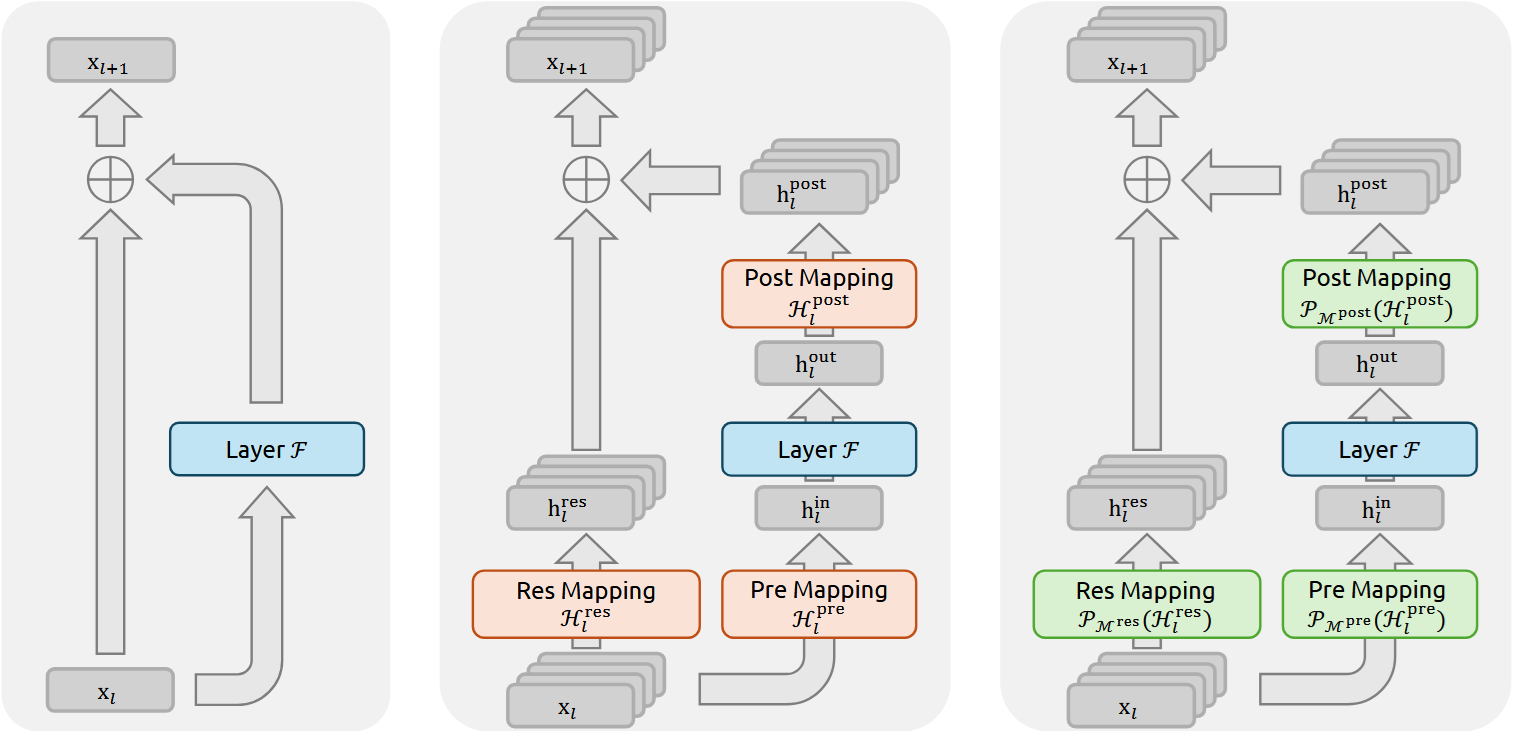
V posledních letech se vývoj umělé inteligence (AI) soustředí na obří modely, jako jsou ty, které pohání systémy podobné ChatGPT. Ale trénink těchto modelů naráží na závažné překážky, jako je nestabilita signálů během učení. DeepSeek představil metodu nazvanou mHC (manifold-constrained hyper-connections, tedy hyper-spojení omezená manifoldem), která řeší dlouhodobý problém s "explodujícími" signály v neuronových sítích. Tento přístup vychází z myšlenky ResNetů, které od roku 2016 umožňují stavět hlubší sítě díky zkratkovým spojům, jež udržují informace v proudu bez ztrát.
Saqib Qamar, autor článku na Medium popisuje, jak tradiční transformery fungují jako jednoproudová dálnice, kde informace tečou lineárně. Výzkumníci se pokusili rozšířit to na více "pruhů" pomocí hyper-spojení (HC), což by umožnilo zpracovávat více dat současně bez extra výpočetní zátěže. Bohužel, tyto paralelní pruhy vedly k chaosu: signály se buď zesílily až 3000krát, nebo úplně zanikly. To způsobovalo, že trénink selhával kolem 12 000 kroků, což znamenalo ztrátu týdnů práce a milionů v nákladech na výpočty.
DeepSeek tento problém vyřešil aplikací matematických omezení založených na manifoldech. Místo volného míchání informací mezi pruhy nutí mHC signály chovat se jako vyvážené průměry. Podle testů, které provedli na modelech od 3 miliard do 27 miliard parametrů (to jsou nastavitelné hodnoty, které model učí), se zesílení signálu stabilizovalo na přibližně 1,6krát místo extrémních výkyvů. Výsledky? Zlepšení výkonu o 7,2 % v složitém uvažování a o 6,9 % v čtení s porozuměním přes osm benchmarků. Navíc, díky optimalizacím pro GPU, přidalo to jen 6,7 % extra času na trénink, přestože se zpracovávají čtyři paralelní proudy místo jednoho.
Grassmannovy toky: Alternativa k attention mechanismu
Další článek na The Neuron spojuje objev DeepSeeku s papírem od Zhang Chong nazvaným "Attention Is Not What You Need" (Pozornost není to, co potřebujete). Tento výzkum navrhuje nahradit attention mechanismus, který je od roku 2017 základem všech velkých AI modelů, něčím úplně jiným – Grassmannovými toky. Attention pomáhá modelům chápat vztahy mezi slovy v textu, například propojit "kočka" s "se unavila" ve větě "Kočka si sedla na rohožku, protože se unavila". Ale jak vysvětluje Harvey, attention má své limity, zejména při zpracování dlouhých textů.
Problém attention spočívá v jeho kvadratické složitosti: Pokud máte 1000 tokenů (token je zhruba slovo nebo část slova), model musí vypočítat vztahy mezi každou dvojicí, což dává milion spojení. Zdvojnásobíte délku na 2000 tokenů? Výpočty se zčtyřnásobí. To dělá zpracování milionů tokenů (asi 750 000 slov, což je ekvivalent 10 románů) extrémně nákladné. Zhang Chong navrhuje Grassmannovy toky, které reprezentují vztahy mezi tokeny geometricky na Grassmannově manifoldu pomocí Plückerových souřadnic. Místo obří matice attention se tokeny zpracovávají lineárně – zdvojnění délky zdvojnásobí výpočty, ne zčtyřnásobí.
Testy ukázaly, že model s 13 až 18 miliony parametrů založený čistě na Grassmannových tocích dosáhl výsledků jen o 10–15 % horších než standardní transformer na úkolech jako modelování jazyka na Wikitext-2 a porozumění textu na SNLI. Na SNLI dokonce lehce překonal transformer. The Neuron zdůrazňuje, že tento přístup činí modely interpretovatelnější, protože vztahy jsou popsány matematickými pravidly, ne náhodnými váhami učenými gradientním sestupem.
Jak se tyto inovace doplňují
Oba přístupy řeší matematický chaos v transformerech, ale jinak. DeepSeekův mHC přidává "zábrany" k existující architektuře, aby zabránil explozím signálů, a používá techniky jako Sinkhorn-Knoppův algoritmus pro efektivitu. Podle Rohan Paul, citovaného v článku od Harvey, to umožňuje stabilní trénink bez ztráty výkonu. Naopak Grassmannovy toky jdou dál a tvrdí, že attention je zbytečně složitý – nahrazují ho geometrií, což snižuje složitost z kvadratické na lineární.
Harvey poznamenává, že tyto metody nejsou v konfliktu. Mohly by se kombinovat: Grassmannovy toky pro lokální vztahy a mHC pro hlubší vrstvy. DeepSeek, založený Liang Wenfengem, často publikuje takové výzkumy před velkými releasy, jako byl loňský model R1. Očekává se, že brzy přijde nový vlajkový model, zatímco Grassmannovy toky budou testovány na větších škálách.
Tyto objevy dělají AI spolehlivější a efektivnější, což je klíčové v době, kdy trénink stojí desítky milionů a trvá měsíce.





