
Alibaba Cloud přináší Qwen3-VL, novou generaci otevřeného multimodálního modelu, který kombinuje zpracování textu a vizuálního obsahu. Tento model se zaměřuje na lepší porozumění obrázkům, videím a textu, s důrazem na delší kontexty a agentní interakce. Otevřeně dostupný je vlajkový model Qwen3-VL-235B-A22B, který přichází ve verzích Instruct a Thinking. Verze Instruct dosahuje výsledků srovnatelných nebo lepších než Gemini 2.5 Pro v klíčových benchmarkách vizuálního vnímání, zatímco verze Thinking vyniká v multimodálním uvažování.
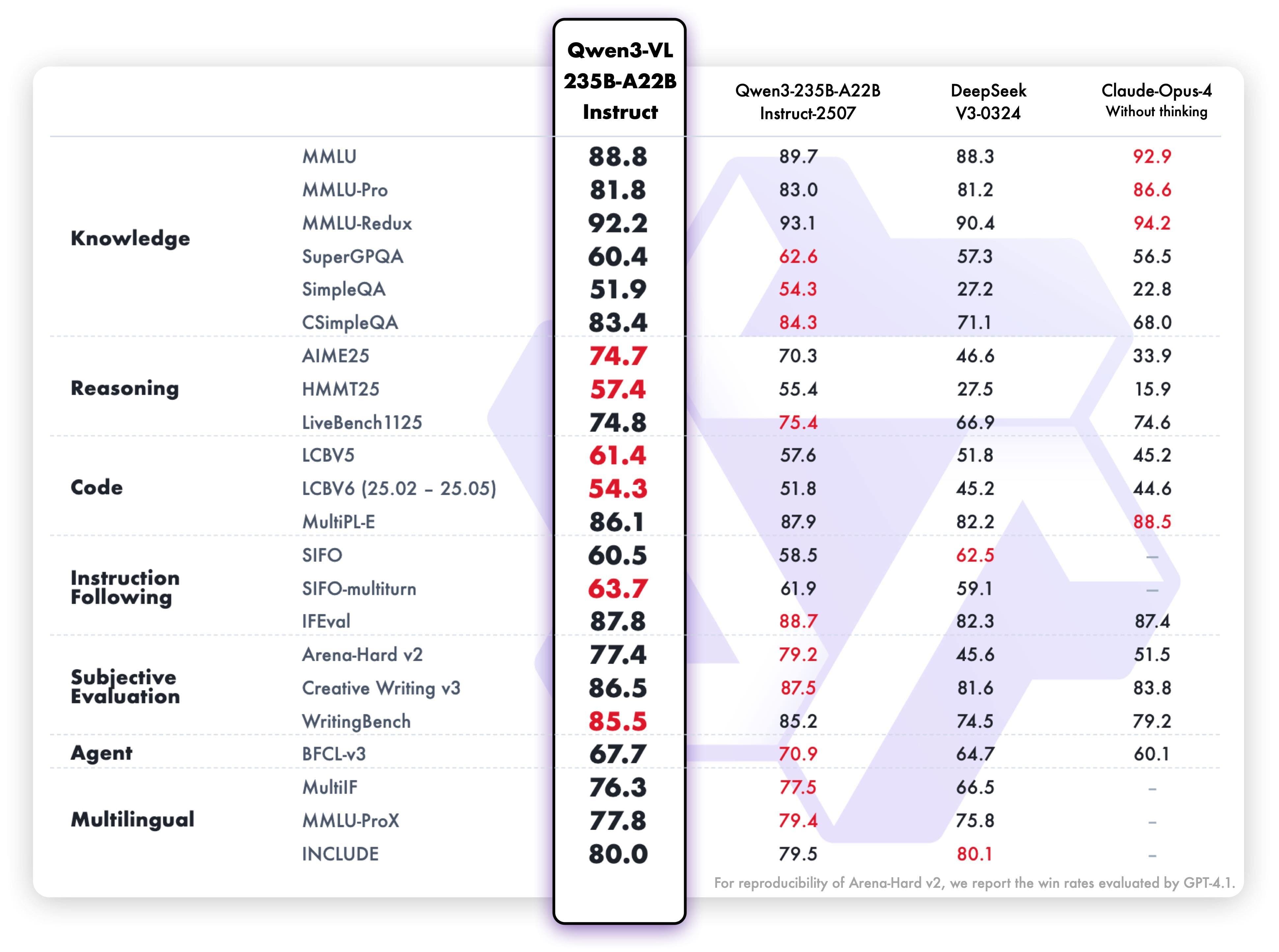
Model Qwen3-VL-235B-A22B-Instruct exceluje v deseti dimenzích, včetně univerzitních problémů, matematického uvažování, logických hádanek, obecného vizuálního dotazování, subjektivního zážitku, následování instrukcí, vícejazyčného rozpoznávání textu, parsování grafů a dokumentů, 2D a 3D lokalizace objektů, porozumění více obrázkům, prostorovému vnímání, porozumění videím, provádění agentních úkolů a generování kódu. Většinu těchto metrik překonává uzavřené modely jako Gemini 2.5 Pro a GPT-5, a stanovuje nové rekordy mezi otevřenými multimodálními modely.
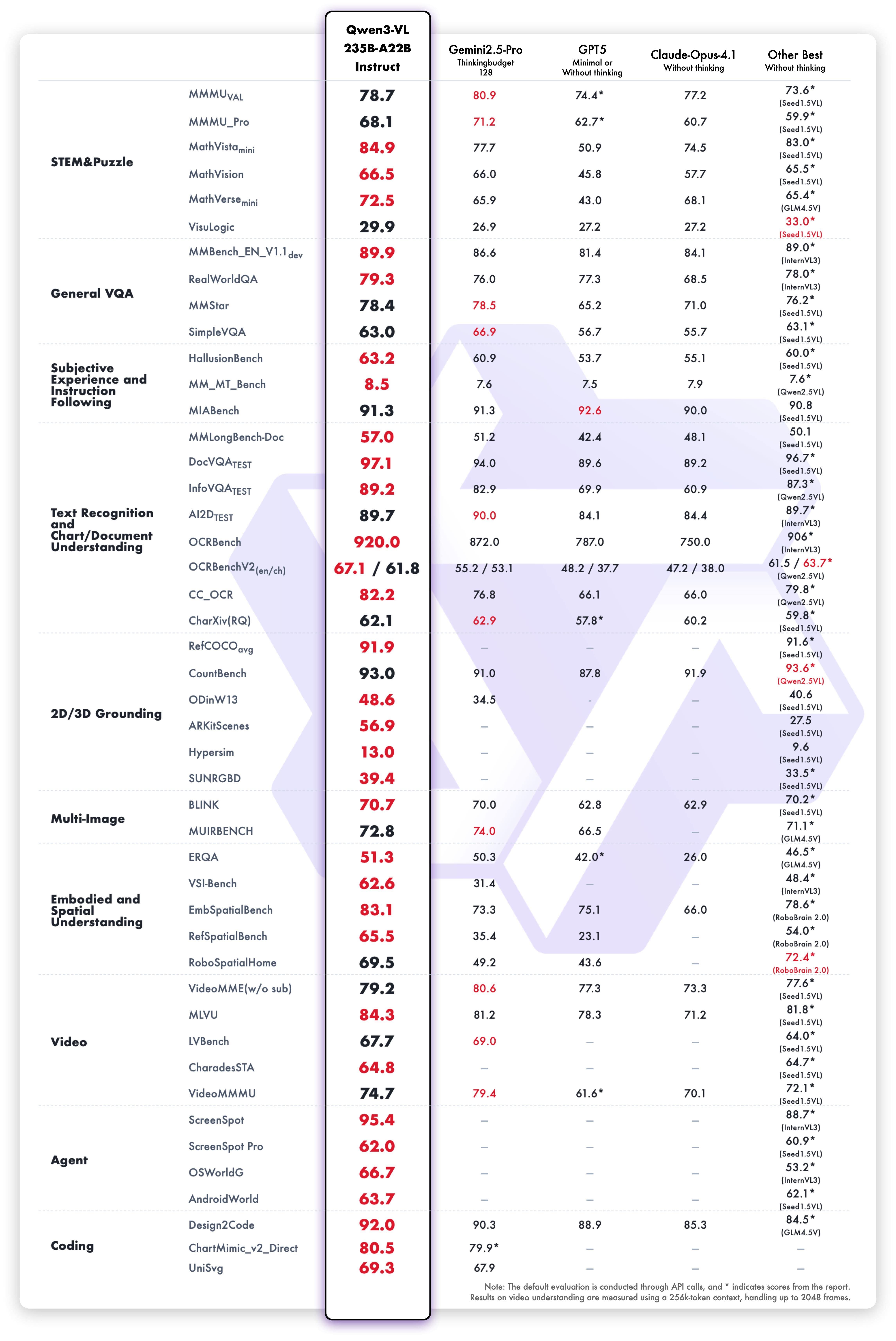
Qwen3-VL-235B-A22B-Thinking je optimalizován pro STEM (věda, technologie, inženýrství, matematika) a matematické uvažování. Při složitých otázkách si všímá jemných detailů, rozkládá problémy, analyzuje příčiny a důsledky a poskytuje logické odpovědi podložené důkazy. V benchmarkách jako MathVision, MMMU a MathVista dosahuje silných výsledků, v některých případech překonává i Gemini 2.5 Pro.
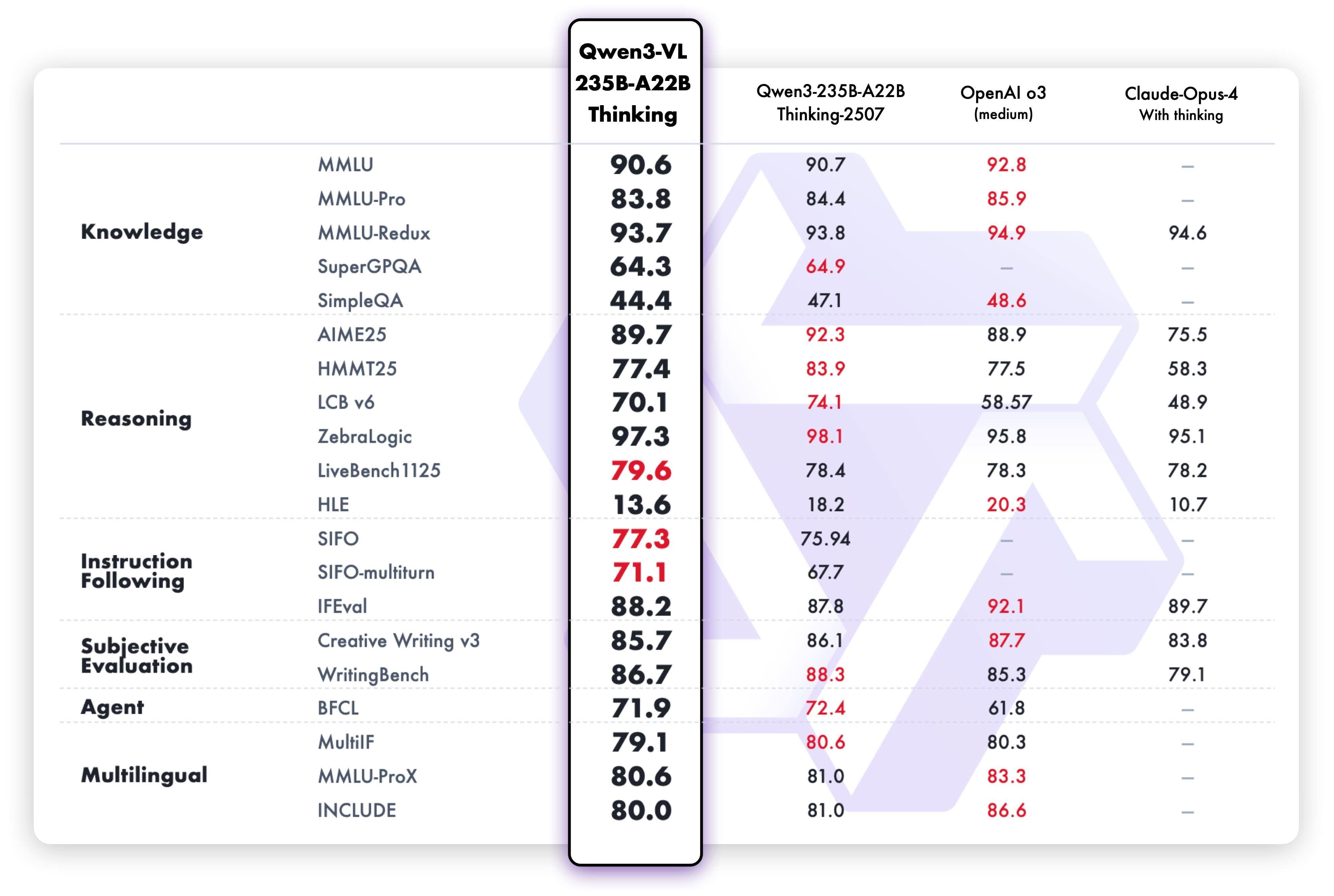
Klíčové vylepšení schopností
Qwen3-VL umí ovládat počítačové a mobilní rozhraní, rozpoznávat prvky grafického uživatelského rozhraní (GUI), chápat funkce tlačítek, volat nástroje a plnit úkoly. Dosahuje špičkových výsledků v benchmarku OS World, kde použití nástrojů zlepšuje výkon v jemném vnímání.
Model generuje kód z obrázků nebo videí, například převádí návrhové makety do formátů Draw.io, HTML, CSS nebo JavaScript, což umožňuje vizuální programování typu "co vidíte, to dostanete".
Všechny modely nativně podporují kontext 256K tokenů, rozšiřitelný až na 1 milion tokenů. To znamená, že lze zpracovat stovky stran technických dokumentů, celé učebnice nebo videa dlouhé dvě hodiny, přičemž model si pamatuje detaily a dokáže je přesně vyhledat, dokonce i na úrovni sekund ve videích.
Optická rozpoznávání znaků (OCR) nyní podporuje 32 jazyků, oproti původním 10, a funguje spolehlivěji v náročných podmínkách jako slabé osvětlení, rozmazání nebo nakloněný text. Zlepšila se přesnost rozpoznávání vzácných znaků, starověkých písem a technických termínů, stejně jako porozumění dlouhým dokumentům a rekonstrukce jemných struktur.
Díky ranému společnému předtrénování textu a vizuálních modalit model dosahuje textových schopností srovnatelných s modelem Qwen3-235B-A22B-2507. To z něj dělá textově založený multimodální model pro další generaci vizuálně-jazykových systémů.
Architektura a inovace
Architektura zachovává nativní design dynamického rozlišení, ale přináší aktualizace ve třech oblastech. První je Interleaved-MRoPE, kde se rozměry funkcí rozdělují střídavě podle času, výšky a šířky, což zajišťuje plné pokrytí frekvencí a zlepšuje porozumění dlouhým videím.
Druhá inovace je technologie DeepStack, která spojuje víceúrovňové prvky z ViT (Vision Transformer), zvyšuje zachycení vizuálních detailů a přesnost zarovnání textu a obrázků. Místo vkládání vizuálních tokenů jen do jedné vrstvy se nyní vkládají do více vrstev velkého jazykového modelu, což umožňuje jemnější vizuální porozumění.
Třetí vylepšení je mechanismus zarovnání textu a časových značek, který nahrazuje původní T-RoPE. Používá formát vstupu "časové značky - video snímky", což umožňuje jemnější zarovnání časových informací a vizuálního obsahu. Model nativně podporuje výstup v sekundách nebo formátu hodiny:minuty:sekundy, což zvyšuje přesnost lokalizace akcí a událostí ve videích.
Výkonnost v testech
V testu "jehla v kupce sena" s ultra dlouhými videi model dosáhl 100% přesnosti při délce kontextu 256K tokenů. Při rozšíření na 1M tokenů, ekvivalentních přibližně dvěma hodinám videa, přesnost zůstala na 99.5 %.
V testu vícejazyčného rozpoznávání textu mimo čínštinu a angličtinu model dosáhl přes 70% přesnosti v 32 z 39 jazyků, což ukazuje silnou generalizaci.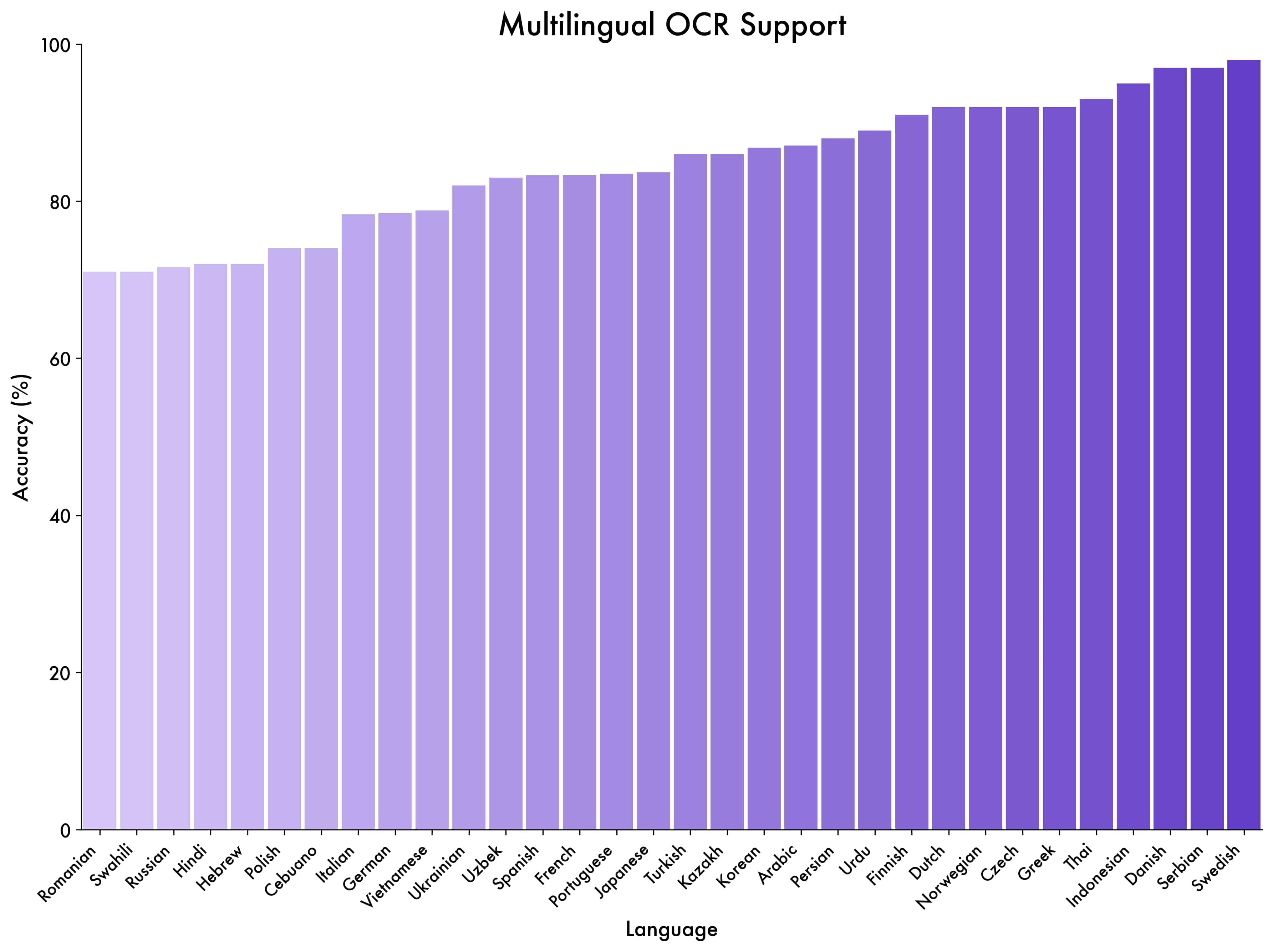
Qwen3-VL-235B-A22B-Instruct podporuje uvažování založené na obrázcích s použitím nástrojů. V testech čtyř úkolů jemnějšího vnímání a interakce došlo k konzistentnímu zlepšení výkonu, což potvrzuje, že kombinace analýzy obrázků a volání nástrojů zvyšuje vizuální schopnosti.
Další modely a dostupnost
Kromě vlajkového modelu jsou dostupné Qwen3-VL-4B a Qwen3-VL-8B ve verzích Instruct a Thinking, vhodné pro menší zařízení. Také Qwen3-VL-30B-A3B-Instruct a Qwen3-VL-30B-A3B-Thinking, plus verze v FP8 pro efektivní nasazení.
Modely jsou kompatibilní s Transformers a vLLM, podporují kvantizaci a akceleraci jako Flash-Attention 2. Pro vývojáře je k dispozici kód pro fine-tuning a cookbooks pro různé schopnosti, jako omni rozpoznávání, parsování dokumentů, 2D a 3D lokalizace, OCR, porozumění videím a agentní interakce.





