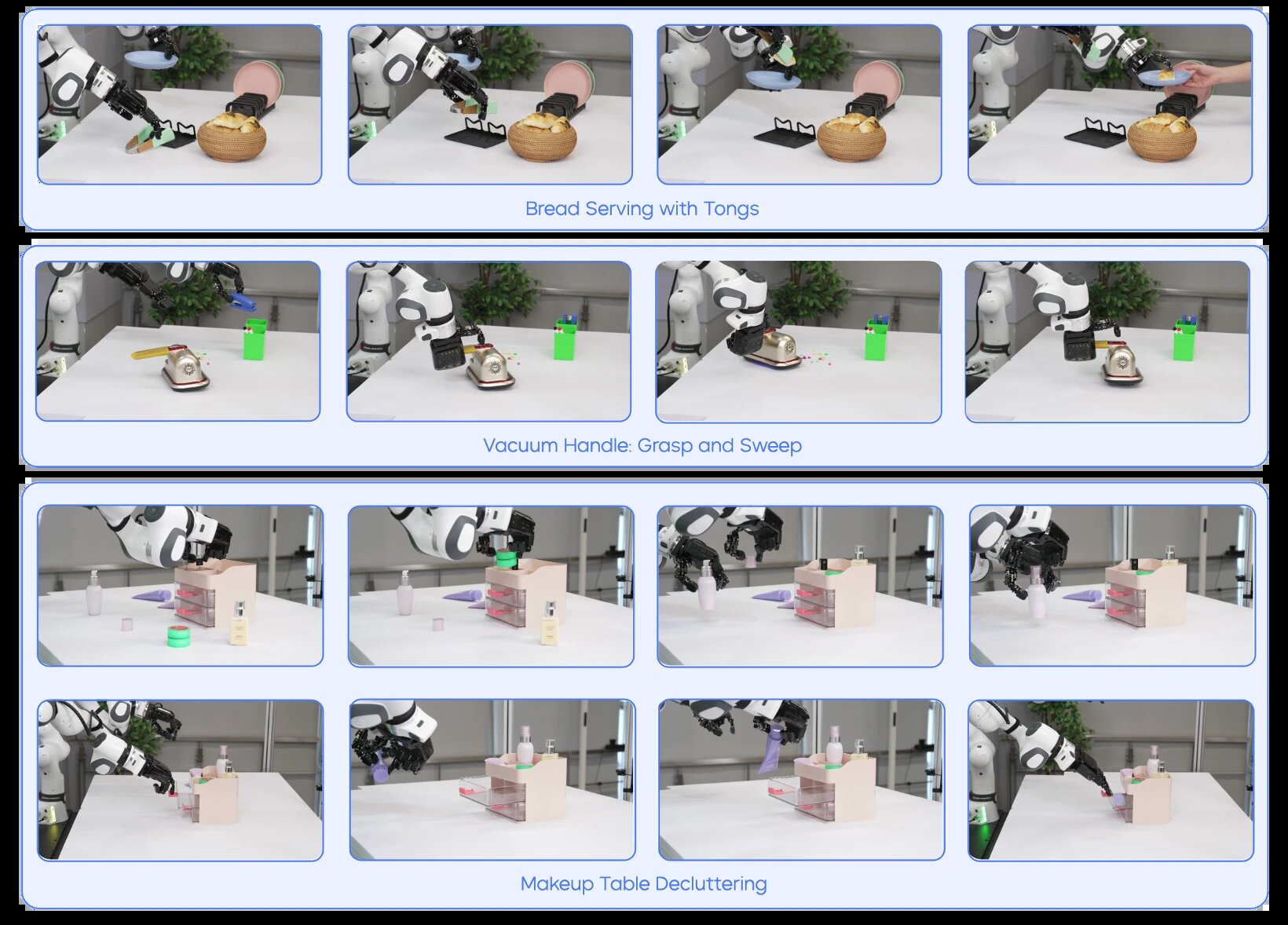
Další kvalitativní výsledky zahrnují úkoly jako vysávání, kde robot drží stolní vysavač čtyřmi prsty, stiskne tlačítko palcem pro zapnutí, pak pro zvýšení výkonu a zametá konfety. Další je servírování chleba, kde robot uchopí kleště na jídlo, vyjme croissant z nádoby, zatímco druhá ruka drží talíř, pak uvolní kleště a položí croissant na talíř.
Pro obecný sběr a umístění v základních nastaveních dosahuje GR-Dexter 0,93, lepší než model jen z teleoperace na 0,87. Bez dat z různých těl je to 0,85. V nastaveních s neviděnými předměty a instrukcemi klesá úspěšnost modelu jen z teleoperace výrazně, zatímco GR-Dexter dosahuje 0,85 pro předměty a 0,83 pro instrukce, díky lepší robustnosti z dat z různých těl.
GR-Dexter tak představuje praktický pokrok směrem k obecným dexterózním robotickým manipulacím.





