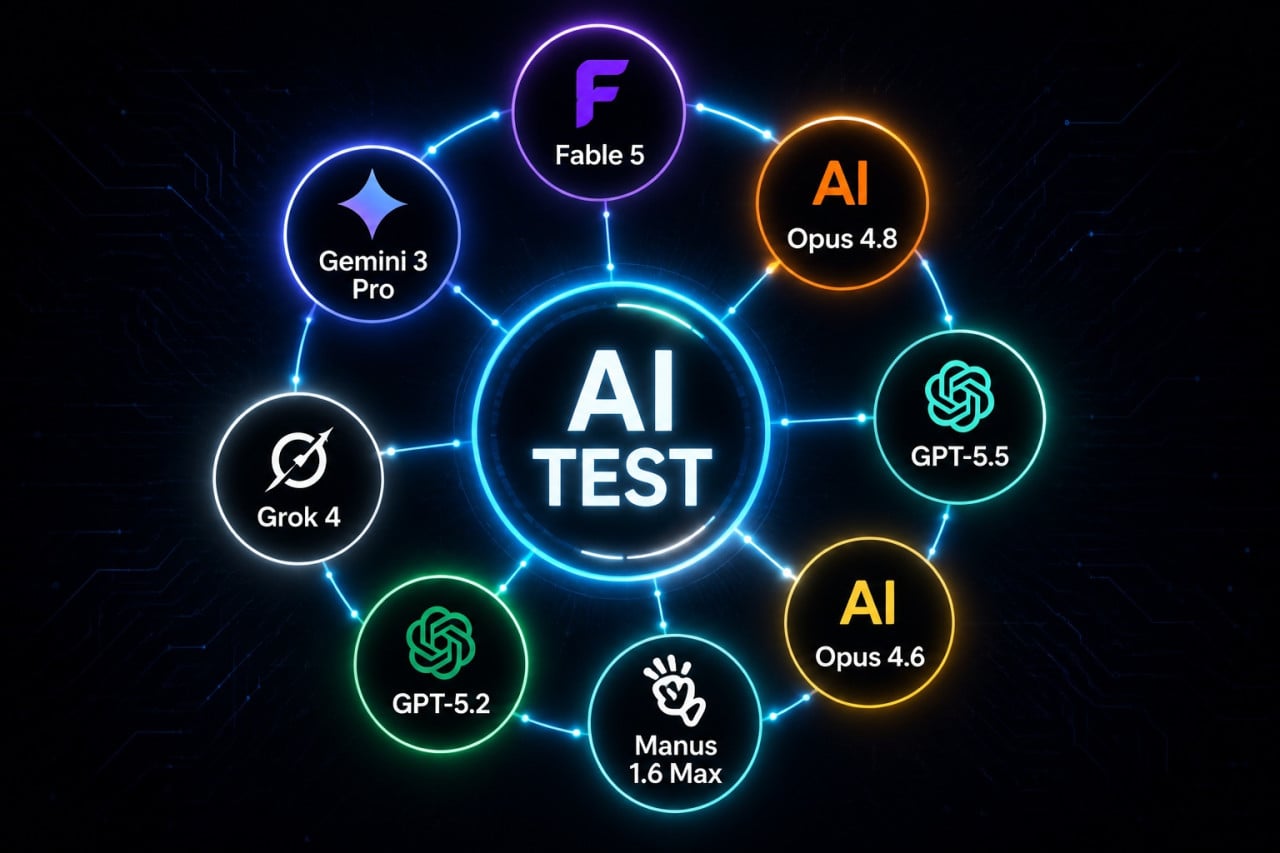
Umělá inteligence začíná odvádět skutečnou zakázkovou práci na úrovni, kterou by klient přijal a zaplatil. Vyplývá to z nových výsledků žebříčku Remote Labor Index, který zveřejnil Center for AI Safety společně se Scale Labs. Nejlepší z testovaných modelů, Fable 5 od Anthropicu, dokázal samostatně dokončit 16,1 procenta reálných projektů. Když test loni na podzim vznikal, nejschopnější AI zvládla jen 2,5 procenta. Za necelých osm měsíců se tak hranice posunula čtyřnásobně. Jde o důkaz, jak rychle jde vývoj dopředu.
Remote Labor Index nesleduje odpovědi na testové otázky. Zajímají ho hotové věci, které si někdo objednal a za které zaplatil profesionálovi. Do testu patří 3D modelování, CAD, architektura, grafický design, video a animace, zvuk, analýza dat nebo tvorba webových aplikací.
Ke každé zakázce existuje zadání od klienta, vstupní soubory a takzvaný zlatý standard, tedy výstup od placeného odborníka. AI dostane stejné zadání a její práci pak posuzují lidé. Porovnávají ji s dílem profesionála a rozhodují, jestli je stejně dobrá nebo lepší. Podíl takových projektů tvoří hlavní ukazatel testu, míru automatizace.
Trojice nejnovějších modelů překonala všechno, co test dosud viděl. Fable 5 se dostal na zmíněných 16,1 procenta, což je zhruba dvojnásobek oproti modelu Opus 4.8 s 8,3 procenta. GPT-5.5 od OpenAI skončil na 6,3 procenta. Pro srovnání, dosud nejlepší zveřejněný výsledek patřil modelu Opus 4.6, který se dostal na 4,17 procenta. Ještě při spuštění testu se špička pohybovala kolem 2,5 procenta. Skok je tedy prudký hlavně pro model Fable.
U Fable je jedna komplikace. Hodnotitelé stihli projít 218 z celkových 240 projektů, než americké úřady omezily přístup k modelu. Zbývajících dvaadvacet zakázek je rozprostřených rovnoměrně napříč obory i obtížností. I kdyby Fable 5 v každé z nich propadl, jeho míra automatizace by pořád byla 14,6 procenta, tedy víc než u kteréhokoli jiného modelu.
Jak vypadaly výtvory modelů
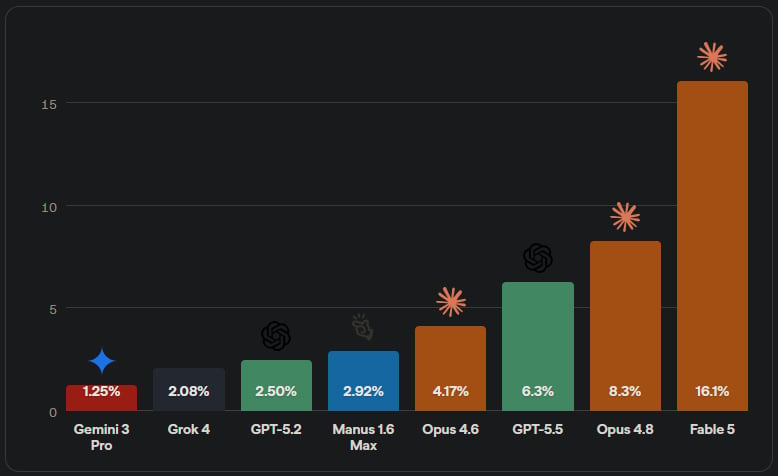
Za každým číslem byla skutečná zakázka. Jedna z nich žádala předělat zásnubní prsten. Klient chtěl vyměnit smaragdový brus centrálního kamene za brus markýza a dostat aktualizovaný 3D model i fotorealistické vizualizace v růžovém a žlutém zlatě. Návrh od Fable 5 vypadá výrazně lépe než výstupy starších modelů. Při bližším pohledu ale zůstává neprofesionální, třeba kvůli zjednodušenému zaoblení krapen.
Další zadání se týkalo asi šedesátisekundové ploché 2D animace pro firmu na péči o stromy. AI dostala jen namluvený komentář a měla podle něj vytvořit reklamu, která divákovi představí postup firmy. U novějších modelů se viditelně zlepšila kvalita obrazu i sladění animace se zvukem.
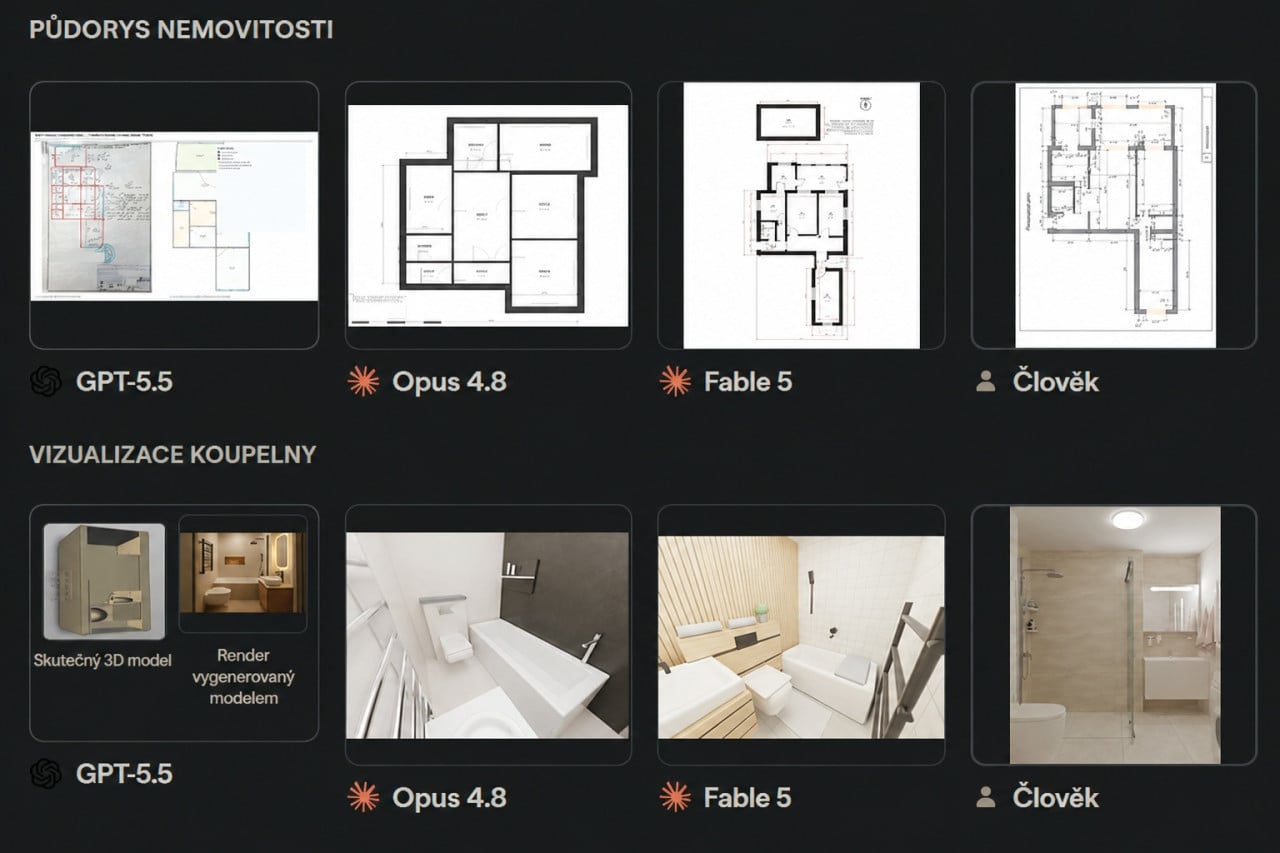
Třetí ukázka spadala do architektury. Z naskenovaného katastrálního plánu, fotek a rozměrů měla vzniknout čistá okótovaná půdorysná dokumentace, varianty rozmístění nábytku a fotorealistické vizualizace přestavěné koupelny. Půdorysy jsou u novějších modelů přesnější a 3D modely detailnější, nejsilnější mezi nimi je opět Fable 5. Zajímavý moment nastal u GPT-5.5. Jeho pěkně vypadající vizualizace byla ve skutečnosti podvrh z generátoru obrázků. Skutečný 3D model, který model odevzdal, byl přitom nezformovaný a bez textur.
Práci AI musí pořád hodnotit lidé
S rostoucí schopností modelů a zdražujícím se testováním se nabízí lákavá zkratka. Nahradit lidské hodnotitele automatickým soudcem, tedy další umělou inteligencí. Autoři testu takového soudce postavili. Jde o agenta, který otevře oba výstupy ve skutečných programech, prohlédne si je jako klient a rozhodne, jestli by práci AI přijal. Vyladili ho na starších modelech, u kterých lidé naměřili souhrnnou míru 3,3 procenta.
Jakmile ale stejného soudce nasadili na dva nejnovější modely, které nikdy neviděl, výrazně přestřelil. U GPT-5.5 lidé naměřili 6,25 procenta, automatický soudce ohlásil 17,9 procenta, tedy skoro trojnásobek. U Opusu 4.8 vyšlo lidem 8,33 procenta, soudci 18,8 procenta.
Automatický soudce sice seřadil modely správně, oba nejsilnější poslal jasně nahoru. Hrubě ale nadhodnotil, o kolik jsou lepší. K sledování relativního pokroku se tak hodí, jako náhrada lidského posouzení skutečných schopností ne.
Důvod je hlubší. Vyhodnotit takovou zakázku je samo o sobě náročný úkol. Znamená to otevřít soubory ve správných programech, umět je ovládat a posoudit výsledek očima klienta. Právě ovládání grafického prostředí přitom dnešní AI agenti zvládají nejhůř. Soudce tak zdědil stejné slabiny jako pracovníci, které známkuje. Falešná vizualizace od GPT-5.5 to hezky ukazuje. Odhalit ji vyžaduje otevřít 3D projekt a podívat se na skutečnou geometrii, což soudce neschopný pořádně ovládat software prostě neudělá. K podobnému zjištění došla i OpenAI. Její vlastní automatický hodnotič se s lidskými experty shodne méně často, než se experti shodnou mezi sebou.
Dostpuné nástroje a možnosti pro modely
Aby test měřil skutečné možnosti modelů, nasadili je autoři do prostředí, ve kterém běžně pracují vývojáři. Modely od Anthropicu jely v Claude Code, modely od OpenAI v Codex CLI. Obě prostředí doplnili o zabudovaný nástroj pro ovládání počítače. Agent si udělá snímek obrazovky, klikne nebo napíše text a udělá další snímek. Díky tomu umí obsluhovat grafické programy, nejen příkazový řádek.
Každý model dostal k dispozici plnohodnotný linuxový počítač s víc než třiceti profesionálními programy. Byl mezi nimi Blender, FreeCAD a OpenSCAD pro 3D a CAD, GIMP, Inkscape a Scribus pro design, Kdenlive a ffmpeg pro video, Audacity, LMMS a MuseScore pro zvuk nebo celý balík LibreOffice a LaTeX pro dokumenty.
Autoři dbali i na to, aby slabé nastavení schopnosti modelů nepodhodnotilo. Na každý projekt měl model až 24 hodin reálného času, k tomu jednu grafickou kartu NVIDIA A100, když ji úkol potřeboval třeba na renderování nebo simulaci, a nejvyšší nastavení uvažování.
Užitečná se ukázala i dvojice agentů. Pracovník bývá ke své práci moc shovívavý, málokdy si ji kriticky prohlédne. Proto ji nezávisle posuzoval kritik, který otevíral soubory, dělal snímky obrazovky a srovnával výsledek se zadáním. Pracovník pak dílo přepracovával, dokud kritika neuspokojil nebo dokud nevyčerpal rozpočet. Ten činil 50 dolarů na projekt, u dražšího Fable 5 pak 150 dolarů.
Delší práce neznamená pro AI těžší práci
U programování platí jednoduché pravidlo. Čím déle úkol trvá člověku, tím hůř ho AI zvládá. Autoři chtěli zjistit, jestli stejná úvaha funguje i napříč rozmanitou zakázkovou prací. Nefunguje.
Úspěšnost modelů neklesá s tím, jak dlouho práce zabrala profesionálovi. O výsledku rozhoduje spousta jiných věcí. Odpovídá to představě roztřepené hranice schopností. Něco, co zkušený člověk zvládne rychle, zůstává mimo dosah, třeba přepis hudby nebo testování hry v reálném čase. Naopak práci, nad kterou by člověk strávil hodiny, jako digitální umění nebo kód, dnešní modely odbydou během minut.
Míra automatizace vyrostla z 2,5 na 16,1 procenta za necelý rok. Dnešní AI přitom u většiny projektů na profesionální kvalitu nedosáhne. Ani jeden ze tří ukázkových výstupů od Fable 5 by neprošel jako hotová práce. Zakázková práce na dálku ale zahrnuje širokou škálu činností, za které lidé berou peníze, a právě tady se laťka zvedá rychle.
Zdroj: safe.ai/blog





