
Apple ukázal jak trénuje své jazykové modely
Představte si, že Apple právě zveřejnil podrobnou technickou zprávu o svých nových základech jazykových modelů pro Apple Intelligence. Tento dokument, nazvaný „Apple Intelligence Foundation Language Models – Tech Report 2025“, popisuje, jak společnost trénovala a optimalizovala své modely pro zařízení i servery. Zahrnuje architekturu, zdroje dat, předtrénink, dodatečné trénování, optimalizace a hodnocení. A abychom to okořenili, přidáme čtyři zajímavé body z analýzy na 9to5Mac, které ukazují, jak Apple posunul hranice efektivity a výkonu. Všechno je postavené na skutečných datech z dokumentu.
Model rozdělený do dvou bloků pro lepší efektivitu
Appleův model pro zařízení, který má přibližně 3 miliardy parametrů, byl chytře rozdělen do dvou bloků. První blok obsahuje 62,5 % všech transformer vrstev, zatímco druhý blok má zbylých 37,5 %, ale bez projekcí klíčů a hodnot. Tento trik snižuje spotřebu paměti pro KV cache (mezipaměť klíčů a hodnot) o 37,5 % a zkracuje čas do prvního tokenu také o přibližně 37,5 %. Apple tvrdí, že to zachovává kvalitu modelu, což potvrzují benchmarky jako MMLU (67,85 bodů), MMMLU (60,60 bodů) a MGSM (74,91 bodů). Srovnání s modely jako Qwen-2.5-3B nebo Gemma-3-4B ukazuje, že Appleův model je konkurenceschopný, i když zaostává za většími jako Qwen-3-4B. Tento přístup připomíná starší studii Applu z roku 2023, kde experimentovali s přesouváním částí modelu mezi RAM a flash pamětí, ale nakonec zvolili tuto efektivnější strukturu.
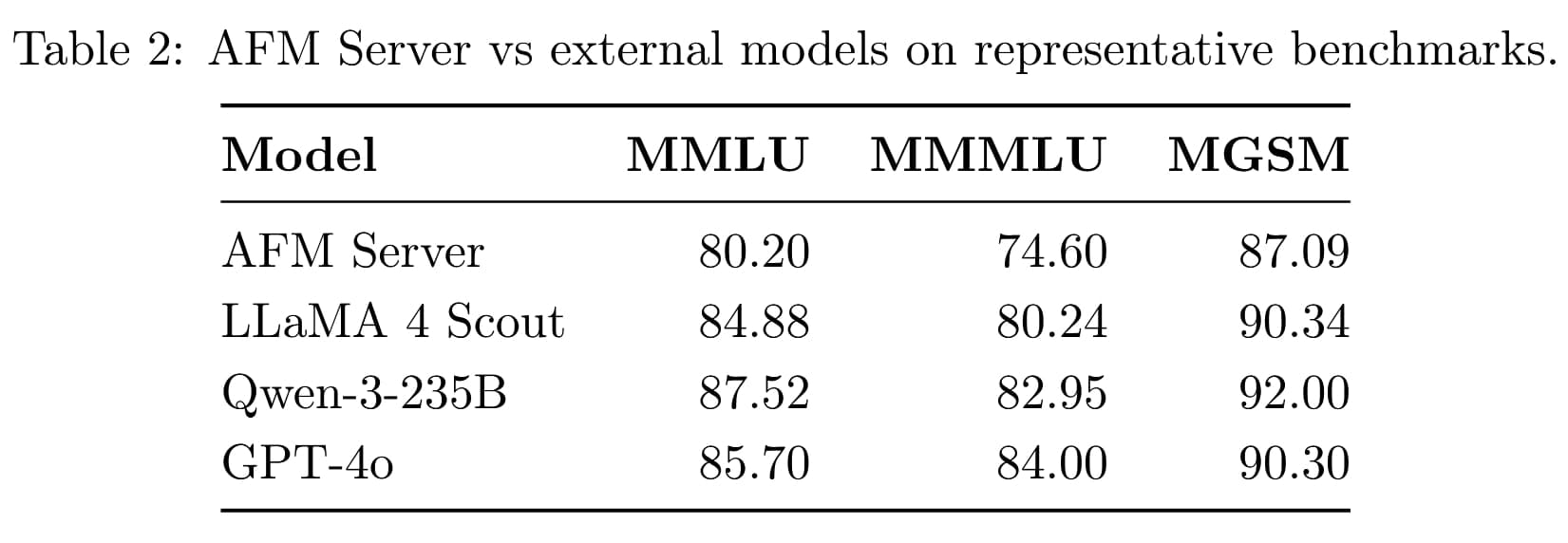
Architektura serverového modelu pro Private Cloud Compute
Pro serverový model Apple vymyslel novou architekturu nazvanou Parallel-Track Mixture-of-Experts (PT-MoE), přizpůsobenou pro platformu Private Cloud Compute. Místo jedné sekvenční stohu vrstev rozděluje model do více paralelních tratí, kde každá trať zpracovává tokeny samostatně a synchronizuje se jen na hranicích bloků. Každá trať obsahuje MoE vrstvy (směs expertů), kde se aktivují jen relevantní experti pro daný úkol – například pro vaření jen ti specializovaní na recepty. To snižuje synchronizační overhead o 87,5 % při hloubce bloku 4 a zvyšuje efektivitu. Model navíc střídá lokální a globální pozornostní vrstvy, což umožňuje zpracování dlouhých sekvencí až 65 tisíc tokenů bez ztráty kvality. V benchmarkách dosahuje 80,20 bodů v MMLU, 74,60 v MMMLU a 87,09 v MGSM, což je srovnatelné s LLaMA 4 Scout, ale zaostává za většími jako Qwen-3-235B nebo GPT-4o. Tento design dělá model rychlejší a úspornější, ideální pro cloudové úlohy.
Zvýšení multijazyčné podpory o 275 % díky chytrému tréninku
Jedním z největších vylepšení je rozšíření jazykové podpory. Apple zvýšil podíl multijazyčných dat v tréninku z 8 % na 30 %, což je nárůst o 275 %. To zahrnuje organická data, syntetická data a strojově přeložené dokumenty, s důrazem na vyváženost mezi jazyky. Tokenizér (nástroj pro rozdělování textu na tokeny) byl rozšířen z 100 tisíc na 150 tisíc tokenů, což zlepšilo reprezentaci nových jazyků. V post-tréninku, včetně SFT (supervizovaného jemného ladění) a RLHF (zesílení učení z lidské zpětné vazby), se poměr angličtiny a multijazyčných dat držel na 80:20. Hodnocení ukázalo výrazné zlepšení, například v IFEval a AlpacaEval, kde se používaly promptů napsané rodilými mluvčími pro přirozenost. Výsledkem je, že funkce jako Writing Tools fungují spolehlivěji v podporovaných jazycích, jako je portugalština, francouzština nebo japonština, s poměrem vítězství 16:9 nad SFT verzemi v lidských testech.
Od webu po syntetické obrázky, vše s důrazem na kvalitu
Apple sbíral data zodpovědně, bez použití soukromých uživatelských informací. Největší část pochází z webového crawlovaní Applebotem, který respektuje robots.txt pro opt-out webů. Data zahrnují stovky miliard stránek, filtrovaných pro kvalitu, bez vulgarit a nebezpečného obsahu. Dále tu jsou licencovaná data od vydavatelů, jako potenciálně od Condé Nast nebo Shutterstock, i když detaily nejsou specifikovány. Syntetická data hrají klíčovou roli – Apple generoval přes 5 miliard párů obrázekö-popisů pro vizuální porozumění, včetně OCR (optického rozpoznávání znaků) pro textové obrázky jako letáky nebo infografiky. Pro obrázky bylo shromážděno přes 10 miliard párů s alt-texty, plus 550 milionů obrázků v kontextu textu. To všechno pomohlo modelům zvládat úlohy jako přidávání událostí do kalendáře z fotky letáku. Celkově to vede k lepšímu výkonu v benchmarkách, jako je MMLU, kde on-device model překonává Qwen-2.5-3B.
Tento pohled do zákulisí ukazuje, jak Apple bojuje s konkurencí, i když stále dohání. S důrazem na soukromí a efektivitu, jako je Private Cloud Compute, je to krok vpřed pro uživatele, kteří chtějí chytré funkce bez kompromisů. Pokud vás zajímají detaily, technická zpráva je skvělým čtením plným grafů a tabulek.





